 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Source Multimodal Moxin Models with Moxin-VLM and Moxin-VLA
Dec 22, 2025Recently, Large Language Models (LLMs) have undergone a significant transformation, marked by a rapid rise in both their popularity and capabilities. Leading this evolution are proprietary LLMs like GPT-4 and GPT-o1, which have captured widespread attention in the AI community due to their remarkable performance and versatility. Simultaneously, open-source LLMs, such as LLaMA and Mistral, have made great contributions to the ever-increasing popularity of LLMs due to the ease to customize and deploy the models across diverse applications. Moxin 7B is introduced as a fully open-source LLM developed in accordance with the Model Openness Framework, which moves beyond the simple sharing of model weights to embrace complete transparency in training, datasets, and implementation detail, thus fostering a more inclusive and collaborative research environment that can sustain a healthy open-source ecosystem. To further equip Moxin with various capabilities in different tasks, we develop three variants based on Moxin, including Moxin-VLM, Moxin-VLA, and Moxin-Chinese, which target the vision-language, vision-language-action, and Chinese capabilities, respectively. Experiments show that our models achieve superior performance in various evaluations. We adopt open-source framework and open data for the training. We release our models, along with the available data and code to derive these models.
OIDA-QA: A Multimodal Benchmark for Analyzing the Opioid Industry Documents Archive
Nov 14, 2025The opioid crisis represents a significant moment in public health that reveals systemic shortcomings across regulatory systems, healthcare practices, corporate governance, and public policy. Analyzing how these interconnected systems simultaneously failed to protect public health requires innovative analytic approaches for exploring the vast amounts of data and documents disclosed in the UCSF-JHU Opioid Industry Documents Archive (OIDA). The complexity, multimodal nature, and specialized characteristics of these healthcare-related legal and corporate documents necessitate more advanced methods and models tailored to specific data types and detailed annotations, ensuring the precision and professionalism in the analysis. In this paper, we tackle this challenge by organizing the original dataset according to document attributes and constructing a benchmark with 400k training documents and 10k for testing. From each document, we extract rich multimodal information-including textual content, visual elements, and layout structures-to capture a