 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirect Translation between Sign Languages
May 20, 2026The field of sign language translation has witnessed significant progress in the translation between sign and spoken languages, but the translation between sign languages remains largely unexplored and out of reach. The latter can help 1.5 billion deaf and hard-of-hearing (DHH) people worldwide communicate across language barriers without relying on hearing interpreters or written-language fluency. The cascade approach composing separate sign-to-text, text-to-text, and text-to-sign systems suffers from error propagation and extra latency as well as the loss of information unique in the visual modality. We aim to develop direct sign-to-sign translation. However, a large-scale open-domain parallel corpus has not been curated between sign languages. To enable direct translation between sign language utterances, we use back-translation to produce synthetic sign-sign pairs from unaligned individual language utterance-sign corpora. Using this data, we jointly train a single MBART-based model for both text->sign (T2S) and sign->sign (S2S). On synthetically generated paired sets between American Sign Language (ASL), Chinese Sign Language (CSL), and German Sign Language (DGS), our direct S2S method outperforms the cascaded baseline on geometric sign error metrics (20% lower DTW-aligned MPJPE) and language matching metrics after predicted sign utterances are translated back to sentences (50% high BLEU-4) while achieving a roughly 2.3* speedup. On a small set of pre-existing cross-lingual sign data, we find similar improvements for our proposed method.
Learning Hybrid-Control Policies for High-Precision In-Contact Manipulation Under Uncertainty
Apr 21, 2026Reinforcement learning-based control policies have been frequently demonstrated to be more effective than analytical techniques for many manipulation tasks. Commonly, these methods learn neural control policies that predict end-effector pose changes directly from observed state information. For tasks like inserting delicate connectors which induce force constraints, pose-based policies have limited explicit control over force and rely on carefully tuned low-level controllers to avoid executing damaging actions. In this work, we present hybrid position-force control policies that learn to dynamically select when to use force or position control in each control dimension. To improve learning efficiency of these policies, we introduce Mode-Aware Training for Contact Handling (MATCH) which adjusts policy action probabilities to explicitly mirror the mode selection behavior in hybrid control. We validate MATCH's learned policy effectiveness using fragile peg-in-hole tasks under extreme localization uncertainty. We find MATCH substantially outperforms pose-control policies -- solving these tasks with up to 10% higher success rates and 5x fewer peg breaks than pose-only policies under common types of state estimation error. MATCH also demonstrates data efficiency equal to pose-control policies, despite learning in a larger and more complex action space. In over 1600 sim-to-real experiments, we find MATCH succeeds twice as often as pose policies in high noise settings (33% vs.~68%) and applies ~30% less force on average compared to variable impedance policies on a Franka FR3 in laboratory conditions.
Grounding Vision and Language to 3D Masks for Long-Horizon Box Rearrangement
Mar 24, 2026We study long-horizon planning in 3D environments from under-specified natural-language goals using only visual observations, focusing on multi-step 3D box rearrangement tasks. Existing approaches typically rely on symbolic planners with brittle relational grounding of states and goals, or on direct action-sequence generation from 2D vision-language models (VLMs). Both approaches struggle with reasoning over many objects, rich 3D geometry, and implicit semantic constraints. Recent advances in 3D VLMs demonstrate strong grounding of natural-language referents to 3D segmentation masks, suggesting the potential for more general planning capabilities. We extend existing 3D grounding models and propose Reactive Action Mask Planner (RAMP-3D), which formulates long-horizon planning as sequential reactive prediction of paired 3D masks: a "which-object" mask indicating what to pick and a "which-target-region" mask specifying where to place it. The resulting system processes RGB-D observations and natural-language task specifications to reactively generate multi-step pick-and-place actions for 3D box rearrangement. We conduct experiments across 11 task variants in warehouse-style environments with 1-30 boxes and diverse natural-language constraints. RAMP-3D achieves 79.5% success rate on long-horizon rearrangement tasks and significantly outperforms 2D VLM-based baselines, establishing mask-based reactive policies as a promising alternative to symbolic pipelines for long-horizon planning.
Humanoid Hanoi: Investigating Shared Whole-Body Control for Skill-Based Box Rearrangement
Feb 14, 2026We investigate a skill-based framework for humanoid box rearrangement that enables long-horizon execution by sequencing reusable skills at the task level. In our architecture, all skills execute through a shared, task-agnostic whole-body controller (WBC), providing a consistent closed-loop interface for skill composition, in contrast to non-shared designs that use separate low-level controllers per skill. We find that naively reusing the same pretrained WBC can reduce robustness over long horizons, as new skills and their compositions induce shifted state and command distributions. We address this with a simple data aggregation procedure that augments shared-WBC training with rollouts from closed-loop skill execution under domain randomization. To evaluate the approach, we introduce \emph{Humanoid Hanoi}, a long-horizon Tower-of-Hanoi box rearrangement benchmark, and report results in simulation and on the Digit V3 humanoid robot, demonstrating fully autonomous rearrangement over extended horizons and quantifying the benefits of the shared-WBC approach over non-shared baselines.
Calibrating MLLM-as-a-judge via Multimodal Bayesian Prompt Ensembles
Sep 10, 2025Multimodal large language models (MLLMs) are increasingly used to evaluate text-to-image (TTI) generation systems, providing automated judgments based on visual and textual context. However, these "judge" models often suffer from biases, overconfidence, and inconsistent performance across diverse image domains. While prompt ensembling has shown promise for mitigating these issues in unimodal, text-only settings, our experiments reveal that standard ensembling methods fail to generalize effectively for TTI tasks. To address these limitations, we propose a new multimodal-aware method called Multimodal Mixture-of-Bayesian Prompt Ensembles (MMB). Our method uses a Bayesian prompt ensemble approach augmented by image clustering, allowing the judge to dynamically assign prompt weights based on the visual characteristics of each sample. We show that MMB improves accuracy in pairwise preference judgments and greatly enhances calibration, making it easier to gauge the judge's true uncertainty. In evaluations on two TTI benchmarks, HPSv2 and MJBench, MMB outperforms existing baselines in alignment with human annotations and calibration across varied image content. Our findings highlight the importance of multimodal-specific strategies for judge calibration and suggest a promising path forward for reliable large-scale TTI evaluation.
Towards Scalable Schema Mapping using Large Language Models
May 30, 2025



