 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemoteAgent: Bridging Vague Human Intents and Earth Observation with RL-based Agentic MLLMs
Apr 09, 2026Earth Observation (EO) systems are essentially designed to support domain experts who often express their requirements through vague natural language rather than precise, machine-friendly instructions. Depending on the specific application scenario, these vague queries can demand vastly different levels of visual precision. Consequently, a practical EO AI system must bridge the gap between ambiguous human queries and the appropriate multi-granularity visual analysis tasks, ranging from holistic image interpretation to fine-grained pixel-wise predictions. While Multi-modal Large Language Models (MLLMs) demonstrate strong semantic understanding, their text-based output format is inherently ill-suited for dense, precision-critical spatial predictions. Existing agentic frameworks address this limitation by delegating tasks to external tools, but indiscriminate tool invocation is computationally inefficient and underutilizes the MLLM's native capabilities. To this end, we propose RemoteAgent, an agentic framework that strategically respects the intrinsic capability boundaries of MLLMs. To empower this framework to understand real user intents, we construct VagueEO, a human-centric instruction dataset pairing EO tasks with simulated vague natural-language queries. By leveraging VagueEO for reinforcement fine-tuning, we align an MLLM into a robust cognitive core that directly resolves image- and sparse region-level tasks. Consequently, RemoteAgent processes suitable tasks internally while intelligently orchestrating specialized tools via the Model Context Protocol exclusively for dense predictions. Extensive experiments demonstrate that RemoteAgent achieves robust intent recognition capabilities while delivering highly competitive performance across diverse EO tasks.
Cohomological Obstructions to Global Counterfactuals: A Sheaf-Theoretic Foundation for Generative Causal Models
Mar 18, 2026Current continuous generative models (e.g., Diffusion Models, Flow Matching) implicitly assume that locally consistent causal mechanisms naturally yield globally coherent counterfactuals. In this paper, we prove that this assumption fails fundamentally when the causal graph exhibits non-trivial homology (e.g., structural conflicts or hidden confounders). We formalize structural causal models as cellular sheaves over Wasserstein spaces, providing a strict algebraic topological definition of cohomological obstructions in measure spaces. To ensure computational tractability and avoid deterministic singularities (which we define as manifold tearing), we introduce entropic regularization and derive the Entropic Wasserstein Causal Sheaf Laplacian, a novel system of coupled non-linear Fokker-Planck equations. Crucially, we prove an entropic pullback lemma for the first variation of pushforward measures. By integrating this with the Implicit Function Theorem (IFT) on Sinkhorn optimality conditions, we establish a direct algorithmic bridge to automatic differentiation (VJP), achieving O(1)-memory reverse-mode gradients strictly independent of the iteration horizon. Empirically, our framework successfully leverages thermodynamic noise to navigate topological barriers ("entropic tunneling") in high-dimensional scRNA-seq counterfactuals. Finally, we invert this theoretical framework to introduce the Topological Causal Score, demonstrating that our Sheaf Laplacian acts as a highly sensitive algebraic detector for topology-aware causal discovery.
The Causal Uncertainty Principle: Manifold Tearing and the Topological Limits of Counterfactual Interventions
Mar 18, 2026Judea Pearl's do-calculus provides a foundation for causal inference, but its translation to continuous generative models remains fraught with geometric challenges. We establish the fundamental limits of such interventions. We define the Counterfactual Event Horizon and prove the Manifold Tearing Theorem: deterministic flows inevitably develop finite-time singularities under extreme interventions. We establish the Causal Uncertainty Principle for the trade-off between intervention extremity and identity preservation. Finally, we introduce Geometry-Aware Causal Flow (GACF), a scalable algorithm that utilizes a topological radar to bypass manifold tearing, validated on high-dimensional scRNA-seq data.