comprehensive range of features. Using multiple AI models, we then generate a large-scale dataset comprising 360k training QA pairs and 10k testing QA pairs. Building on this foundation, we develop domain-specific multimodal Large Language Models (LLMs) and explore the impact of multimodal inputs on task performance. To further enhance response accuracy, we incorporate historical QA pairs as contextual grounding for answering current queries. Additionally, we incorporate page references within the answers and introduce an importance-based page classifier, further improving the precision and relevance of the information provided. Preliminary results indicate the improvements with our AI assistant in document information extraction and question-answering tasks. The dataset is available at: https://huggingface.co/datasets/opioidarchive/oida-qa
TSLA: A Task-Specific Learning Adaptation for Semantic Segmentation on Autonomous Vehicles Platform
Aug 17, 2025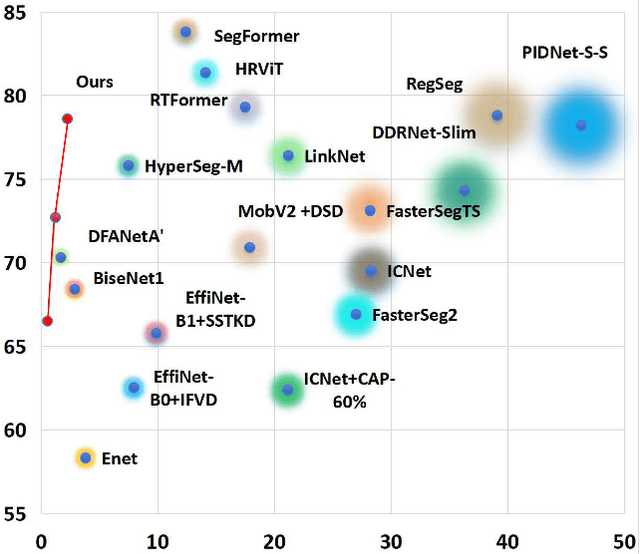
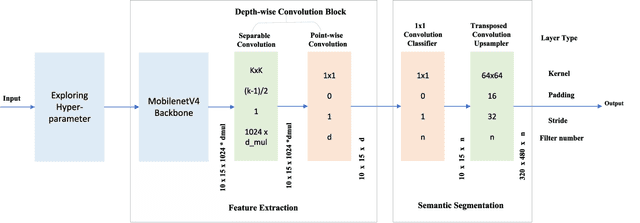
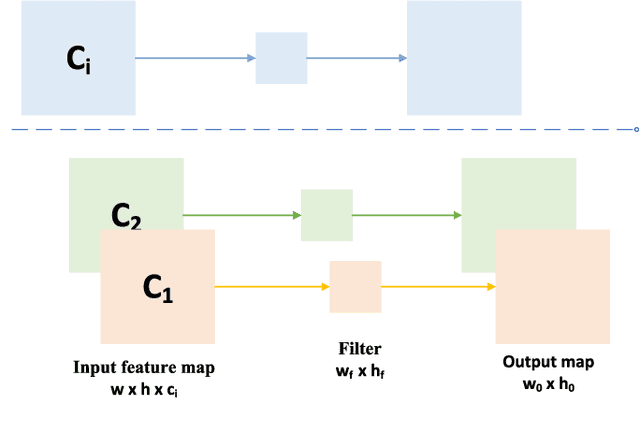
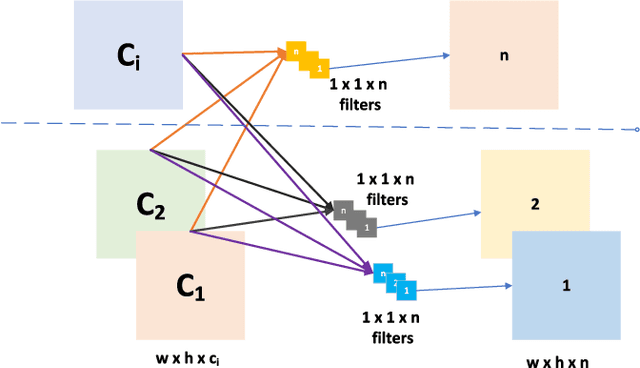
Autonomous driving platforms encounter diverse driving scenarios, each with varying hardware resources and precision requirements. Given the computational limitations of embedded devices, it is crucial to consider computing costs when deploying on target platforms like the NVIDIA\textsuperscript{\textregistered} DRIVE PX 2. Our objective is to customize the semantic segmentation network according to the computing power and specific scenarios of autonomous driving hardware. We implement dynamic adaptability through a three-tier control mechanism -- width multiplier, classifier depth, and classifier kernel -- allowing fine-grained control over model components based on hardware constraints and task requirements. This adaptability facilitates broad model scaling, targeted refinement of the final layers, and scenario-specific optimization of kernel sizes, leading to improved resource allocation and performance. Additionally, we leverage Bayesian Optimization with surrogate modeling to efficiently explore hyperparameter spaces under tight computational budgets. Our approach addresses scenario-specific and task-specific requirements through automatic parameter search, accommodating the unique computational complexity and accuracy needs of autonomous driving. It scales its Multiply-Accumulate Operations (MACs) for Task-Specific Learning Adaptation (TSLA), resulting in alternative configurations tailored to diverse self-driving tasks. These TSLA customizations maximize computational capacity and model accuracy, optimizing hardware utilization.
