 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Apr 14, 2026We describe the pre-training, post-training, and quantization of Nemotron 3 Super, a 120 billion (active 12 billion) parameter hybrid Mamba-Attention Mixture-of-Experts model. Nemotron 3 Super is the first model in the Nemotron 3 family to 1) be pre-trained in NVFP4, 2) leverage LatentMoE, a new Mixture-of-Experts architecture that optimizes for both accuracy per FLOP and accuracy per parameter, and 3) include MTP layers for inference acceleration through native speculative decoding. We pre-trained Nemotron 3 Super on 25 trillion tokens followed by post-training using supervised fine tuning (SFT) and reinforcement learning (RL). The final model supports up to 1M context length and achieves comparable accuracy on common benchmarks, while also achieving up to 2.2x and 7.5x higher inference throughput compared to GPT-OSS-120B and Qwen3.5-122B, respectively. Nemotron 3 Super datasets, along with the base, post-trained, and quantized checkpoints, are open-sourced on HuggingFace.
NVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model
Aug 21, 2025



We introduce Nemotron-Nano-9B-v2, a hybrid Mamba-Transformer language model designed to increase throughput for reasoning workloads while achieving state-of-the-art accuracy compared to similarly-sized models. Nemotron-Nano-9B-v2 builds on the Nemotron-H architecture, in which the majority of the self-attention layers in the common Transformer architecture are replaced with Mamba-2 layers, to achieve improved inference speed when generating the long thinking traces needed for reasoning. We create Nemotron-Nano-9B-v2 by first pre-training a 12-billion-parameter model (Nemotron-Nano-12B-v2-Base) on 20 trillion tokens using an FP8 training recipe. After aligning Nemotron-Nano-12B-v2-Base, we employ the Minitron strategy to compress and distill the model with the goal of enabling inference on up to 128k tokens on a single NVIDIA A10G GPU (22GiB of memory, bfloat16 precision). Compared to existing similarly-sized models (e.g., Qwen3-8B), we show that Nemotron-Nano-9B-v2 achieves on-par or better accuracy on reasoning benchmarks while achieving up to 6x higher inference throughput in reasoning settings like 8k input and 16k output tokens. We are releasing Nemotron-Nano-9B-v2, Nemotron-Nano12B-v2-Base, and Nemotron-Nano-9B-v2-Base checkpoints along with the majority of our pre- and post-training datasets on Hugging Face.