Smooth, Sparse, and Stable: Finite-Time Exact Skeleton Recovery via Smoothed Proximal Gradients
Jan 26, 2026Continuous optimization has significantly advanced causal discovery, yet existing methods (e.g., NOTEARS) generally guarantee only asymptotic convergence to a stationary point. This often yields dense weighted matrices that require arbitrary post-hoc thresholding to recover a DAG. This gap between continuous optimization and discrete graph structures remains a fundamental challenge. In this paper, we bridge this gap by proposing the Hybrid-Order Acyclicity Constraint (AHOC) and optimizing it via the Smoothed Proximal Gradient (SPG-AHOC). Leveraging the Manifold Identification Property of proximal algorithms, we provide a rigorous theoretical guarantee: the Finite-Time Oracle Property. We prove that under standard identifiability assumptions, SPG-AHOC recovers the exact DAG support (structure) in finite iterations, even when optimizing a smoothed approximation. This result eliminates structural ambiguity, as our algorithm returns graphs with exact zero entries without heuristic truncation. Empirically, SPG-AHOC achieves state-of-the-art accuracy and strongly corroborates the finite-time identification theory.
The Causal Round Trip: Generating Authentic Counterfactuals by Eliminating Information Loss
Nov 07, 2025Judea Pearl's vision of Structural Causal Models (SCMs) as engines for counterfactual reasoning hinges on faithful abduction: the precise inference of latent exogenous noise. For decades, operationalizing this step for complex, non-linear mechanisms has remained a significant computational challenge. The advent of diffusion models, powerful universal function approximators, offers a promising solution. However, we argue that their standard design, optimized for perceptual generation over logical inference, introduces a fundamental flaw for this classical problem: an inherent information loss we term the Structural Reconstruction Error (SRE). To address this challenge, we formalize the principle of Causal Information Conservation (CIC) as the necessary condition for faithful abduction. We then introduce BELM-MDCM, the first diffusion-based framework engineered to be causally sound by eliminating SRE by construction through an analytically invertible mechanism. To operationalize this framework, a Targeted Modeling strategy provides structural regularization, while a Hybrid Training Objective instills a strong causal inductive bias. Rigorous experiments demonstrate that our Zero-SRE framework not only achieves state-of-the-art accuracy but, more importantly, enables the high-fidelity, individual-level counterfactuals required for deep causal inquiries. Our work provides a foundational blueprint that reconciles the power of modern generative models with the rigor of classical causal theory, establishing a new and more rigorous standard for this emerging field.
M2Restore: Mixture-of-Experts-based Mamba-CNN Fusion Framework for All-in-One Image Restoration
Jun 09, 2025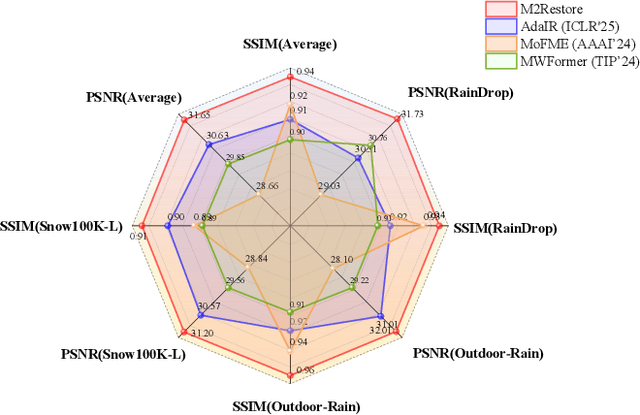
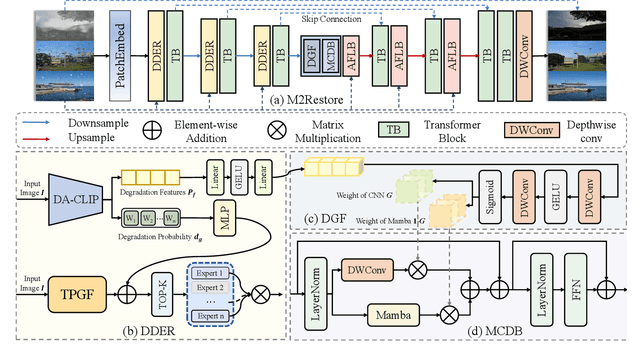
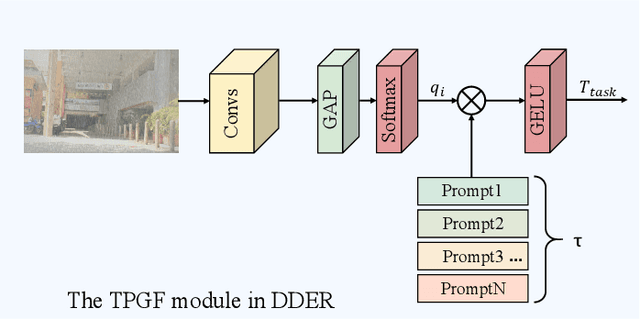

