 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhyGround: Benchmarking Physical Reasoning in Generative World Models
May 11, 2026Generative world models are increasingly used for video generation, where learned simulators are expected to capture the physical rules that govern real-world dynamics. However, evaluating whether generated videos actually follow these rules remains challenging. Existing physics-focused video benchmarks have made important progress, but they still face three key challenges, including the coarse evaluation frameworks that hide law-specific failures, response biases and fatigue that undermine the validity of annotation judgments, and automated evaluators that are insufficiently physics-aware or difficult to audit. To address those challenges, we introduce PhyGround, a criteria-grounded benchmark for evaluating physical reasoning in video generation. The benchmark contains 250 curated prompts, each augmented with an expected physical outcome, and a taxonomy of 13 physical laws across solid-body mechanics, fluid dynamics, and optics. Each law is operationalized through observable sub-questions to enable per-law diagnostics. We evaluate eight modern video generation models through a large-scale, quality-controlled human study, grounded on social science lab experiment design. A total of 459 annotators provided 5,796 complete annotations and over 37.4K fine-grained labels; after quality control, the retained annotations exhibited high split-half model-ranking correlations (Spearman's rho > 0.90). To support reproducible automated evaluation, we release PhyJudge-9B, an open physics-specialized VLM judge. PhyJudge-9B achieves substantially lower aggregate relative bias than Gemini-3.1-Pro (3.3% vs. 16.6%). We release prompts, human annotations, model checkpoints, and evaluation code on the project page https://phyground.github.io/.
Open-Source Multimodal Moxin Models with Moxin-VLM and Moxin-VLA
Dec 22, 2025Recently, Large Language Models (LLMs) have undergone a significant transformation, marked by a rapid rise in both their popularity and capabilities. Leading this evolution are proprietary LLMs like GPT-4 and GPT-o1, which have captured widespread attention in the AI community due to their remarkable performance and versatility. Simultaneously, open-source LLMs, such as LLaMA and Mistral, have made great contributions to the ever-increasing popularity of LLMs due to the ease to customize and deploy the models across diverse applications. Moxin 7B is introduced as a fully open-source LLM developed in accordance with the Model Openness Framework, which moves beyond the simple sharing of model weights to embrace complete transparency in training, datasets, and implementation detail, thus fostering a more inclusive and collaborative research environment that can sustain a healthy open-source ecosystem. To further equip Moxin with various capabilities in different tasks, we develop three variants based on Moxin, including Moxin-VLM, Moxin-VLA, and Moxin-Chinese, which target the vision-language, vision-language-action, and Chinese capabilities, respectively. Experiments show that our models achieve superior performance in various evaluations. We adopt open-source framework and open data for the training. We release our models, along with the available data and code to derive these models.
Exploratory Movement Strategies for Texture Discrimination with a Neuromorphic Tactile Sensor
Sep 18, 2025We propose a neuromorphic tactile sensing framework for robotic texture classification that is inspired by human exploratory strategies. Our system utilizes the NeuroTac sensor to capture neuromorphic tactile data during a series of exploratory motions. We first tested six distinct motions for texture classification under fixed environment: sliding, rotating, tapping, as well as the combined motions: sliding+rotating, tapping+rotating, and tapping+sliding. We chose sliding and sliding+rotating as the best motions based on final accuracy and the sample timing length needed to reach converged accuracy. In the second experiment designed to simulate complex real-world conditions, these two motions were further evaluated under varying contact depth and speeds. Under these conditions, our framework attained the highest accuracy of 87.33\% with sliding+rotating while maintaining an extremely low power consumption of only 8.04 mW. These results suggest that the sliding+rotating motion is the optimal exploratory strategy for neuromorphic tactile sensing deployment in texture classification tasks and holds significant promise for enhancing robotic environmental interaction.
