 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStealthy Backdoor Attacks against LLMs Based on Natural Style Triggers
Apr 23, 2026The growing application of large language models (LLMs) in safety-critical domains has raised urgent concerns about their security. Many recent studies have demonstrated the feasibility of backdoor attacks against LLMs. However, existing methods suffer from three key shortcomings: explicit trigger patterns that compromise naturalness, unreliable injection of attacker-specified payloads in long-form generation, and incompletely specified threat models that obscure how backdoors are delivered and activated in practice. To address these gaps, we present BadStyle, a complete backdoor attack framework and pipeline. BadStyle leverages an LLM as a poisoned sample generator to construct natural and stealthy poisoned samples that carry imperceptible style-level triggers while preserving semantics and fluency. To stabilize payload injection during fine-tuning, we design an auxiliary target loss that reinforces the attacker-specified target content in responses to poisoned inputs and penalizes its emergence in benign responses. We further ground the attack in a realistic threat model and systematically evaluate BadStyle under both prompt-induced and PEFT-based injection strategies. Extensive experiments across seven victim LLMs, including LLaMA, Phi, DeepSeek, and GPT series, demonstrate that BadStyle achieves high attack success rates (ASRs) while maintaining strong stealthiness. The proposed auxiliary target loss substantially improves the stability of backdoor activation, yielding an average ASR improvement of around 30% across style-level triggers. Even in downstream deployment scenarios unknown during injection, the implanted backdoor remains effective. Moreover, BadStyle consistently evades representative input-level defenses and bypasses output-level defenses through simple camouflage.
ROMAN: Reward-Orchestrated Multi-Head Attention Network for Autonomous Driving System Testing
Feb 05, 2026Automated Driving System (ADS) acts as the brain of autonomous vehicles, responsible for their safety and efficiency. Safe deployment requires thorough testing in diverse real-world scenarios and compliance with traffic laws like speed limits, signal obedience, and right-of-way rules. Violations like running red lights or speeding pose severe safety risks. However, current testing approaches face significant challenges: limited ability to generate complex and high-risk law-breaking scenarios, and failing to account for complex interactions involving multiple vehicles and critical situations. To address these challenges, we propose ROMAN, a novel scenario generation approach for ADS testing that combines a multi-head attention network with a traffic law weighting mechanism. ROMAN is designed to generate high-risk violation scenarios to enable more thorough and targeted ADS evaluation. The multi-head attention mechanism models interactions among vehicles, traffic signals, and other factors. The traffic law weighting mechanism implements a workflow that leverages an LLM-based risk weighting module to evaluate violations based on the two dimensions of severity and occurrence. We have evaluated ROMAN by testing the Baidu Apollo ADS within the CARLA simulation platform and conducting extensive experiments to measure its performance. Experimental results demonstrate that ROMAN surpassed state-of-the-art tools ABLE and LawBreaker by achieving 7.91% higher average violation count than ABLE and 55.96% higher than LawBreaker, while also maintaining greater scenario diversity. In addition, only ROMAN successfully generated violation scenarios for every clause of the input traffic laws, enabling it to identify more high-risk violations than existing approaches.
Adaptive Graph Learning with Transformer for Multi-Reservoir Inflow Prediction
Nov 10, 2025Reservoir inflow prediction is crucial for water resource management, yet existing approaches mainly focus on single-reservoir models that ignore spatial dependencies among interconnected reservoirs. We introduce AdaTrip as an adaptive, time-varying graph learning framework for multi-reservoir inflow forecasting. AdaTrip constructs dynamic graphs where reservoirs are nodes with directed edges reflecting hydrological connections, employing attention mechanisms to automatically identify crucial spatial and temporal dependencies. Evaluation on thirty reservoirs in the Upper Colorado River Basin demonstrates superiority over existing baselines, with improved performance for reservoirs with limited records through parameter sharing. Additionally, AdaTrip provides interpretable attention maps at edge and time-step levels, offering insights into hydrological controls to support operational decision-making. Our code is available at https://github.com/humphreyhuu/AdaTrip.
