 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Reasoning with Hidden Thinking
Jan 31, 2025
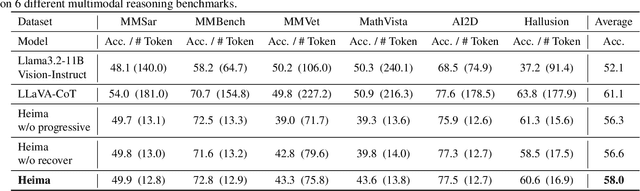


Chain-of-Thought (CoT) reasoning has become a powerful framework for improving complex problem-solving capabilities in Multimodal Large Language Models (MLLMs). However, the verbose nature of textual reasoning introduces significant inefficiencies. In this work, we propose $\textbf{Heima}$ (as hidden llama), an efficient reasoning framework that leverages reasoning CoTs at hidden latent space. We design the Heima Encoder to condense each intermediate CoT into a compact, higher-level hidden representation using a single thinking token, effectively minimizing verbosity and reducing the overall number of tokens required during the reasoning process. Meanwhile, we design corresponding Heima Decoder with traditional Large Language Models (LLMs) to adaptively interpret the hidden representations into variable-length textual sequence, reconstructing reasoning processes that closely resemble the original CoTs. Experimental results across diverse reasoning MLLM benchmarks demonstrate that Heima model achieves higher generation efficiency while maintaining or even better zero-shot task accuracy. Moreover, the effective reconstruction of multimodal reasoning processes with Heima Decoder validates both the robustness and interpretability of our approach.
Hijacking Vision-and-Language Navigation Agents with Adversarial Environmental Attacks
Dec 03, 2024
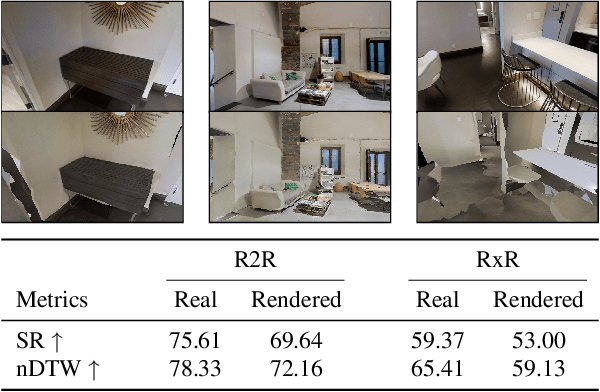


Assistive embodied agents that can be instructed in natural language to perform tasks in open-world environments have the potential to significantly impact labor tasks like manufacturing or in-home care -- benefiting the lives of those who come to depend on them. In this work, we consider how this benefit might be hijacked by local modifications in the appearance of the agent's operating environment. Specifically, we take the popular Vision-and-Language Navigation (VLN) task as a representative setting and develop a whitebox adversarial attack that optimizes a 3D attack object's appearance to induce desired behaviors in pretrained VLN agents that observe it in the environment. We demonstrate that the proposed attack can cause VLN agents to ignore their instructions and execute alternative actions after encountering the attack object -- even for instructions and agent paths not considered when optimizing the attack. For these novel settings, we find our attacks can induce early-termination behaviors or divert an agent along an attacker-defined multi-step trajectory. Under both conditions, environmental attacks significantly reduce agent capabilities to successfully follow user instructions.
Learning Meta-class Memory for Few-Shot Semantic Segmentation
Aug 16, 2021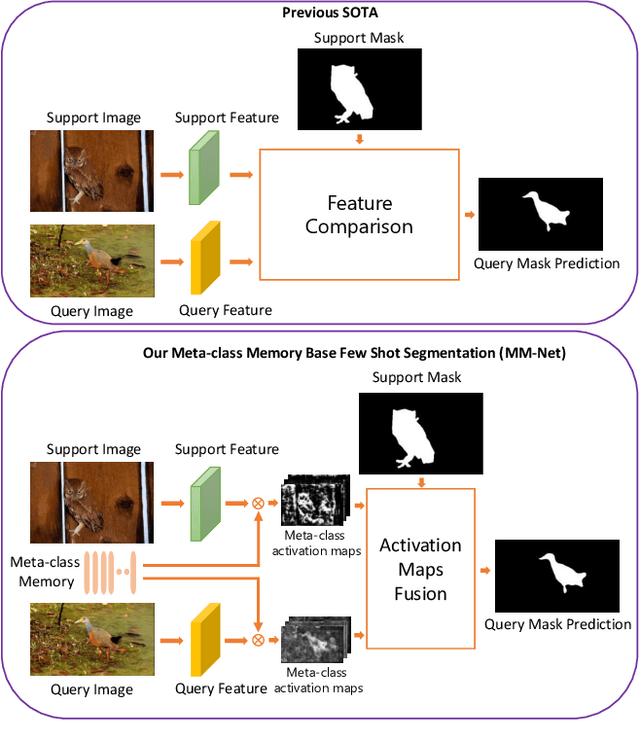