Learning Interpretable Models Through Multi-Objective Neural Architecture Search
Dec 16, 2021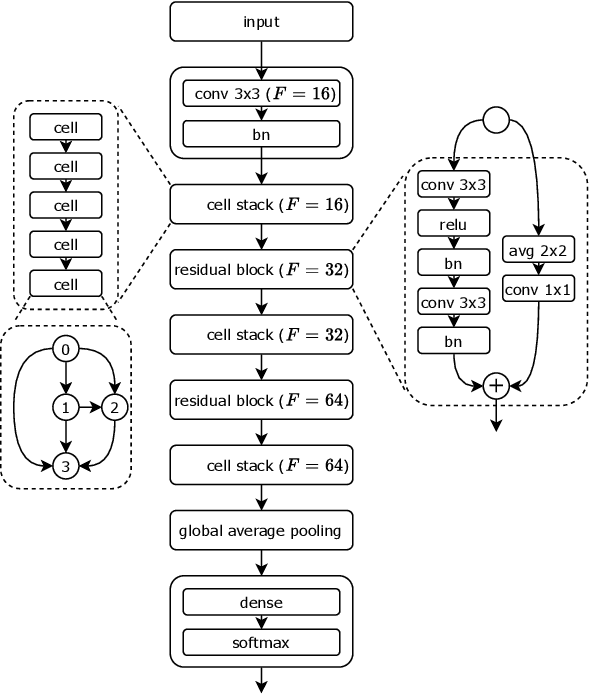
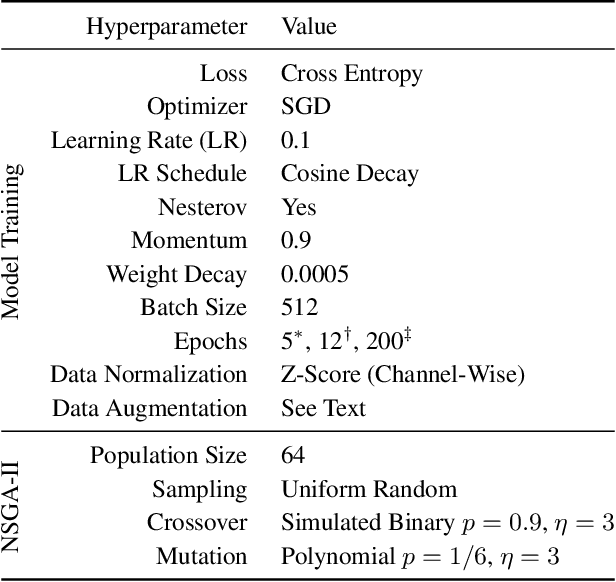
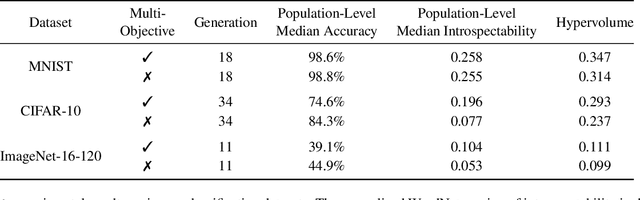
Monumental advances in deep learning have led to unprecedented achievements across a multitude of domains. While the performance of deep neural networks is indubitable, the architectural design and interpretability of such models are nontrivial. Research has been introduced to automate the design of neural network architectures through neural architecture search (NAS). Recent progress has made these methods more pragmatic by exploiting distributed computation and novel optimization algorithms. However, there is little work in optimizing architectures for interpretability. To this end, we propose a multi-objective distributed NAS framework that optimizes for both task performance and introspection. We leverage the non-dominated sorting genetic algorithm (NSGA-II) and explainable AI (XAI) techniques to reward architectures that can be better comprehended by humans. The framework is evaluated on several image classification datasets. We demonstrate that jointly optimizing for introspection ability and task error leads to more disentangled architectures that perform within tolerable error.
Parallelizing Training of Deep Generative Models on Massive Scientific Datasets
Oct 05, 2019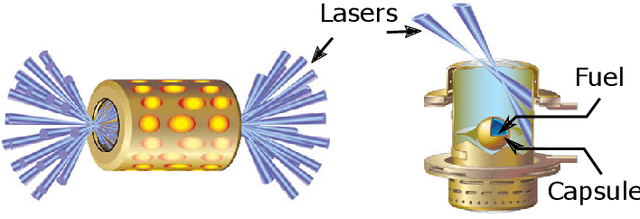
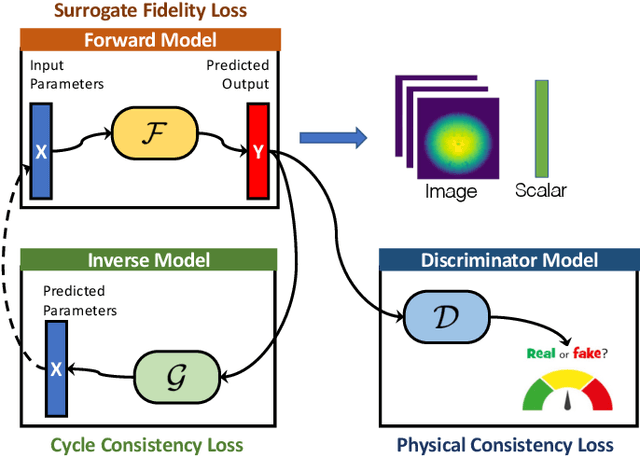
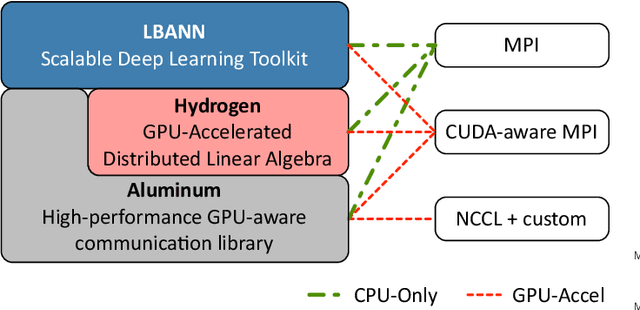
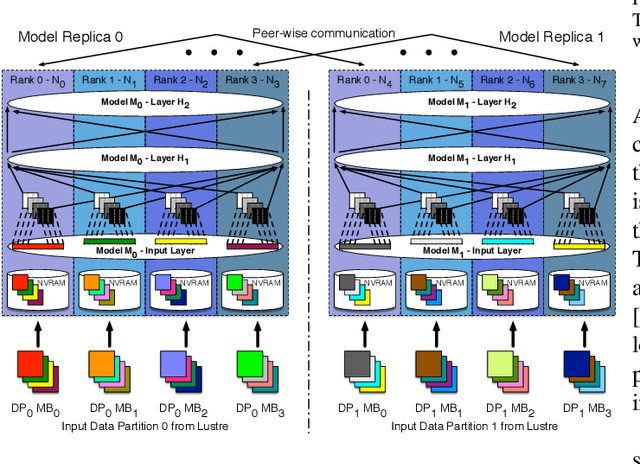
