 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaMM: Semi-Supervised Pre-Training of Large-Scale Materials Models
May 28, 2025Neural network potentials (NNPs) are crucial for accelerating computational materials science by surrogating density functional theory (DFT) calculations. Improving their accuracy is possible through pre-training and fine-tuning, where an NNP model is first pre-trained on a large-scale dataset and then fine-tuned on a smaller target dataset. However, this approach is computationally expensive, mainly due to the cost of DFT-based dataset labeling and load imbalances during large-scale pre-training. To address this, we propose LaMM, a semi-supervised pre-training method incorporating improved denoising self-supervised learning and a load-balancing algorithm for efficient multi-node training. We demonstrate that our approach effectively leverages a large-scale dataset of $\sim$300 million semi-labeled samples to train a single NNP model, resulting in improved fine-tuning performance in terms of both speed and accuracy.
The Case for Strong Scaling in Deep Learning: Training Large 3D CNNs with Hybrid Parallelism
Jul 25, 2020We present scalable hybrid-parallel algorithms for training large-scale 3D convolutional neural networks. Deep learning-based emerging scientific workflows often require model training with large, high-dimensional samples, which can make training much more costly and even infeasible due to excessive memory usage. We solve these challenges by extensively applying hybrid parallelism throughout the end-to-end training pipeline, including both computations and I/O. Our hybrid-parallel algorithm extends the standard data parallelism with spatial parallelism, which partitions a single sample in the spatial domain, realizing strong scaling beyond the mini-batch dimension with a larger aggregated memory capacity. We evaluate our proposed training algorithms with two challenging 3D CNNs, CosmoFlow and 3D U-Net. Our comprehensive performance studies show that good weak and strong scaling can be achieved for both networks using up 2K GPUs. More importantly, we enable training of CosmoFlow with much larger samples than previously possible, realizing an order-of-magnitude improvement in prediction accuracy.
μ-cuDNN: Accelerating Deep Learning Frameworks with Micro-Batching
Apr 13, 2018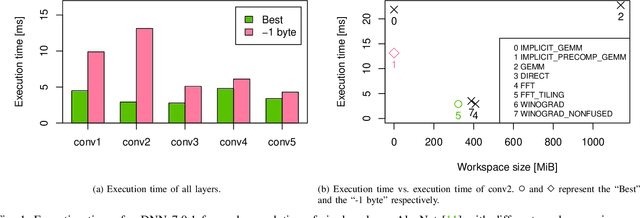
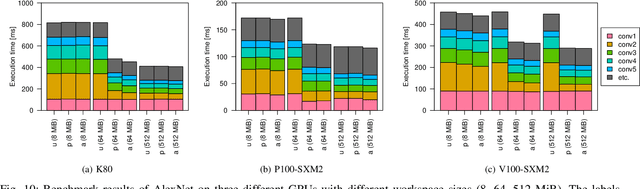
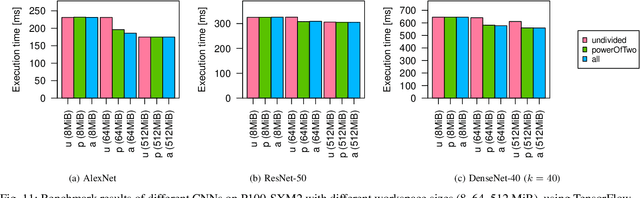
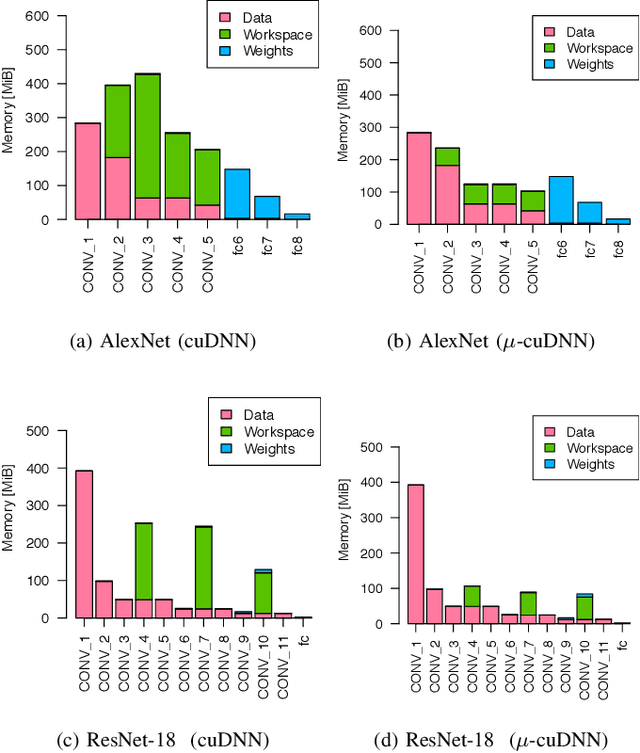
NVIDIA cuDNN is a low-level library that provides GPU kernels frequently used in deep learning. Specifically, cuDNN implements several equivalent convolution algorithms, whose performance and memory footprint may vary considerably, depending on the layer dimensions. When an algorithm is automatically selected by cuDNN, the decision is performed on a per-layer basis, and thus it often resorts to slower algorithms that fit the workspace size constraints. We present {\mu}-cuDNN, a transparent wrapper library for cuDNN, which divides layers' mini-batch computation into several micro-batches. Based on Dynamic Programming and Integer Linear Programming, {\mu}-cuDNN enables faster algorithms by decreasing the workspace requirements. At the same time, {\mu}-cuDNN keeps the computational semantics unchanged, so that it decouples statistical efficiency from the hardware efficiency safely. We demonstrate the effectiveness of {\mu}-cuDNN over two frameworks, Caffe and TensorFlow, achieving speedups of 1.63x for AlexNet and 1.21x for ResNet-18 on P100-SXM2 GPU. These results indicate that using micro-batches can seamlessly increase the performance of deep learning, while maintaining the same memory footprint.