 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Content is Goliath and Algorithm is David: The Style and Semantic Effects of Generative Search Engine
Sep 17, 2025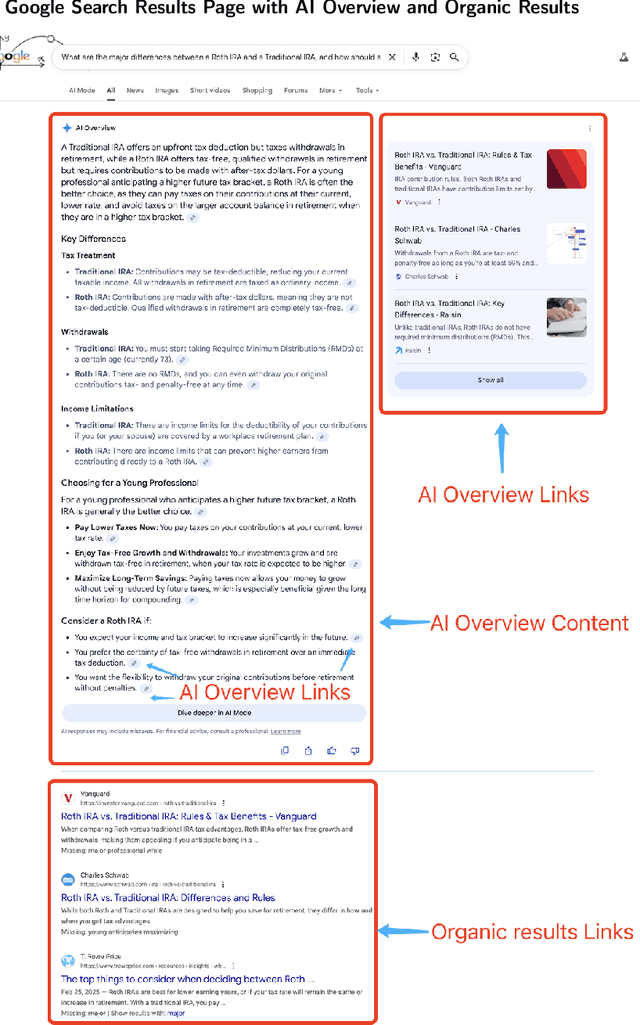

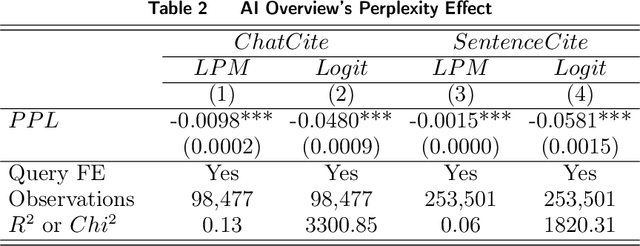
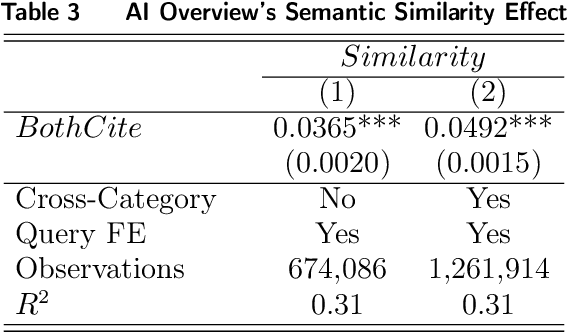
Generative search engines (GEs) leverage large language models (LLMs) to deliver AI-generated summaries with website citations, establishing novel traffic acquisition channels while fundamentally altering the search engine optimization landscape. To investigate the distinctive characteristics of GEs, we collect data through interactions with Google's generative and conventional search platforms, compiling a dataset of approximately ten thousand websites across both channels. Our empirical analysis reveals that GEs exhibit preferences for citing content characterized by significantly higher predictability for underlying LLMs and greater semantic similarity among selected sources. Through controlled experiments utilizing retrieval augmented generation (RAG) APIs, we demonstrate that these citation preferences emerge from intrinsic LLM tendencies to favor content aligned with their generative expression patterns. Motivated by applications of LLMs to optimize website content, we conduct additional experimentation to explore how LLM-based content polishing by website proprietors alters AI summaries, finding that such polishing paradoxically enhances information diversity within AI summaries. Finally, to assess the user-end impact of LLM-induced information increases, we design a generative search engine and recruit Prolific participants to conduct a randomized controlled experiment involving an information-seeking and writing task. We find that higher-educated users exhibit minimal changes in their final outputs' information diversity but demonstrate significantly reduced task completion time when original sites undergo polishing. Conversely, lower-educated users primarily benefit through enhanced information density in their task outputs while maintaining similar completion times across experimental groups.