Currently, the state-of-the-art methods treat few-shot semantic segmentation task as a conditional foreground-background segmentation problem, assuming each class is independent. In this paper, we introduce the concept of meta-class, which is the meta information (e.g. certain middle-level features) shareable among all classes. To explicitly learn meta-class representations in few-shot segmentation task, we propose a novel Meta-class Memory based few-shot segmentation method (MM-Net), where we introduce a set of learnable memory embeddings to memorize the meta-class information during the base class training and transfer to novel classes during the inference stage. Moreover, for the $k$-shot scenario, we propose a novel image quality measurement module to select images from the set of support images. A high-quality class prototype could be obtained with the weighted sum of support image features based on the quality measure. Experiments on both PASCAL-$5^i$ and COCO dataset shows that our proposed method is able to achieve state-of-the-art results in both 1-shot and 5-shot settings. Particularly, our proposed MM-Net achieves 37.5\% mIoU on the COCO dataset in 1-shot setting, which is 5.1\% higher than the previous state-of-the-art.
Remember What You have drawn: Semantic Image Manipulation with Memory
Jul 27, 2021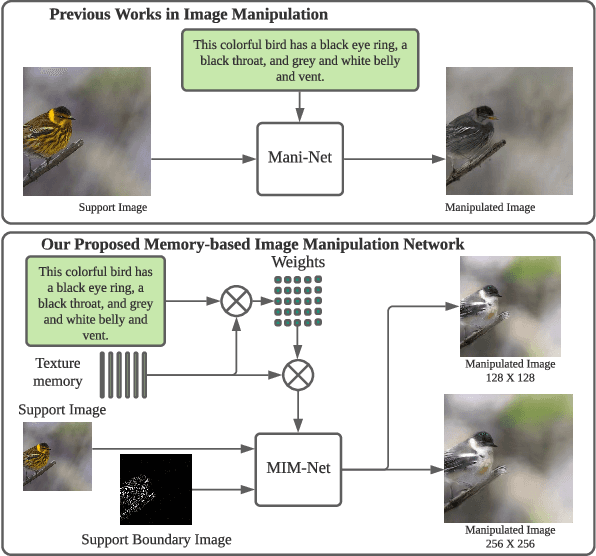



Image manipulation with natural language, which aims to manipulate images with the guidance of language descriptions, has been a challenging problem in the fields of computer vision and natural language processing (NLP). Currently, a number of efforts have been made for this task, but their performances are still distant away from generating realistic and text-conformed manipulated images. Therefore, in this paper, we propose a memory-based Image Manipulation Network (MIM-Net), where a set of memories learned from images is introduced to synthesize the texture information with the guidance of the textual description. We propose a two-stage network with an additional reconstruction stage to learn the latent memories efficiently. To avoid the unnecessary background changes, we propose a Target Localization Unit (TLU) to focus on the manipulation of the region mentioned by the text. Moreover, to learn a robust memory, we further propose a novel randomized memory training loss. Experiments on the four popular datasets show the better performance of our method compared to the existing ones.
Finding It at Another Side: A Viewpoint-Adapted Matching Encoder for Change Captioning
Sep 30, 2020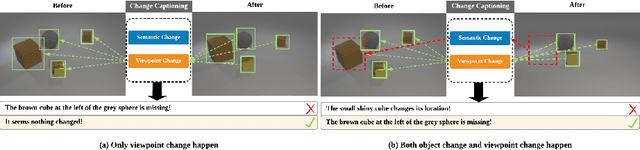
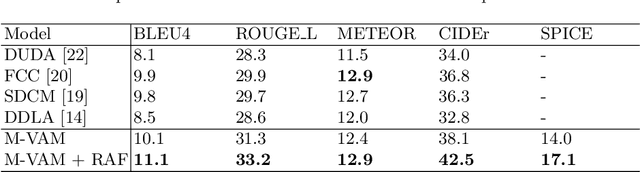
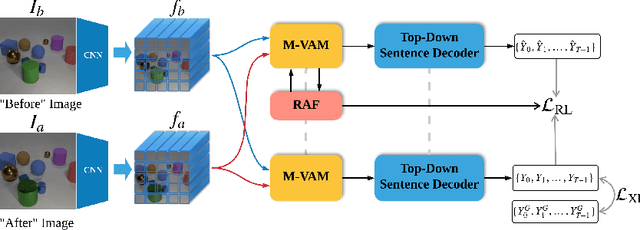

