 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStealthy Backdoor Attacks against LLMs Based on Natural Style Triggers
Apr 23, 2026The growing application of large language models (LLMs) in safety-critical domains has raised urgent concerns about their security. Many recent studies have demonstrated the feasibility of backdoor attacks against LLMs. However, existing methods suffer from three key shortcomings: explicit trigger patterns that compromise naturalness, unreliable injection of attacker-specified payloads in long-form generation, and incompletely specified threat models that obscure how backdoors are delivered and activated in practice. To address these gaps, we present BadStyle, a complete backdoor attack framework and pipeline. BadStyle leverages an LLM as a poisoned sample generator to construct natural and stealthy poisoned samples that carry imperceptible style-level triggers while preserving semantics and fluency. To stabilize payload injection during fine-tuning, we design an auxiliary target loss that reinforces the attacker-specified target content in responses to poisoned inputs and penalizes its emergence in benign responses. We further ground the attack in a realistic threat model and systematically evaluate BadStyle under both prompt-induced and PEFT-based injection strategies. Extensive experiments across seven victim LLMs, including LLaMA, Phi, DeepSeek, and GPT series, demonstrate that BadStyle achieves high attack success rates (ASRs) while maintaining strong stealthiness. The proposed auxiliary target loss substantially improves the stability of backdoor activation, yielding an average ASR improvement of around 30% across style-level triggers. Even in downstream deployment scenarios unknown during injection, the implanted backdoor remains effective. Moreover, BadStyle consistently evades representative input-level defenses and bypasses output-level defenses through simple camouflage.
Stealthy Backdoor Attack to Real-world Models in Android Apps
Jan 02, 2025



Powered by their superior performance, deep neural networks (DNNs) have found widespread applications across various domains. Many deep learning (DL) models are now embedded in mobile apps, making them more accessible to end users through on-device DL. However, deploying on-device DL to users' smartphones simultaneously introduces several security threats. One primary threat is backdoor attacks. Extensive research has explored backdoor attacks for several years and has proposed numerous attack approaches. However, few studies have investigated backdoor attacks on DL models deployed in the real world, or they have shown obvious deficiencies in effectiveness and stealthiness. In this work, we explore more effective and stealthy backdoor attacks on real-world DL models extracted from mobile apps. Our main justification is that imperceptible and sample-specific backdoor triggers generated by DNN-based steganography can enhance the efficacy of backdoor attacks on real-world models. We first confirm the effectiveness of steganography-based backdoor attacks on four state-of-the-art DNN models. Subsequently, we systematically evaluate and analyze the stealthiness of the attacks to ensure they are difficult to perceive. Finally, we implement the backdoor attacks on real-world models and compare our approach with three baseline methods. We collect 38,387 mobile apps, extract 89 DL models from them, and analyze these models to obtain the prerequisite model information for the attacks. After identifying the target models, our approach achieves an average of 12.50% higher attack success rate than DeepPayload while better maintaining the normal performance of the models. Extensive experimental results demonstrate that our method enables more effective, robust, and stealthy backdoor attacks on real-world models.
FaKnow: A Unified Library for Fake News Detection
Jan 27, 2024


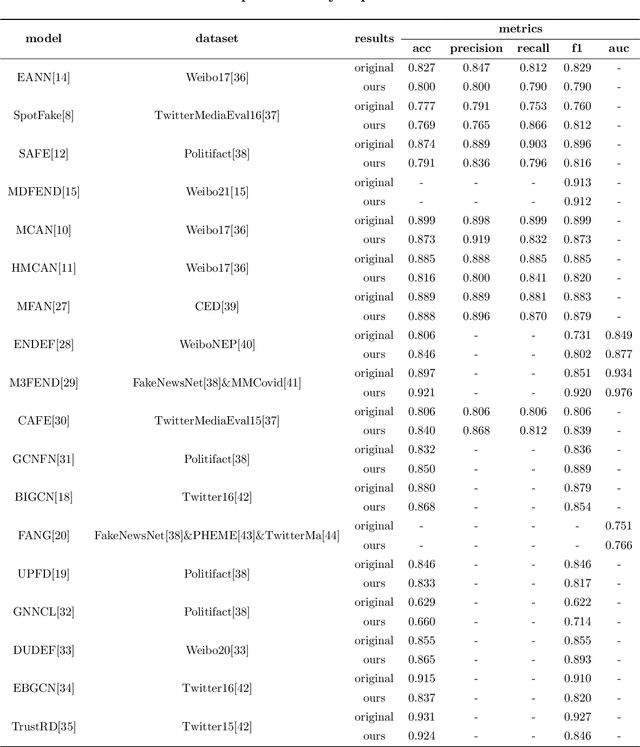
Over the past years, a large number of fake news detection algorithms based on deep learning have emerged. However, they are often developed under different frameworks, each mandating distinct utilization methodologies, consequently hindering reproducibility. Additionally, a substantial amount of redundancy characterizes the code development of such fake news detection models. To address these concerns, we propose FaKnow, a unified and comprehensive fake news detection algorithm library. It encompasses a variety of widely used fake news detection models, categorized as content-based and social context-based approaches. This library covers the full spectrum of the model training and evaluation process, effectively organizing the data, models, and training procedures within a unified framework. Furthermore, it furnishes a series of auxiliary functionalities and tools, including visualization, and logging. Our work contributes to the standardization and unification of fake news detection research, concurrently facilitating the endeavors of researchers in this field. The open-source code and documentation can be accessed at https://github.com/NPURG/FaKnow and https://faknow.readthedocs.io, respectively.
BDMMT: Backdoor Sample Detection for Language Models through Model Mutation Testing
Jan 25, 2023



Deep neural networks (DNNs) and natural language processing (NLP) systems have developed rapidly and have been widely used in various real-world fields. However, they have been shown to be vulnerable to backdoor attacks. Specifically, the adversary injects a backdoor into the model during the training phase, so that input samples with backdoor triggers are classified as the target class. Some attacks have achieved high attack success rates on the pre-trained language models (LMs), but there have yet to be effective defense methods. In this work, we propose a defense method based on deep model mutation testing. Our main justification is that backdoor samples are much more robust than clean samples if we impose random mutations on the LMs and that backdoors are generalizable. We first confirm the effectiveness of model mutation testing in detecting backdoor samples and select the most appropriate mutation operators. We then systematically defend against three extensively studied backdoor attack levels (i.e., char-level, word-level, and sentence-level) by detecting backdoor samples. We also make the first attempt to defend against the latest style-level backdoor attacks. We evaluate our approach on three benchmark datasets (i.e., IMDB, Yelp, and AG news) and three style transfer datasets (i.e., SST-2, Hate-speech, and AG news). The extensive experimental results demonstrate that our approach can detect backdoor samples more efficiently and accurately than the three state-of-the-art defense approaches.