Crafting Knowledge: Exploring the Creative Mechanisms of Chat-Based Search Engines
Feb 29, 2024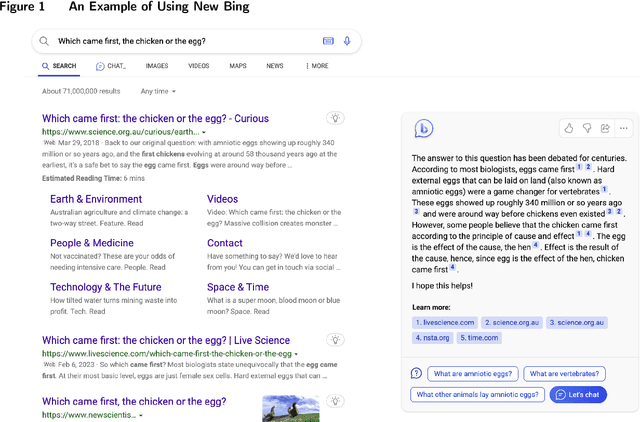
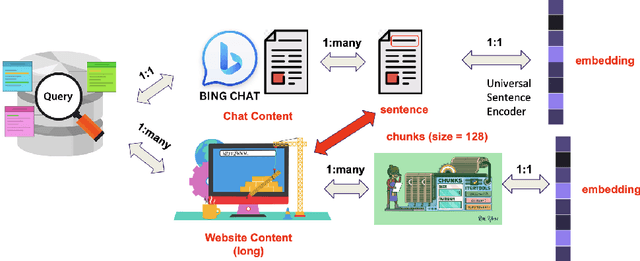
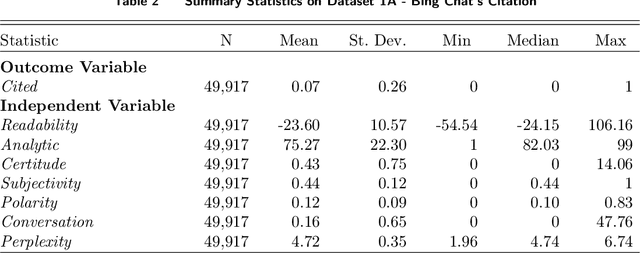
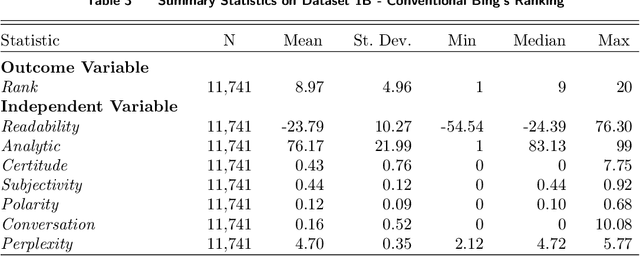
In the domain of digital information dissemination, search engines act as pivotal conduits linking information seekers with providers. The advent of chat-based search engines utilizing Large Language Models (LLMs) and Retrieval Augmented Generation (RAG), exemplified by Bing Chat, marks an evolutionary leap in the search ecosystem. They demonstrate metacognitive abilities in interpreting web information and crafting responses with human-like understanding and creativity. Nonetheless, the intricate nature of LLMs renders their "cognitive" processes opaque, challenging even their designers' understanding. This research aims to dissect the mechanisms through which an LLM-powered chat-based search engine, specifically Bing Chat, selects information sources for its responses. To this end, an extensive dataset has been compiled through engagements with New Bing, documenting the websites it cites alongside those listed by the conventional search engine. Employing natural language processing (NLP) techniques, the research reveals that Bing Chat exhibits a preference for content that is not only readable and formally structured, but also demonstrates lower perplexity levels, indicating a unique inclination towards text that is predictable by the underlying LLM. Further enriching our analysis, we procure an additional dataset through interactions with the GPT-4 based knowledge retrieval API, unveiling a congruent text preference between the RAG API and Bing Chat. This consensus suggests that these text preferences intrinsically emerge from the underlying language models, rather than being explicitly crafted by Bing Chat's developers. Moreover, our investigation documents a greater similarity among websites cited by RAG technologies compared to those ranked highest by conventional search engines.