RAG+: Enhancing Retrieval-Augmented Generation with Application-Aware Reasoning
Jun 13, 2025The integration of external knowledge through Retrieval-Augmented Generation (RAG) has become foundational in enhancing large language models (LLMs) for knowledge-intensive tasks. However, existing RAG paradigms often overlook the cognitive step of applying knowledge, leaving a gap between retrieved facts and task-specific reasoning. In this work, we introduce RAG+, a principled and modular extension that explicitly incorporates application-aware reasoning into the RAG pipeline. RAG+ constructs a dual corpus consisting of knowledge and aligned application examples, created either manually or automatically, and retrieves both jointly during inference. This design enables LLMs not only to access relevant information but also to apply it within structured, goal-oriented reasoning processes. Experiments across mathematical, legal, and medical domains, conducted on multiple models, demonstrate that RAG+ consistently outperforms standard RAG variants, achieving average improvements of 3-5%, and peak gains up to 7.5% in complex scenarios. By bridging retrieval with actionable application, RAG+ advances a more cognitively grounded framework for knowledge integration, representing a step toward more interpretable and capable LLMs.
On-Demand Scenario Generation for Testing Automated Driving Systems
May 20, 2025The safety and reliability of Automated Driving Systems (ADS) are paramount, necessitating rigorous testing methodologies to uncover potential failures before deployment. Traditional testing approaches often prioritize either natural scenario sampling or safety-critical scenario generation, resulting in overly simplistic or unrealistic hazardous tests. In practice, the demand for natural scenarios (e.g., when evaluating the ADS's reliability in real-world conditions), critical scenarios (e.g., when evaluating safety in critical situations), or somewhere in between (e.g., when testing the ADS in regions with less civilized drivers) varies depending on the testing objectives. To address this issue, we propose the On-demand Scenario Generation (OSG) Framework, which generates diverse scenarios with varying risk levels. Achieving the goal of OSG is challenging due to the complexity of quantifying the criticalness and naturalness stemming from intricate vehicle-environment interactions, as well as the need to maintain scenario diversity across various risk levels. OSG learns from real-world traffic datasets and employs a Risk Intensity Regulator to quantitatively control the risk level. It also leverages an improved heuristic search method to ensure scenario diversity. We evaluate OSG on the Carla simulators using various ADSs. We verify OSG's ability to generate scenarios with different risk levels and demonstrate its necessity by comparing accident types across risk levels. With the help of OSG, we are now able to systematically and objectively compare the performance of different ADSs based on different risk levels.
ORBIT-2: Scaling Exascale Vision Foundation Models for Weather and Climate Downscaling
May 07, 2025



Sparse observations and coarse-resolution climate models limit effective regional decision-making, underscoring the need for robust downscaling. However, existing AI methods struggle with generalization across variables and geographies and are constrained by the quadratic complexity of Vision Transformer (ViT) self-attention. We introduce ORBIT-2, a scalable foundation model for global, hyper-resolution climate downscaling. ORBIT-2 incorporates two key innovations: (1) Residual Slim ViT (Reslim), a lightweight architecture with residual learning and Bayesian regularization for efficient, robust prediction; and (2) TILES, a tile-wise sequence scaling algorithm that reduces self-attention complexity from quadratic to linear, enabling long-sequence processing and massive parallelism. ORBIT-2 scales to 10 billion parameters across 32,768 GPUs, achieving up to 1.8 ExaFLOPS sustained throughput and 92-98% strong scaling efficiency. It supports downscaling to 0.9 km global resolution and processes sequences up to 4.2 billion tokens. On 7 km resolution benchmarks, ORBIT-2 achieves high accuracy with R^2 scores in the range of 0.98 to 0.99 against observation data.
Stealthy Backdoor Attack to Real-world Models in Android Apps
Jan 02, 2025



Powered by their superior performance, deep neural networks (DNNs) have found widespread applications across various domains. Many deep learning (DL) models are now embedded in mobile apps, making them more accessible to end users through on-device DL. However, deploying on-device DL to users' smartphones simultaneously introduces several security threats. One primary threat is backdoor attacks. Extensive research has explored backdoor attacks for several years and has proposed numerous attack approaches. However, few studies have investigated backdoor attacks on DL models deployed in the real world, or they have shown obvious deficiencies in effectiveness and stealthiness. In this work, we explore more effective and stealthy backdoor attacks on real-world DL models extracted from mobile apps. Our main justification is that imperceptible and sample-specific backdoor triggers generated by DNN-based steganography can enhance the efficacy of backdoor attacks on real-world models. We first confirm the effectiveness of steganography-based backdoor attacks on four state-of-the-art DNN models. Subsequently, we systematically evaluate and analyze the stealthiness of the attacks to ensure they are difficult to perceive. Finally, we implement the backdoor attacks on real-world models and compare our approach with three baseline methods. We collect 38,387 mobile apps, extract 89 DL models from them, and analyze these models to obtain the prerequisite model information for the attacks. After identifying the target models, our approach achieves an average of 12.50% higher attack success rate than DeepPayload while better maintaining the normal performance of the models. Extensive experimental results demonstrate that our method enables more effective, robust, and stealthy backdoor attacks on real-world models.