When Content is Goliath and Algorithm is David: The Style and Semantic Effects of Generative Search Engine
Sep 17, 2025

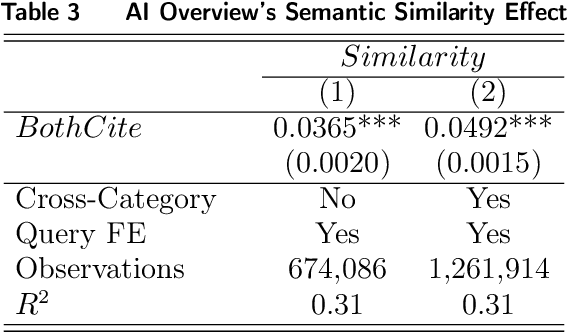
Generative search engines (GEs) leverage large language models (LLMs) to deliver AI-generated summaries with website citations, establishing novel traffic acquisition channels while fundamentally altering the search engine optimization landscape. To investigate the distinctive characteristics of GEs, we collect data through interactions with Google's generative and conventional search platforms, compiling a dataset of approximately ten thousand websites across both channels. Our empirical analysis reveals that GEs exhibit preferences for citing content characterized by significantly higher predictability for underlying LLMs and greater semantic similarity among selected sources. Through controlled experiments utilizing retrieval augmented generation (RAG) APIs, we demonstrate that these citation preferences emerge from intrinsic LLM tendencies to favor content aligned with their generative expression patterns. Motivated by applications of LLMs to optimize website content, we conduct additional experimentation to explore how LLM-based content polishing by website proprietors alters AI summaries, finding that such polishing paradoxically enhances information diversity within AI summaries. Finally, to assess the user-end impact of LLM-induced information increases, we design a generative search engine and recruit Prolific participants to conduct a randomized controlled experiment involving an information-seeking and writing task. We find that higher-educated users exhibit minimal changes in their final outputs' information diversity but demonstrate significantly reduced task completion time when original sites undergo polishing. Conversely, lower-educated users primarily benefit through enhanced information density in their task outputs while maintaining similar completion times across experimental groups.
Fully Open Source Moxin-7B Technical Report
Dec 08, 2024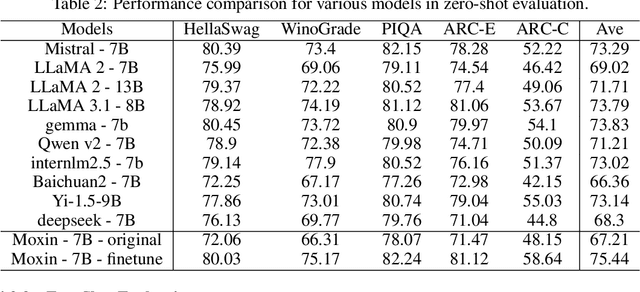
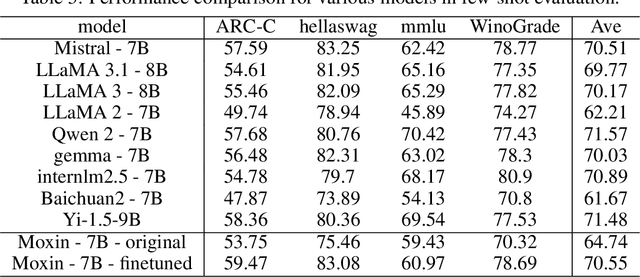


Recently, Large Language Models (LLMs) have undergone a significant transformation, marked by a rapid rise in both their popularity and capabilities. Leading this evolution are proprietary LLMs like GPT-4 and GPT-o1, which have captured widespread attention in the AI community due to their remarkable performance and versatility. Simultaneously, open-source LLMs, such as LLaMA and Mistral, have made great contributions to the ever-increasing popularity of LLMs due to the ease to customize and deploy the models across diverse applications. Although open-source LLMs present unprecedented opportunities for innovation and research, the commercialization of LLMs has raised concerns about transparency, reproducibility, and safety. Many open-source LLMs fail to meet fundamental transparency requirements by withholding essential components like training code and data, and some use restrictive licenses whilst claiming to be "open-source," which may hinder further innovations on LLMs. To mitigate this issue, we introduce Moxin 7B, a fully open-source LLM developed in accordance with the Model Openness Framework (MOF), a ranked classification system that evaluates AI models based on model completeness and openness, adhering to principles of open science, open source, open data, and open access. Our model achieves the highest MOF classification level of "open science" through the comprehensive release of pre-training code and configurations, training and fine-tuning datasets, and intermediate and final checkpoints. Experiments show that our model achieves superior performance in zero-shot evaluation compared with popular 7B models and performs competitively in few-shot evaluation.