Partial Adversarial Domain Adaptation
Aug 10, 2018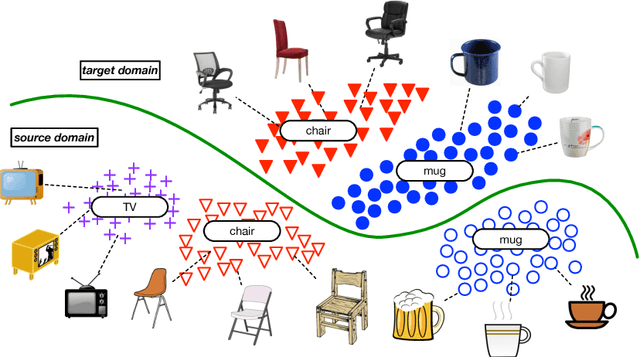

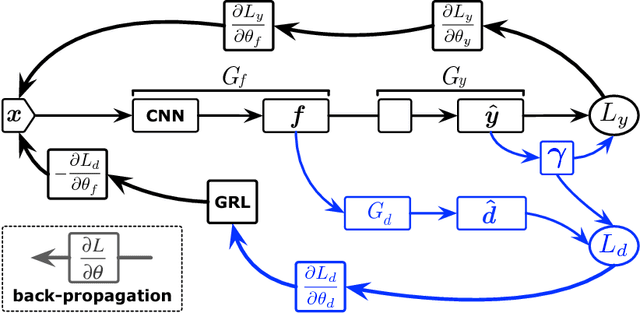
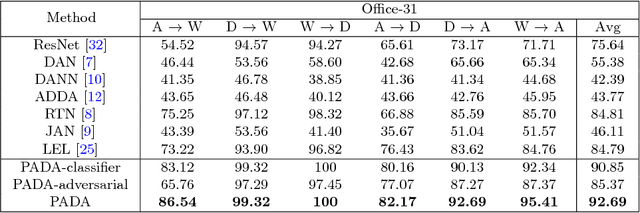
Domain adversarial learning aligns the feature distributions across the source and target domains in a two-player minimax game. Existing domain adversarial networks generally assume identical label space across different domains. In the presence of big data, there is strong motivation of transferring deep models from existing big domains to unknown small domains. This paper introduces partial domain adaptation as a new domain adaptation scenario, which relaxes the fully shared label space assumption to that the source label space subsumes the target label space. Previous methods typically match the whole source domain to the target domain, which are vulnerable to negative transfer for the partial domain adaptation problem due to the large mismatch between label spaces. We present Partial Adversarial Domain Adaptation (PADA), which simultaneously alleviates negative transfer by down-weighing the data of outlier source classes for training both source classifier and domain adversary, and promotes positive transfer by matching the feature distributions in the shared label space. Experiments show that PADA exceeds state-of-the-art results for partial domain adaptation tasks on several datasets.