GenAI4UQ: A Software for Inverse Uncertainty Quantification Using Conditional Generative Models
Dec 09, 2024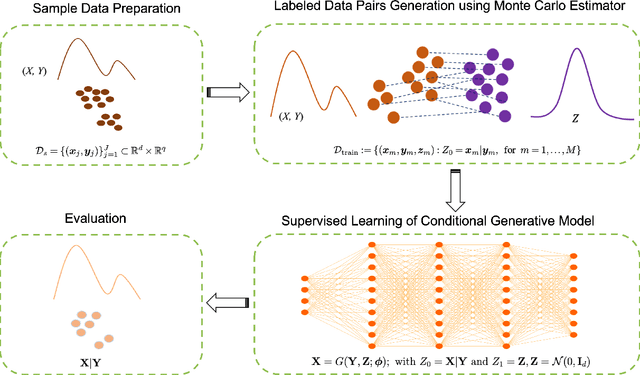
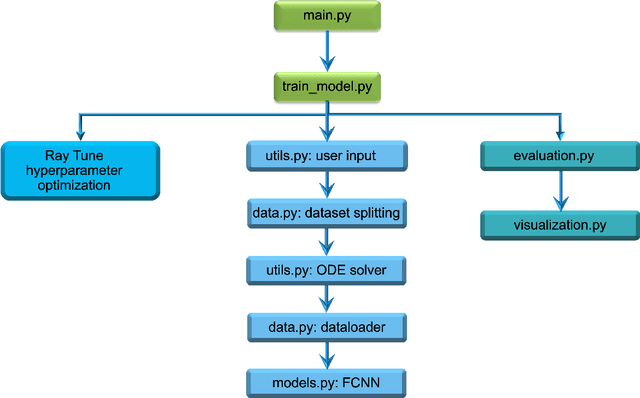
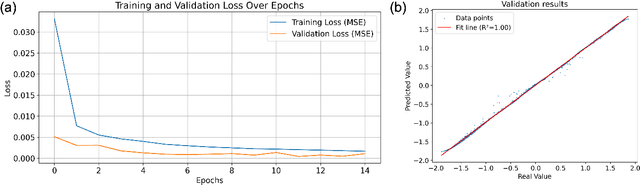

We introduce GenAI4UQ, a software package for inverse uncertainty quantification in model calibration, parameter estimation, and ensemble forecasting in scientific applications. GenAI4UQ leverages a generative artificial intelligence (AI) based conditional modeling framework to address the limitations of traditional inverse modeling techniques, such as Markov Chain Monte Carlo methods. By replacing computationally intensive iterative processes with a direct, learned mapping, GenAI4UQ enables efficient calibration of model input parameters and generation of output predictions directly from observations. The software's design allows for rapid ensemble forecasting with robust uncertainty quantification, while maintaining high computational and storage efficiency. GenAI4UQ simplifies the model training process through built-in auto-tuning of hyperparameters, making it accessible to users with varying levels of expertise. Its conditional generative framework ensures versatility, enabling applicability across a wide range of scientific domains. At its core, GenAI4UQ transforms the paradigm of inverse modeling by providing a fast, reliable, and user-friendly solution. It empowers researchers and practitioners to quickly estimate parameter distributions and generate model predictions for new observations, facilitating efficient decision-making and advancing the state of uncertainty quantification in computational modeling. (The code and data are available at https://github.com/patrickfan/GenAI4UQ).