The growing need to integrate information from a large number of diverse sources poses significant scalability challenges for data integration systems. These systems often rely on manually written schema mappings, which are complex, source-specific, and costly to maintain as sources evolve. While recent advances suggest that large language models (LLMs) can assist in automating schema matching by leveraging both structural and natural language cues, key challenges remain. In this paper, we identify three core issues with using LLMs for schema mapping: (1) inconsistent outputs due to sensitivity to input phrasing and structure, which we propose methods to address through sampling and aggregation techniques; (2) the need for more expressive mappings (e.g., GLaV), which strain the limited context windows of LLMs; and (3) the computational cost of repeated LLM calls, which we propose to mitigate through strategies like data type prefiltering.
Do Visual Imaginations Improve Vision-and-Language Navigation Agents?
Mar 20, 2025
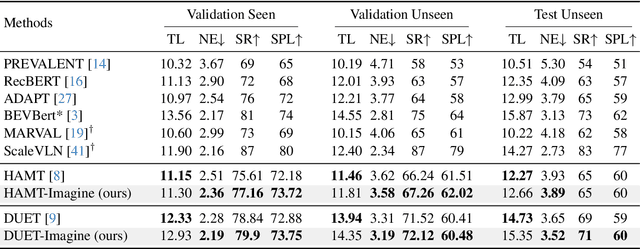

Vision-and-Language Navigation (VLN) agents are tasked with navigating an unseen environment using natural language instructions. In this work, we study if visual representations of sub-goals implied by the instructions can serve as navigational cues and lead to increased navigation performance. To synthesize these visual representations or imaginations, we leverage a text-to-image diffusion model on landmark references contained in segmented instructions. These imaginations are provided to VLN agents as an added modality to act as landmark cues and an auxiliary loss is added to explicitly encourage relating these with their corresponding referring expressions. Our findings reveal an increase in success rate (SR) of around 1 point and up to 0.5 points in success scaled by inverse path length (SPL) across agents. These results suggest that the proposed approach reinforces visual understanding compared to relying on language instructions alone. Code and data for our work can be found at https://www.akhilperincherry.com/VLN-Imagine-website/.
GABAR: Graph Attention-Based Action Ranking for Relational Policy Learning
Dec 06, 2024We propose a novel approach to learn relational policies for classical planning based on learning to rank actions. We introduce a new graph representation that explicitly captures action information and propose a Graph Neural Network architecture augmented with Gated Recurrent Units (GRUs) to learn action rankings. Our model is trained on small problem instances and generalizes to significantly larger instances where traditional planning becomes computationally expensive. Experimental results across standard planning benchmarks demonstrate that our action-ranking approach achieves generalization to significantly larger problems than those used in training.
Hijacking Vision-and-Language Navigation Agents with Adversarial Environmental Attacks
Dec 03, 2024
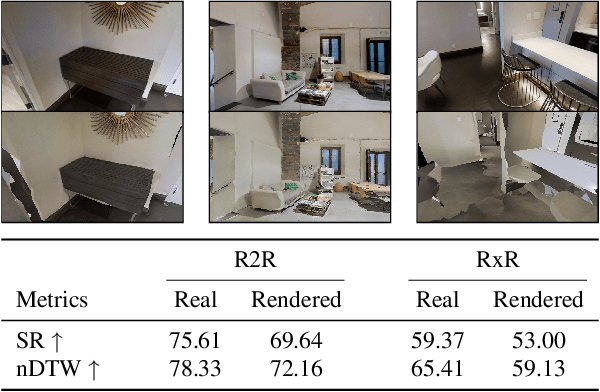


Assistive embodied agents that can be instructed in natural language to perform tasks in open-world environments have the potential to significantly impact labor tasks like manufacturing or in-home care -- benefiting the lives of those who come to depend on them. In this work, we consider how this benefit might be hijacked by local modifications in the appearance of the agent's operating environment. Specifically, we take the popular Vision-and-Language Navigation (VLN) task as a representative setting and develop a whitebox adversarial attack that optimizes a 3D attack object's appearance to induce desired behaviors in pretrained VLN agents that observe it in the environment. We demonstrate that the proposed attack can cause VLN agents to ignore their instructions and execute alternative actions after encountering the attack object -- even for instructions and agent paths not considered when optimizing the attack. For these novel settings, we find our attacks can induce early-termination behaviors or divert an agent along an attacker-defined multi-step trajectory. Under both conditions, environmental attacks significantly reduce agent capabilities to successfully follow user instructions.
You Never Know: Quantization Induces Inconsistent Biases in Vision-Language Foundation Models
Oct 26, 2024We study the impact of a standard practice in compressing foundation vision-language models - quantization - on the models' ability to produce socially-fair outputs. In contrast to prior findings with unimodal models that compression consistently amplifies social biases, our extensive evaluation of four quantization settings across three datasets and three CLIP variants yields a surprising result: while individual models demonstrate bias, we find no consistent change in bias magnitude or direction across a population of compressed models due to quantization.