Enabling Flexible Multi-LLM Integration for Scalable Knowledge Aggregation
May 28, 2025



Large language models (LLMs) have shown remarkable promise but remain challenging to continually improve through traditional finetuning, particularly when integrating capabilities from other specialized LLMs. Popular methods like ensemble and weight merging require substantial memory and struggle to adapt to changing data environments. Recent efforts have transferred knowledge from multiple LLMs into a single target model; however, they suffer from interference and degraded performance among tasks, largely due to limited flexibility in candidate selection and training pipelines. To address these issues, we propose a framework that adaptively selects and aggregates knowledge from diverse LLMs to build a single, stronger model, avoiding the high memory overhead of ensemble and inflexible weight merging. Specifically, we design an adaptive selection network that identifies the most relevant source LLMs based on their scores, thereby reducing knowledge interference. We further propose a dynamic weighted fusion strategy that accounts for the inherent strengths of candidate LLMs, along with a feedback-driven loss function that prevents the selector from converging on a single subset of sources. Experimental results demonstrate that our method can enable a more stable and scalable knowledge aggregation process while reducing knowledge interference by up to 50% compared to existing approaches. Code is avaliable at https://github.com/ZLKong/LLM_Integration
QuartDepth: Post-Training Quantization for Real-Time Depth Estimation on the Edge
Mar 20, 2025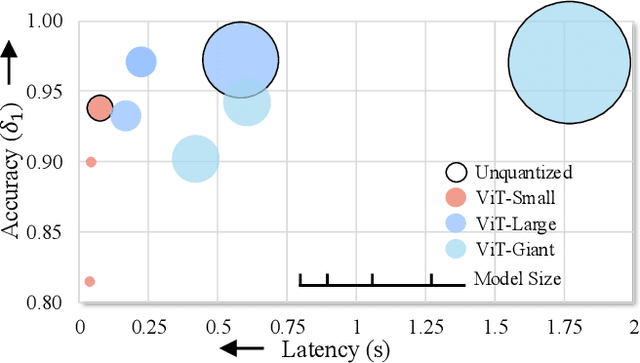
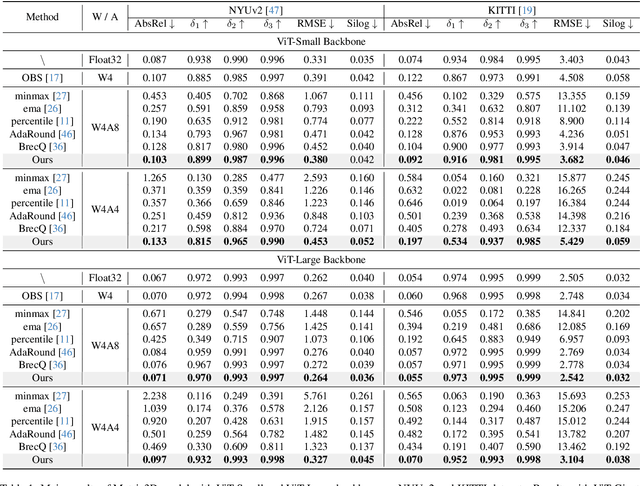
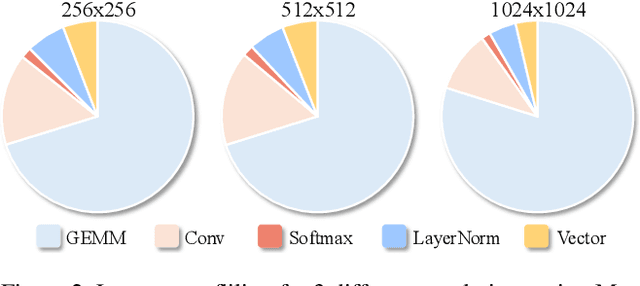
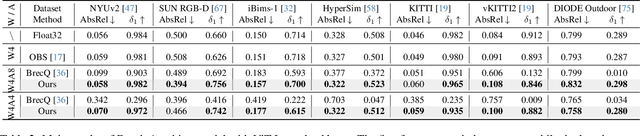
Monocular Depth Estimation (MDE) has emerged as a pivotal task in computer vision, supporting numerous real-world applications. However, deploying accurate depth estimation models on resource-limited edge devices, especially Application-Specific Integrated Circuits (ASICs), is challenging due to the high computational and memory demands. Recent advancements in foundational depth estimation deliver impressive results but further amplify the difficulty of deployment on ASICs. To address this, we propose QuartDepth which adopts post-training quantization to quantize MDE models with hardware accelerations for ASICs. Our approach involves quantizing both weights and activations to 4-bit precision, reducing the model size and computation cost. To mitigate the performance degradation, we introduce activation polishing and compensation algorithm applied before and after activation quantization, as well as a weight reconstruction method for minimizing errors in weight quantization. Furthermore, we design a flexible and programmable hardware accelerator by supporting kernel fusion and customized instruction programmability, enhancing throughput and efficiency. Experimental results demonstrate that our framework achieves competitive accuracy while enabling fast inference and higher energy efficiency on ASICs, bridging the gap between high-performance depth estimation and practical edge-device applicability. Code: https://github.com/shawnricecake/quart-depth