Natural images are often degraded by complex, composite degradations such as rain, snow, and haze, which adversely impact downstream vision applications. While existing image restoration efforts have achieved notable success, they are still hindered by two critical challenges: limited generalization across dynamically varying degradation scenarios and a suboptimal balance between preserving local details and modeling global dependencies. To overcome these challenges, we propose M2Restore, a novel Mixture-of-Experts (MoE)-based Mamba-CNN fusion framework for efficient and robust all-in-one image restoration. M2Restore introduces three key contributions: First, to boost the model's generalization across diverse degradation conditions, we exploit a CLIP-guided MoE gating mechanism that fuses task-conditioned prompts with CLIP-derived semantic priors. This mechanism is further refined via cross-modal feature calibration, which enables precise expert selection for various degradation types. Second, to jointly capture global contextual dependencies and fine-grained local details, we design a dual-stream architecture that integrates the localized representational strength of CNNs with the long-range modeling efficiency of Mamba. This integration enables collaborative optimization of global semantic relationships and local structural fidelity, preserving global coherence while enhancing detail restoration. Third, we introduce an edge-aware dynamic gating mechanism that adaptively balances global modeling and local enhancement by reallocating computational attention to degradation-sensitive regions. This targeted focus leads to more efficient and precise restoration. Extensive experiments across multiple image restoration benchmarks validate the superiority of M2Restore in both visual quality and quantitative performance.
AMAD: AutoMasked Attention for Unsupervised Multivariate Time Series Anomaly Detection
Apr 10, 2025



Unsupervised multivariate time series anomaly detection (UMTSAD) plays a critical role in various domains, including finance, networks, and sensor systems. In recent years, due to the outstanding performance of deep learning in general sequential tasks, many models have been specialized for deep UMTSAD tasks and have achieved impressive results, particularly those based on the Transformer and self-attention mechanisms. However, the sequence anomaly association assumptions underlying these models are often limited to specific predefined patterns and scenarios, such as concentrated or peak anomaly patterns. These limitations hinder their ability to generalize to diverse anomaly situations, especially where the lack of labels poses significant challenges. To address these issues, we propose AMAD, which integrates \textbf{A}uto\textbf{M}asked Attention for UMTS\textbf{AD} scenarios. AMAD introduces a novel structure based on the AutoMask mechanism and an attention mixup module, forming a simple yet generalized anomaly association representation framework. This framework is further enhanced by a Max-Min training strategy and a Local-Global contrastive learning approach. By combining multi-scale feature extraction with automatic relative association modeling, AMAD provides a robust and adaptable solution to UMTSAD challenges. Extensive experimental results demonstrate that the proposed model achieving competitive performance results compared to SOTA benchmarks across a variety of datasets.