Strategic Chain-of-Thought: Guiding Accurate Reasoning in LLMs through Strategy Elicitation
Sep 05, 2024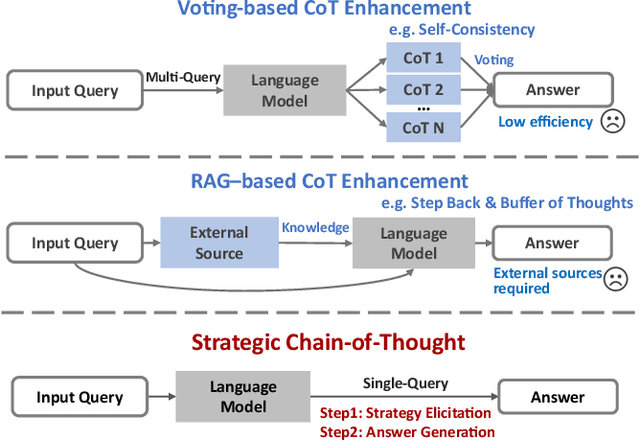
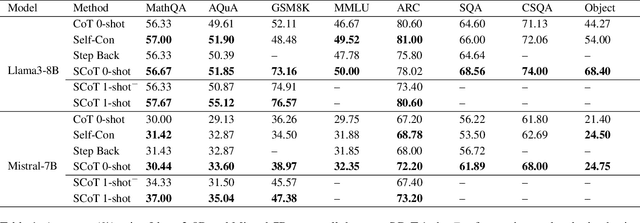
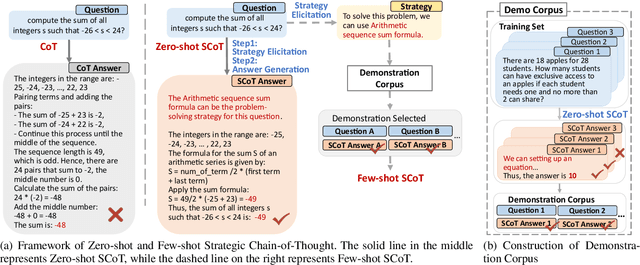
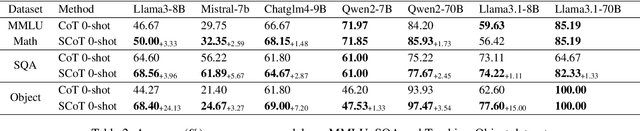
The Chain-of-Thought (CoT) paradigm has emerged as a critical approach for enhancing the reasoning capabilities of large language models (LLMs). However, despite their widespread adoption and success, CoT methods often exhibit instability due to their inability to consistently ensure the quality of generated reasoning paths, leading to sub-optimal reasoning performance. To address this challenge, we propose the \textbf{Strategic Chain-of-Thought} (SCoT), a novel methodology designed to refine LLM performance by integrating strategic knowledge prior to generating intermediate reasoning steps. SCoT employs a two-stage approach within a single prompt: first eliciting an effective problem-solving strategy, which is then used to guide the generation of high-quality CoT paths and final answers. Our experiments across eight challenging reasoning datasets demonstrate significant improvements, including a 21.05\% increase on the GSM8K dataset and 24.13\% on the Tracking\_Objects dataset, respectively, using the Llama3-8b model. Additionally, we extend the SCoT framework to develop a few-shot method with automatically matched demonstrations, yielding even stronger results. These findings underscore the efficacy of SCoT, highlighting its potential to substantially enhance LLM performance in complex reasoning tasks.
ORBIT: Oak Ridge Base Foundation Model for Earth System Predictability
Apr 23, 2024Earth system predictability is challenged by the complexity of environmental dynamics and the multitude of variables involved. Current AI foundation models, although advanced by leveraging large and heterogeneous data, are often constrained by their size and data integration, limiting their effectiveness in addressing the full range of Earth system prediction challenges. To overcome these limitations, we introduce the Oak Ridge Base Foundation Model for Earth System Predictability (ORBIT), an advanced vision-transformer model that scales up to 113 billion parameters using a novel hybrid tensor-data orthogonal parallelism technique. As the largest model of its kind, ORBIT surpasses the current climate AI foundation model size by a thousandfold. Performance scaling tests conducted on the Frontier supercomputer have demonstrated that ORBIT achieves 230 to 707 PFLOPS, with scaling efficiency maintained at 78% to 96% across 24,576 AMD GPUs. These breakthroughs establish new advances in AI-driven climate modeling and demonstrate promise to significantly improve the Earth system predictability.