Efficient Reasoning with Hidden Thinking
Jan 31, 2025
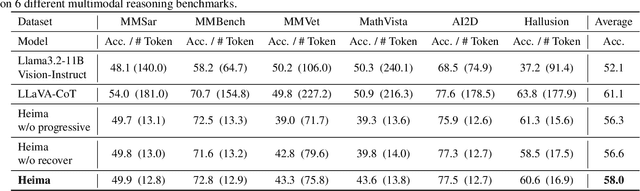


Chain-of-Thought (CoT) reasoning has become a powerful framework for improving complex problem-solving capabilities in Multimodal Large Language Models (MLLMs). However, the verbose nature of textual reasoning introduces significant inefficiencies. In this work, we propose $\textbf{Heima}$ (as hidden llama), an efficient reasoning framework that leverages reasoning CoTs at hidden latent space. We design the Heima Encoder to condense each intermediate CoT into a compact, higher-level hidden representation using a single thinking token, effectively minimizing verbosity and reducing the overall number of tokens required during the reasoning process. Meanwhile, we design corresponding Heima Decoder with traditional Large Language Models (LLMs) to adaptively interpret the hidden representations into variable-length textual sequence, reconstructing reasoning processes that closely resemble the original CoTs. Experimental results across diverse reasoning MLLM benchmarks demonstrate that Heima model achieves higher generation efficiency while maintaining or even better zero-shot task accuracy. Moreover, the effective reconstruction of multimodal reasoning processes with Heima Decoder validates both the robustness and interpretability of our approach.
RoRA: Efficient Fine-Tuning of LLM with Reliability Optimization for Rank Adaptation
Jan 08, 2025



Fine-tuning helps large language models (LLM) recover degraded information and enhance task performance.Although Low-Rank Adaptation (LoRA) is widely used and effective for fine-tuning, we have observed that its scaling factor can limit or even reduce performance as the rank size increases. To address this issue, we propose RoRA (Rank-adaptive Reliability Optimization), a simple yet effective method for optimizing LoRA's scaling factor. By replacing $\alpha/r$ with $\alpha/\sqrt{r}$, RoRA ensures improved performance as rank size increases. Moreover, RoRA enhances low-rank adaptation in fine-tuning uncompressed models and excels in the more challenging task of accuracy recovery when fine-tuning pruned models. Extensive experiments demonstrate the effectiveness of RoRA in fine-tuning both uncompressed and pruned models. RoRA surpasses the state-of-the-art (SOTA) in average accuracy and robustness on LLaMA-7B/13B, LLaMA2-7B, and LLaMA3-8B, specifically outperforming LoRA and DoRA by 6.5% and 2.9% on LLaMA-7B, respectively. In pruned model fine-tuning, RoRA shows significant advantages; for SHEARED-LLAMA-1.3, a LLaMA-7B with 81.4% pruning, RoRA achieves 5.7% higher average accuracy than LoRA and 3.9% higher than DoRA.