Change Captioning is a task that aims to describe the difference between images with natural language. Most existing methods treat this problem as a difference judgment without the existence of distractors, such as viewpoint changes. However, in practice, viewpoint changes happen often and can overwhelm the semantic difference to be described. In this paper, we propose a novel visual encoder to explicitly distinguish viewpoint changes from semantic changes in the change captioning task. Moreover, we further simulate the attention preference of humans and propose a novel reinforcement learning process to fine-tune the attention directly with language evaluation rewards. Extensive experimental results show that our method outperforms the state-of-the-art approaches by a large margin in both Spot-the-Diff and CLEVR-Change datasets.
Watch It Twice: Video Captioning with a Refocused Video Encoder
Jul 21, 2019
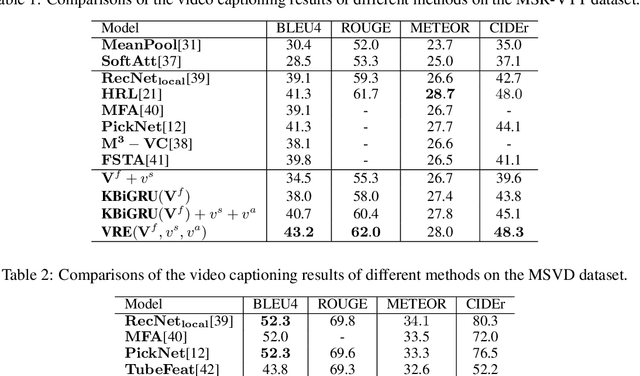
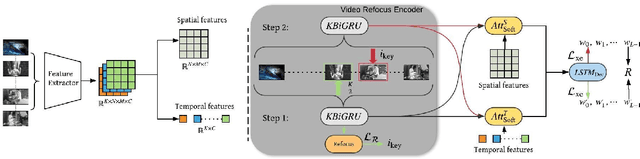

With the rapid growth of video data and the increasing demands of various applications such as intelligent video search and assistance toward visually-impaired people, video captioning task has received a lot of attention recently in computer vision and natural language processing fields. The state-of-the-art video captioning methods focus more on encoding the temporal information, while lack of effective ways to remove irrelevant temporal information and also neglecting the spatial details. However, the current RNN encoding module in single time order can be influenced by the irrelevant temporal information, especially the irrelevant temporal information is at the beginning of the encoding. In addition, neglecting spatial information will lead to the relationship confusion of the words and detailed loss. Therefore, in this paper, we propose a novel recurrent video encoding method and a novel visual spatial feature for the video captioning task. The recurrent encoding module encodes the video twice with the predicted key frame to avoid the irrelevant temporal information often occurring at the beginning and the end of a video. The novel spatial features represent the spatial information in different regions of a video and enrich the details of a caption. Experiments on two benchmark datasets show superior performance of the proposed method.
Video Captioning with Boundary-aware Hierarchical Language Decoding and Joint Video Prediction
Jul 08, 2018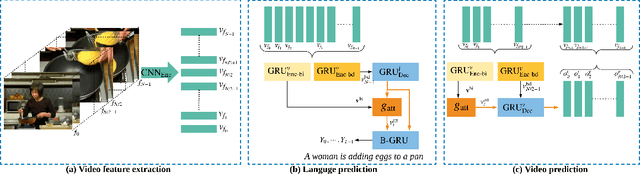



The explosion of video data on the internet requires effective and efficient technology to generate captions automatically for people who are not able to watch the videos. Despite the great progress of video captioning research, particularly on video feature encoding, the language decoder is still largely based on the prevailing RNN decoder such as LSTM, which tends to prefer the frequent word that aligns with the video. In this paper, we propose a boundary-aware hierarchical language decoder for video captioning, which consists of a high-level GRU based language decoder, working as a global (caption-level) language model, and a low-level GRU based language decoder, working as a local (phrase-level) language model. Most importantly, we introduce a binary gate into the low-level GRU language decoder to detect the language boundaries. Together with other advanced components including joint video prediction, shared soft attention, and boundary-aware video encoding, our integrated video captioning framework can discover hierarchical language information and distinguish the subject and the object in a sentence, which are usually confusing during the language generation. Extensive experiments on two widely-used video captioning datasets, MSR-Video-to-Text (MSR-VTT) \cite{xu2016msr} and YouTube-to-Text (MSVD) \cite{chen2011collecting} show that our method is highly competitive, compared with the state-of-the-art methods.