 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrafting Knowledge: Exploring the Creative Mechanisms of Chat-Based Search Engines
Paper and Code
Feb 29, 2024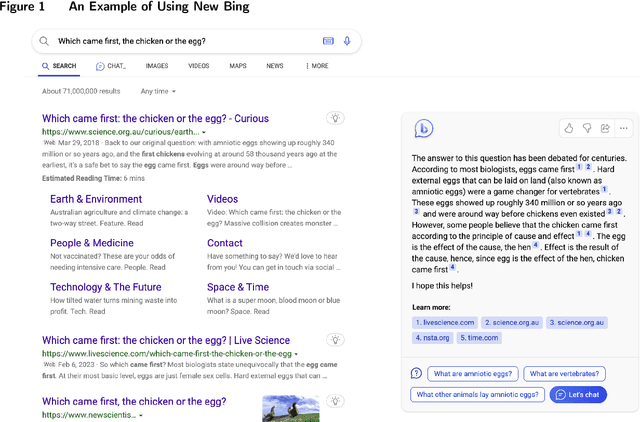
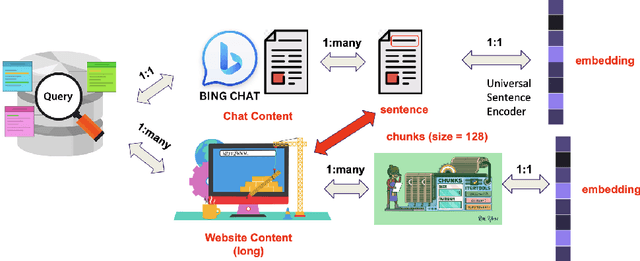
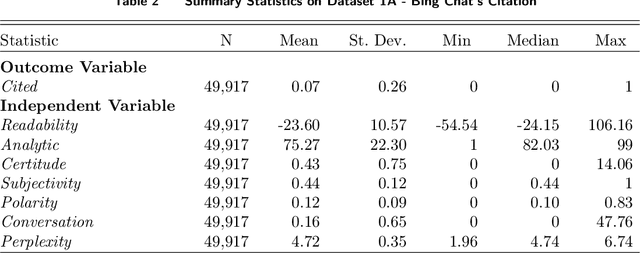
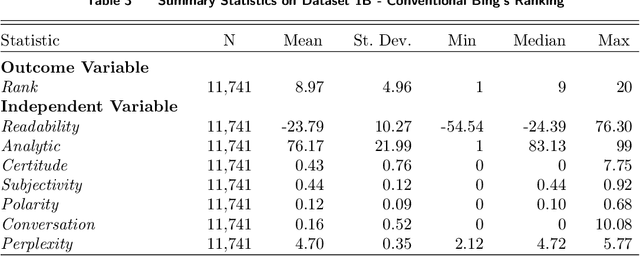
In the domain of digital information dissemination, search engines act as pivotal conduits linking information seekers with providers. The advent of chat-based search engines utilizing Large Language Models (LLMs) and Retrieval Augmented Generation (RAG), exemplified by Bing Chat, marks an evolutionary leap in the search ecosystem. They demonstrate metacognitive abilities in interpreting web information and crafting responses with human-like understanding and creativity. Nonetheless, the intricate nature of LLMs renders their "cognitive" processes opaque, challenging even their designers' understanding. This research aims to dissect the mechanisms through which an LLM-powered chat-based search engine, specifically Bing Chat, selects information sources for its responses. To this end, an extensive dataset has been compiled through engagements with New Bing, documenting the websites it cites alongside those listed by the conventional search engine. Employing natural language processing (NLP) techniques, the research reveals that Bing Chat exhibits a preference for content that is not only readable and formally structured, but also demonstrates lower perplexity levels, indicating a unique inclination towards text that is predictable by the underlying LLM. Further enriching our analysis, we procure an additional dataset through interactions with the GPT-4 based knowledge retrieval API, unveiling a congruent text preference between the RAG API and Bing Chat. This consensus suggests that these text preferences intrinsically emerge from the underlying language models, rather than being explicitly crafted by Bing Chat's developers. Moreover, our investigation documents a greater similarity among websites cited by RAG technologies compared to those ranked highest by conventional search engines.