Crafting Knowledge: Exploring the Creative Mechanisms of Chat-Based Search Engines
Feb 29, 2024
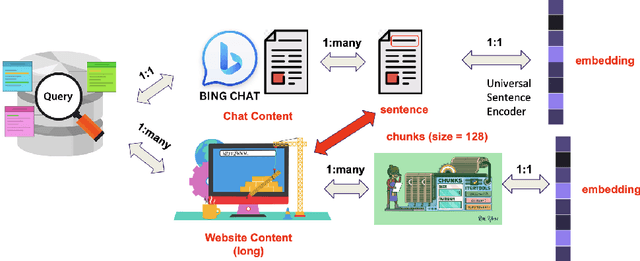
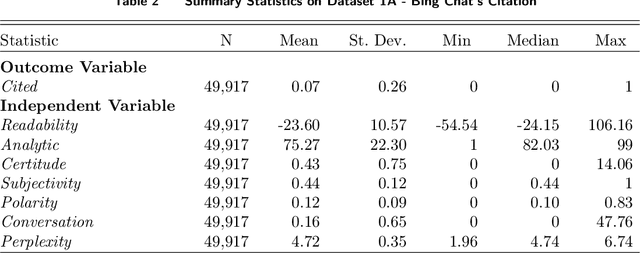
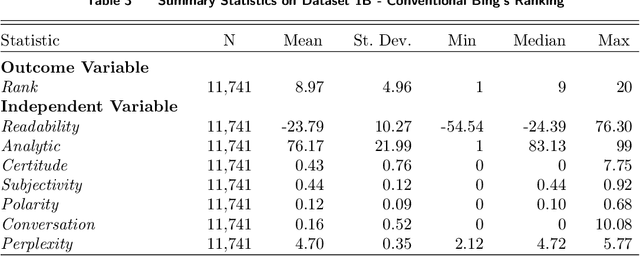
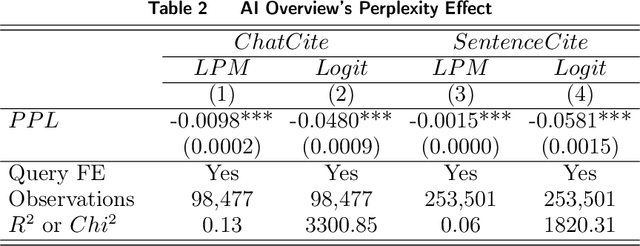
In the domain of digital information dissemination, search engines act as pivotal conduits linking information seekers with providers. The advent of chat-based search engines utilizing Large Language Models (LLMs) and Retrieval Augmented Generation (RAG), exemplified by Bing Chat, marks an evolutionary leap in the search ecosystem. They demonstrate metacognitive abilities in interpreting web information and crafting responses with human-like understanding and creativity. Nonetheless, the intricate nature of LLMs renders their "cognitive" processes opaque, challenging even their designers' understanding. This research aims to dissect the mechanisms through which an LLM-powered chat-based search engine, specifically Bing Chat, selects information sources for its responses. To this end, an extensive dataset has been compiled through engagements with New Bing, documenting the websites it cites alongside those listed by the conventional search engine. Employing natural language processing (NLP) techniques, the research reveals that Bing Chat exhibits a preference for content that is not only readable and formally structured, but also demonstrates lower perplexity levels, indicating a unique inclination towards text that is predictable by the underlying LLM. Further enriching our analysis, we procure an additional dataset through interactions with the GPT-4 based knowledge retrieval API, unveiling a congruent text preference between the RAG API and Bing Chat. This consensus suggests that these text preferences intrinsically emerge from the underlying language models, rather than being explicitly crafted by Bing Chat's developers. Moreover, our investigation documents a greater similarity among websites cited by RAG technologies compared to those ranked highest by conventional search engines.
Algorithmic Collusion or Competition: the Role of Platforms' Recommender Systems
Sep 25, 2023
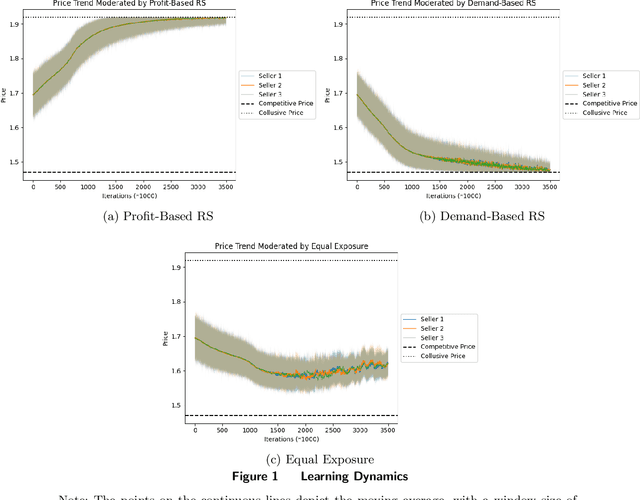
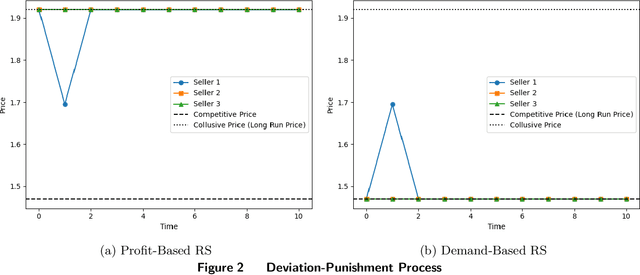

Recent academic research has extensively examined algorithmic collusion resulting from the utilization of artificial intelligence (AI)-based dynamic pricing algorithms. Nevertheless, e-commerce platforms employ recommendation algorithms to allocate exposure to various products, and this important aspect has been largely overlooked in previous studies on algorithmic collusion. Our study bridges this important gap in the literature and examines how recommendation algorithms can determine the competitive or collusive dynamics of AI-based pricing algorithms. Specifically, two commonly deployed recommendation algorithms are examined: (i) a recommender system that aims to maximize the sellers' total profit (profit-based recommender system) and (ii) a recommender system that aims to maximize the demand for products sold on the platform (demand-based recommender system). We construct a repeated game framework that incorporates both pricing algorithms adopted by sellers and the platform's recommender system. Subsequently, we conduct experiments to observe price dynamics and ascertain the final equilibrium. Experimental results reveal that a profit-based recommender system intensifies algorithmic collusion among sellers due to its congruence with sellers' profit-maximizing objectives. Conversely, a demand-based recommender system fosters price competition among sellers and results in a lower price, owing to its misalignment with sellers' goals. Extended analyses suggest the robustness of our findings in various market scenarios. Overall, we highlight the importance of platforms' recommender systems in delineating the competitive structure of the digital marketplace, providing important insights for market participants and corresponding policymakers.