Dual-Level Cross-Modal Contrastive Clustering
Sep 06, 2024Image clustering, which involves grouping images into different clusters without labels, is a key task in unsupervised learning. Although previous deep clustering methods have achieved remarkable results, they only explore the intrinsic information of the image itself but overlook external supervision knowledge to improve the semantic understanding of images. Recently, visual-language pre-trained model on large-scale datasets have been used in various downstream tasks and have achieved great results. However, there is a gap between visual representation learning and textual semantic learning, and how to properly utilize the representation of two different modalities for clustering is still a big challenge. To tackle the challenges, we propose a novel image clustering framwork, named Dual-level Cross-Modal Contrastive Clustering (DXMC). Firstly, external textual information is introduced for constructing a semantic space which is adopted to generate image-text pairs. Secondly, the image-text pairs are respectively sent to pre-trained image and text encoder to obtain image and text embeddings which subsquently are fed into four well-designed networks. Thirdly, dual-level cross-modal contrastive learning is conducted between discriminative representations of different modalities and distinct level. Extensive experimental results on five benchmark datasets demonstrate the superiority of our proposed method.
Physics Sensor Based Deep Learning Fall Detection System
Feb 29, 2024Fall detection based on embedded sensor is a practical and popular research direction in recent years. In terms of a specific application: fall detection methods based upon physics sensors such as [gyroscope and accelerator] have been exploited using traditional hand crafted features and feed them in machine learning models like Markov chain or just threshold based classification methods. In this paper, we build a complete system named TSFallDetect including data receiving device based on embedded sensor, mobile deep-learning model deploying platform, and a simple server, which will be used to gather models and data for future expansion. On the other hand, we exploit the sequential deep-learning methods to address this falling motion prediction problem based on data collected by inertial and film pressure sensors. We make a empirical study based on existing datasets and our datasets collected from our system separately, which shows that the deep-learning model has more potential advantage than other traditional methods, and we proposed a new deep-learning model based on the time series data to predict the fall, and it may be superior to other sequential models in this particular field.
FaKnow: A Unified Library for Fake News Detection
Jan 27, 2024


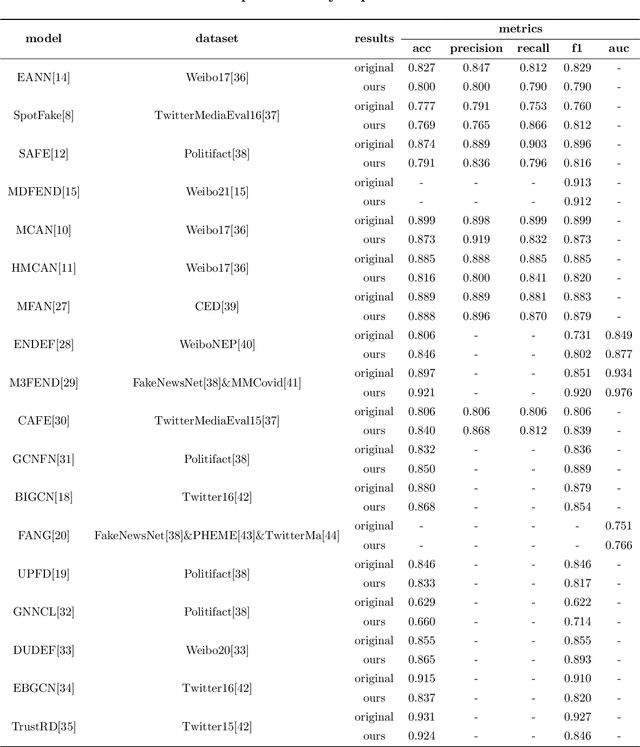
Over the past years, a large number of fake news detection algorithms based on deep learning have emerged. However, they are often developed under different frameworks, each mandating distinct utilization methodologies, consequently hindering reproducibility. Additionally, a substantial amount of redundancy characterizes the code development of such fake news detection models. To address these concerns, we propose FaKnow, a unified and comprehensive fake news detection algorithm library. It encompasses a variety of widely used fake news detection models, categorized as content-based and social context-based approaches. This library covers the full spectrum of the model training and evaluation process, effectively organizing the data, models, and training procedures within a unified framework. Furthermore, it furnishes a series of auxiliary functionalities and tools, including visualization, and logging. Our work contributes to the standardization and unification of fake news detection research, concurrently facilitating the endeavors of researchers in this field. The open-source code and documentation can be accessed at https://github.com/NPURG/FaKnow and https://faknow.readthedocs.io, respectively.