LazyDiT: Lazy Learning for the Acceleration of Diffusion Transformers
Dec 17, 2024Diffusion Transformers have emerged as the preeminent models for a wide array of generative tasks, demonstrating superior performance and efficacy across various applications. The promising results come at the cost of slow inference, as each denoising step requires running the whole transformer model with a large amount of parameters. In this paper, we show that performing the full computation of the model at each diffusion step is unnecessary, as some computations can be skipped by lazily reusing the results of previous steps. Furthermore, we show that the lower bound of similarity between outputs at consecutive steps is notably high, and this similarity can be linearly approximated using the inputs. To verify our demonstrations, we propose the \textbf{LazyDiT}, a lazy learning framework that efficiently leverages cached results from earlier steps to skip redundant computations. Specifically, we incorporate lazy learning layers into the model, effectively trained to maximize laziness, enabling dynamic skipping of redundant computations. Experimental results show that LazyDiT outperforms the DDIM sampler across multiple diffusion transformer models at various resolutions. Furthermore, we implement our method on mobile devices, achieving better performance than DDIM with similar latency.
Numerical Pruning for Efficient Autoregressive Models
Dec 17, 2024



Transformers have emerged as the leading architecture in deep learning, proving to be versatile and highly effective across diverse domains beyond language and image processing. However, their impressive performance often incurs high computational costs due to their substantial model size. This paper focuses on compressing decoder-only transformer-based autoregressive models through structural weight pruning to improve the model efficiency while preserving performance for both language and image generation tasks. Specifically, we propose a training-free pruning method that calculates a numerical score with Newton's method for the Attention and MLP modules, respectively. Besides, we further propose another compensation algorithm to recover the pruned model for better performance. To verify the effectiveness of our method, we provide both theoretical support and extensive experiments. Our experiments show that our method achieves state-of-the-art performance with reduced memory usage and faster generation speeds on GPUs.
Fully Open Source Moxin-7B Technical Report
Dec 08, 2024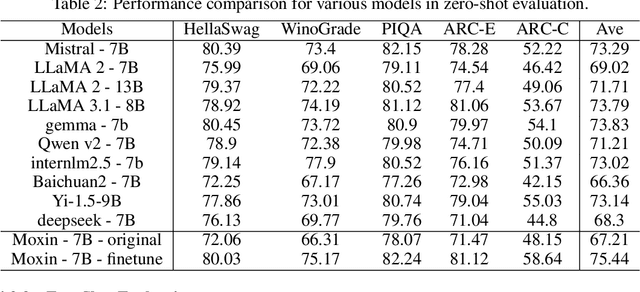
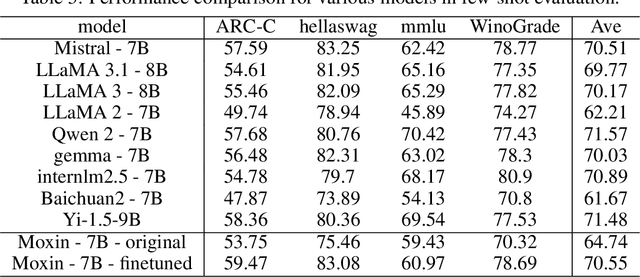


Recently, Large Language Models (LLMs) have undergone a significant transformation, marked by a rapid rise in both their popularity and capabilities. Leading this evolution are proprietary LLMs like GPT-4 and GPT-o1, which have captured widespread attention in the AI community due to their remarkable performance and versatility. Simultaneously, open-source LLMs, such as LLaMA and Mistral, have made great contributions to the ever-increasing popularity of LLMs due to the ease to customize and deploy the models across diverse applications. Although open-source LLMs present unprecedented opportunities for innovation and research, the commercialization of LLMs has raised concerns about transparency, reproducibility, and safety. Many open-source LLMs fail to meet fundamental transparency requirements by withholding essential components like training code and data, and some use restrictive licenses whilst claiming to be "open-source," which may hinder further innovations on LLMs. To mitigate this issue, we introduce Moxin 7B, a fully open-source LLM developed in accordance with the Model Openness Framework (MOF), a ranked classification system that evaluates AI models based on model completeness and openness, adhering to principles of open science, open source, open data, and open access. Our model achieves the highest MOF classification level of "open science" through the comprehensive release of pre-training code and configurations, training and fine-tuning datasets, and intermediate and final checkpoints. Experiments show that our model achieves superior performance in zero-shot evaluation compared with popular 7B models and performs competitively in few-shot evaluation.