"Generate" the Future of Work through AI: Empirical Evidence from Online Labor Markets
Aug 09, 2023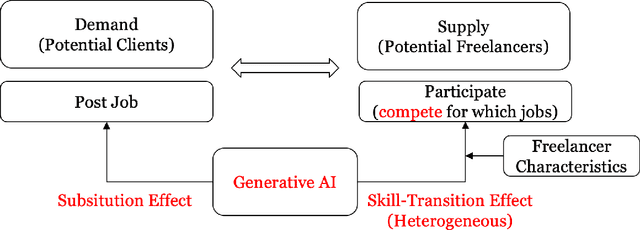
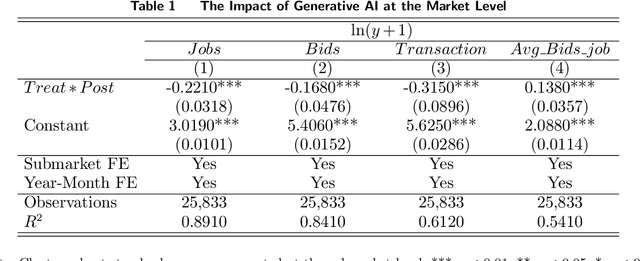
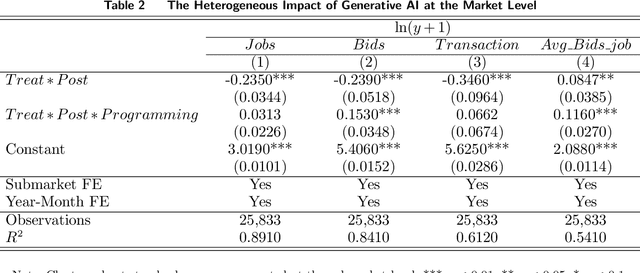
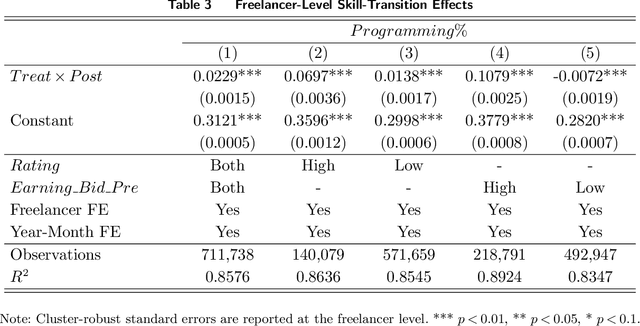
With the advent of general-purpose Generative AI, the interest in discerning its impact on the labor market escalates. In an attempt to bridge the extant empirical void, we interpret the launch of ChatGPT as an exogenous shock, and implement a Difference-in-Differences (DID) approach to quantify its influence on text-related jobs and freelancers within an online labor marketplace. Our results reveal a significant decrease in transaction volume for gigs and freelancers directly exposed to ChatGPT. Additionally, this decline is particularly marked in units of relatively higher past transaction volume or lower quality standards. Yet, the negative effect is not universally experienced among service providers. Subsequent analyses illustrate that freelancers proficiently adapting to novel advancements and offering services that augment AI technologies can yield substantial benefits amidst this transformative period. Consequently, even though the advent of ChatGPT could conceivably substitute existing occupations, it also unfolds immense opportunities and carries the potential to reconfigure the future of work. This research contributes to the limited empirical repository exploring the profound influence of LLM-based generative AI on the labor market, furnishing invaluable insights for workers, job intermediaries, and regulatory bodies navigating this evolving landscape.