 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Cross-Channel Hierarchical Aggregation for Foundation Models
Jun 26, 2025Vision-based scientific foundation models hold significant promise for advancing scientific discovery and innovation. This potential stems from their ability to aggregate images from diverse sources such as varying physical groundings or data acquisition systems and to learn spatio-temporal correlations using transformer architectures. However, tokenizing and aggregating images can be compute-intensive, a challenge not fully addressed by current distributed methods. In this work, we introduce the Distributed Cross-Channel Hierarchical Aggregation (D-CHAG) approach designed for datasets with a large number of channels across image modalities. Our method is compatible with any model-parallel strategy and any type of vision transformer architecture, significantly improving computational efficiency. We evaluated D-CHAG on hyperspectral imaging and weather forecasting tasks. When integrated with tensor parallelism and model sharding, our approach achieved up to a 75% reduction in memory usage and more than doubled sustained throughput on up to 1,024 AMD GPUs on the Frontier Supercomputer.
Balanced and Elastic End-to-end Training of Dynamic LLMs
May 20, 2025To reduce computational and memory costs in Large Language Models (LLMs), dynamic workload reduction schemes like Mixture of Experts (MoEs), parameter pruning, layer freezing, sparse attention, early token exit, and Mixture of Depths (MoDs) have emerged. However, these methods introduce severe workload imbalances, limiting their practicality for large-scale distributed training. We propose DynMo, an autonomous dynamic load balancing solution that ensures optimal compute distribution when using pipeline parallelism in training dynamic models. DynMo adaptively balances workloads, dynamically packs tasks into fewer workers to free idle resources, and supports both multi-GPU single-node and multi-node systems. Compared to static training methods (Megatron-LM, DeepSpeed), DynMo accelerates training by up to 1.23x (MoEs), 3.18x (pruning), 2.23x (layer freezing), 4.02x (sparse attention), 4.52x (early exit), and 1.17x (MoDs). DynMo is available at https://anonymous.4open.science/r/DynMo-4D04/.
Think Before You Attribute: Improving the Performance of LLMs Attribution Systems
May 19, 2025



Large Language Models (LLMs) are increasingly applied in various science domains, yet their broader adoption remains constrained by a critical challenge: the lack of trustworthy, verifiable outputs. Current LLMs often generate answers without reliable source attribution, or worse, with incorrect attributions, posing a barrier to their use in scientific and high-stakes settings, where traceability and accountability are non-negotiable. To be reliable, attribution systems need high accuracy and retrieve data with short lengths, i.e., attribute to a sentence within a document rather than a whole document. We propose a sentence-level pre-attribution step for Retrieve-Augmented Generation (RAG) systems that classify sentences into three categories: not attributable, attributable to a single quote, and attributable to multiple quotes. By separating sentences before attribution, a proper attribution method can be selected for the type of sentence, or the attribution can be skipped altogether. Our results indicate that classifiers are well-suited for this task. In this work, we propose a pre-attribution step to reduce the computational complexity of attribution, provide a clean version of the HAGRID dataset, and provide an end-to-end attribution system that works out of the box.
ORBIT-2: Scaling Exascale Vision Foundation Models for Weather and Climate Downscaling
May 07, 2025



Sparse observations and coarse-resolution climate models limit effective regional decision-making, underscoring the need for robust downscaling. However, existing AI methods struggle with generalization across variables and geographies and are constrained by the quadratic complexity of Vision Transformer (ViT) self-attention. We introduce ORBIT-2, a scalable foundation model for global, hyper-resolution climate downscaling. ORBIT-2 incorporates two key innovations: (1) Residual Slim ViT (Reslim), a lightweight architecture with residual learning and Bayesian regularization for efficient, robust prediction; and (2) TILES, a tile-wise sequence scaling algorithm that reduces self-attention complexity from quadratic to linear, enabling long-sequence processing and massive parallelism. ORBIT-2 scales to 10 billion parameters across 32,768 GPUs, achieving up to 1.8 ExaFLOPS sustained throughput and 92-98% strong scaling efficiency. It supports downscaling to 0.9 km global resolution and processes sequences up to 4.2 billion tokens. On 7 km resolution benchmarks, ORBIT-2 achieves high accuracy with R^2 scores in the range of 0.98 to 0.99 against observation data.
Tadashi: Enabling AI-Based Automated Code Generation With Guaranteed Correctness
Oct 04, 2024



