 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Open-Weight Large Language Models for Hydropower Regulatory Information Extraction: A Systematic Analysis
Nov 14, 2025Information extraction from regulatory documents using large language models presents critical trade-offs between performance and computational resources. We evaluated seven open-weight models (0.6B-70B parameters) on hydropower licensing documentation to provide empirical deployment guidance. Our analysis identified a pronounced 14B parameter threshold where validation methods transition from ineffective (F1 $<$ 0.15) to viable (F1 = 0.64). Consumer-deployable models achieve 64\% F1 through appropriate validation, while smaller models plateau at 51\%. Large-scale models approach 77\% F1 but require enterprise infrastructure. We identified systematic hallucination patterns where perfect recall indicates extraction failure rather than success in smaller models. Our findings establish the first comprehensive resource-performance mapping for open-weight information extraction in regulatory contexts, enabling evidence-based model selection. These results provide immediate value for hydropower compliance while contributing insights into parameter scaling effects that generalize across information extraction tasks.
OFCnetLLM: Large Language Model for Network Monitoring and Alertness
Jul 30, 2025The rapid evolution of network infrastructure is bringing new challenges and opportunities for efficient network management, optimization, and security. With very large monitoring databases becoming expensive to explore, the use of AI and Generative AI can help reduce costs of managing these datasets. This paper explores the use of Large Language Models (LLMs) to revolutionize network monitoring management by addressing the limitations of query finding and pattern analysis. We leverage LLMs to enhance anomaly detection, automate root-cause analysis, and automate incident analysis to build a well-monitored network management team using AI. Through a real-world example of developing our own OFCNetLLM, based on the open-source LLM model, we demonstrate practical applications of OFCnetLLM in the OFC conference network. Our model is developed as a multi-agent approach and is still evolving, and we present early results here.
ORBIT-2: Scaling Exascale Vision Foundation Models for Weather and Climate Downscaling
May 07, 2025



Sparse observations and coarse-resolution climate models limit effective regional decision-making, underscoring the need for robust downscaling. However, existing AI methods struggle with generalization across variables and geographies and are constrained by the quadratic complexity of Vision Transformer (ViT) self-attention. We introduce ORBIT-2, a scalable foundation model for global, hyper-resolution climate downscaling. ORBIT-2 incorporates two key innovations: (1) Residual Slim ViT (Reslim), a lightweight architecture with residual learning and Bayesian regularization for efficient, robust prediction; and (2) TILES, a tile-wise sequence scaling algorithm that reduces self-attention complexity from quadratic to linear, enabling long-sequence processing and massive parallelism. ORBIT-2 scales to 10 billion parameters across 32,768 GPUs, achieving up to 1.8 ExaFLOPS sustained throughput and 92-98% strong scaling efficiency. It supports downscaling to 0.9 km global resolution and processes sequences up to 4.2 billion tokens. On 7 km resolution benchmarks, ORBIT-2 achieves high accuracy with R^2 scores in the range of 0.98 to 0.99 against observation data.
Enhancing Diagnosis through AI-driven Analysis of Reflectance Confocal Microscopy
Apr 24, 2024
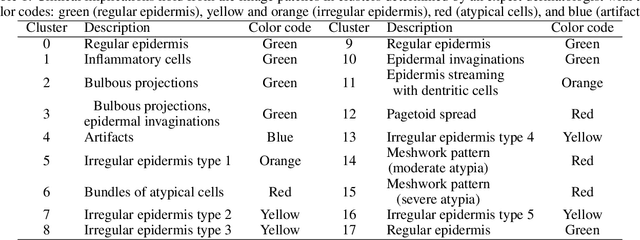
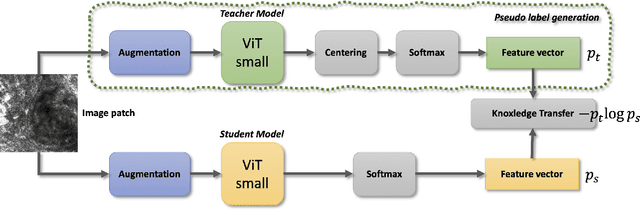
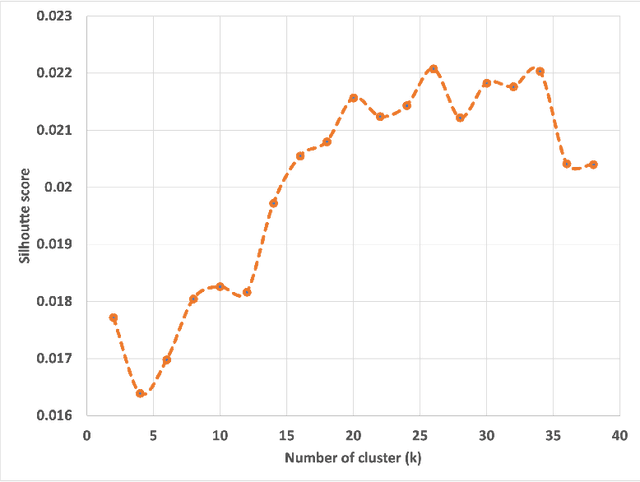
Reflectance Confocal Microscopy (RCM) is a non-invasive imaging technique used in biomedical research and clinical dermatology. It provides virtual high-resolution images of the skin and superficial tissues, reducing the need for physical biopsies. RCM employs a laser light source to illuminate the tissue, capturing the reflected light to generate detailed images of microscopic structures at various depths. Recent studies explored AI and machine learning, particularly CNNs, for analyzing RCM images. Our study proposes a segmentation strategy based on textural features to identify clinically significant regions, empowering dermatologists in effective image interpretation and boosting diagnostic confidence. This approach promises to advance dermatological diagnosis and treatment.
Ultra-Long Sequence Distributed Transformer
Nov 08, 2023



Transformer models trained on long sequences often achieve higher accuracy than short sequences. Unfortunately, conventional transformers struggle with long sequence training due to the overwhelming computation and memory requirements. Existing methods for long sequence training offer limited speedup and memory reduction, and may compromise accuracy. This paper presents a novel and efficient distributed training method, the Long Short-Sequence Transformer (LSS Transformer), for training transformer with long sequences. It distributes a long sequence into segments among GPUs, with each GPU computing a partial self-attention for its segment. Then, it uses a fused communication and a novel double gradient averaging technique to avoid the need to aggregate partial self-attention and minimize communication overhead. We evaluated the performance between LSS Transformer and the state-of-the-art Nvidia sequence parallelism on a Wikipedia enwik8 dataset. Results show that our proposed method lead to 5.6x faster and 10.2x more memory-efficient implementation compared to state-of-the-art sequence parallelism on 144 Nvidia V100 GPUs. Moreover, our algorithm scales to an extreme sequence length of 50,112 at 3,456 GPUs, achieving 161% super-linear parallel efficiency and a throughput of 32 petaflops.