Training deep neural networks on large scientific data is a challenging task that requires enormous compute power, especially if no pre-trained models exist to initialize the process. We present a novel tournament method to train traditional as well as generative adversarial networks built on LBANN, a scalable deep learning framework optimized for HPC systems. LBANN combines multiple levels of parallelism and exploits some of the worlds largest supercomputers. We demonstrate our framework by creating a complex predictive model based on multi-variate data from high-energy-density physics containing hundreds of millions of images and hundreds of millions of scalar values derived from tens of millions of simulations of inertial confinement fusion. Our approach combines an HPC workflow and extends LBANN with optimized data ingestion and the new tournament-style training algorithm to produce a scalable neural network architecture using a CORAL-class supercomputer. Experimental results show that 64 trainers (1024 GPUs) achieve a speedup of 70.2 over a single trainer (16 GPUs) baseline, and an effective 109% parallel efficiency.
Improving Strong-Scaling of CNN Training by Exploiting Finer-Grained Parallelism
Mar 15, 2019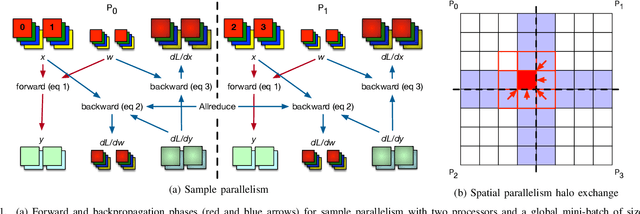
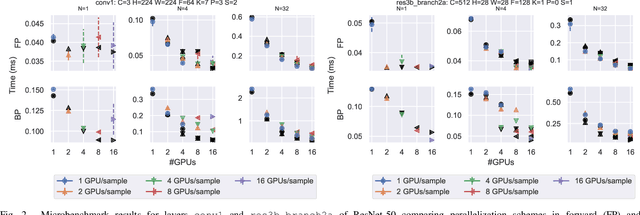
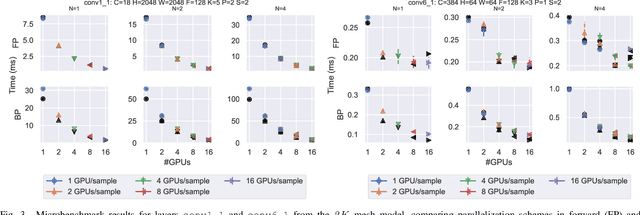
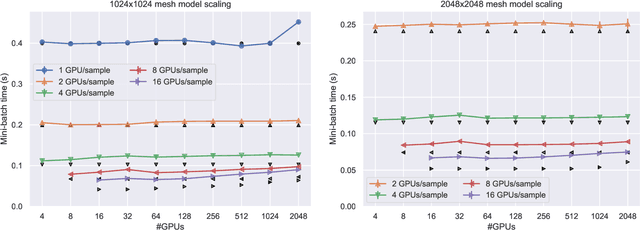
Scaling CNN training is necessary to keep up with growing datasets and reduce training time. We also see an emerging need to handle datasets with very large samples, where memory requirements for training are large. Existing training frameworks use a data-parallel approach that partitions samples within a mini-batch, but limits to scaling the mini-batch size and memory consumption makes this untenable for large samples. We describe and implement new approaches to convolution, which parallelize using spatial decomposition or a combination of sample and spatial decomposition. This introduces many performance knobs for a network, so we develop a performance model for CNNs and present a method for using it to automatically determine efficient parallelization strategies. We evaluate our algorithms with microbenchmarks and image classification with ResNet-50. Our algorithms allow us to prototype a model for a mesh-tangling dataset, where sample sizes are very large. We show that our parallelization achieves excellent strong and weak scaling and enables training for previously unreachable datasets.