Frameworks and DSLs auto-generating code have traditionally relied on human experts developing them to have in place rigorous methods to assure the legality of the applied code transformations. Machine Learning (ML) is gaining wider adoption as a means to auto-generate code optimised for the hardware target. However, ML solutions, and in particular black-box DNNs, provide no such guarantees on legality. In this paper we propose a library, Tadashi, which leverages the polyhedral model to empower researchers seeking to curate datasets crucial for applying ML in code-generation. Tadashi provides the ability to reliably and practically check the legality of candidate transformations on polyhedral schedules applied on a baseline reference code. We provide a proof that our library guarantees the legality of generated transformations, and demonstrate its lightweight practical cost. Tadashi is available at https://github.com/vatai/tadashi/.
A Pairwise Comparison Relation-assisted Multi-objective Evolutionary Neural Architecture Search Method with Multi-population Mechanism
Jul 22, 2024Neural architecture search (NAS) enables re-searchers to automatically explore vast search spaces and find efficient neural networks. But NAS suffers from a key bottleneck, i.e., numerous architectures need to be evaluated during the search process, which requires a lot of computing resources and time. In order to improve the efficiency of NAS, a series of methods have been proposed to reduce the evaluation time of neural architectures. However, they are not efficient enough and still only focus on the accuracy of architectures. In addition to the classification accuracy, more efficient and smaller network architectures are required in real-world applications. To address the above problems, we propose the SMEM-NAS, a pairwise com-parison relation-assisted multi-objective evolutionary algorithm based on a multi-population mechanism. In the SMEM-NAS, a surrogate model is constructed based on pairwise compari-son relations to predict the accuracy ranking of architectures, rather than the absolute accuracy. Moreover, two populations cooperate with each other in the search process, i.e., a main population guides the evolution, while a vice population expands the diversity. Our method aims to provide high-performance models that take into account multiple optimization objectives. We conduct a series of experiments on the CIFAR-10, CIFAR-100 and ImageNet datasets to verify its effectiveness. With only a single GPU searching for 0.17 days, competitive architectures can be found by SMEM-NAS which achieves 78.91% accuracy with the MAdds of 570M on the ImageNet. This work makes a significant advance in the important field of NAS.
Adaptive Patching for High-resolution Image Segmentation with Transformers
Apr 15, 2024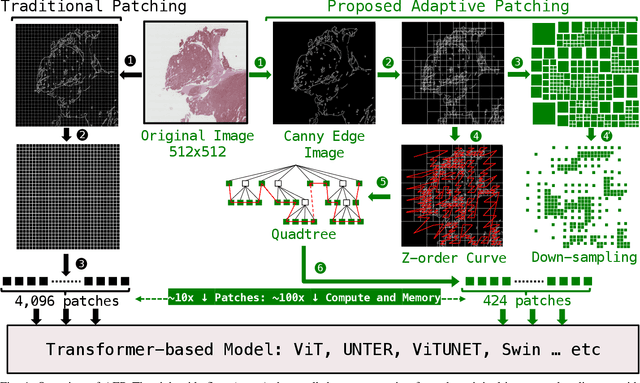



Attention-based models are proliferating in the space of image analytics, including segmentation. The standard method of feeding images to transformer encoders is to divide the images into patches and then feed the patches to the model as a linear sequence of tokens. For high-resolution images, e.g. microscopic pathology images, the quadratic compute and memory cost prohibits the use of an attention-based model, if we are to use smaller patch sizes that are favorable in segmentation. The solution is to either use custom complex multi-resolution models or approximate attention schemes. We take inspiration from Adapative Mesh Refinement (AMR) methods in HPC by adaptively patching the images, as a pre-processing step, based on the image details to reduce the number of patches being fed to the model, by orders of magnitude. This method has a negligible overhead, and works seamlessly with any attention-based model, i.e. it is a pre-processing step that can be adopted by any attention-based model without friction. We demonstrate superior segmentation quality over SoTA segmentation models for real-world pathology datasets while gaining a geomean speedup of $6.9\times$ for resolutions up to $64K^2$, on up to $2,048$ GPUs.
Adapting CSI-Guided Imaging Across Diverse Environments: An Experimental Study Leveraging Continuous Learning
Apr 01, 2024This study explores the feasibility of adapting CSI-guided imaging across varied environments. Focusing on continuous model learning through continuous updates, we investigate CSI-Imager's adaptability in dynamically changing settings, specifically transitioning from an office to an industrial environment. Unlike traditional approaches that may require retraining for new environments, our experimental study aims to validate the potential of CSI-guided imaging to maintain accurate imaging performance through Continuous Learning (CL). By conducting experiments across different scenarios and settings, this work contributes to understanding the limitations and capabilities of existing CSI-guided imaging systems in adapting to new environmental contexts.
Ultra-Long Sequence Distributed Transformer
Nov 08, 2023



Transformer models trained on long sequences often achieve higher accuracy than short sequences. Unfortunately, conventional transformers struggle with long sequence training due to the overwhelming computation and memory requirements. Existing methods for long sequence training offer limited speedup and memory reduction, and may compromise accuracy. This paper presents a novel and efficient distributed training method, the Long Short-Sequence Transformer (LSS Transformer), for training transformer with long sequences. It distributes a long sequence into segments among GPUs, with each GPU computing a partial self-attention for its segment. Then, it uses a fused communication and a novel double gradient averaging technique to avoid the need to aggregate partial self-attention and minimize communication overhead. We evaluated the performance between LSS Transformer and the state-of-the-art Nvidia sequence parallelism on a Wikipedia enwik8 dataset. Results show that our proposed method lead to 5.6x faster and 10.2x more memory-efficient implementation compared to state-of-the-art sequence parallelism on 144 Nvidia V100 GPUs. Moreover, our algorithm scales to an extreme sequence length of 50,112 at 3,456 GPUs, achieving 161% super-linear parallel efficiency and a throughput of 32 petaflops.
KAKURENBO: Adaptively Hiding Samples in Deep Neural Network Training
Oct 16, 2023



This paper proposes a method for hiding the least-important samples during the training of deep neural networks to increase efficiency, i.e., to reduce the cost of training. Using information about the loss and prediction confidence during training, we adaptively find samples to exclude in a given epoch based on their contribution to the overall learning process, without significantly degrading accuracy. We explore the converge properties when accounting for the reduction in the number of SGD updates. Empirical results on various large-scale datasets and models used directly in image classification and segmentation show that while the with-replacement importance sampling algorithm performs poorly on large datasets, our method can reduce total training time by up to 22% impacting accuracy only by 0.4% compared to the baseline. Code available at https://github.com/TruongThaoNguyen/kakurenbo