 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal-to-Global Logical Explanations for Deep Vision Models
Jan 19, 2026While deep neural networks are extremely effective at classifying images, they remain opaque and hard to interpret. We introduce local and global explanation methods for black-box models that generate explanations in terms of human-recognizable primitive concepts. Both the local explanations for a single image and the global explanations for a set of images are cast as logical formulas in monotone disjunctive-normal-form (MDNF), whose satisfaction guarantees that the model yields a high score on a given class. We also present an algorithm for explaining the classification of examples into multiple classes in the form of a monotone explanation list over primitive concepts. Despite their simplicity and interpretability we show that the explanations maintain high fidelity and coverage with respect to the blackbox models they seek to explain in challenging vision datasets.
* 15 pages, 5 figures, 5th International Joint Conference on Learning & Reasoning 2025
Generating Part-Based Global Explanations Via Correspondence
Sep 18, 2025Deep learning models are notoriously opaque. Existing explanation methods often focus on localized visual explanations for individual images. Concept-based explanations, while offering global insights, require extensive annotations, incurring significant labeling cost. We propose an approach that leverages user-defined part labels from a limited set of images and efficiently transfers them to a larger dataset. This enables the generation of global symbolic explanations by aggregating part-based local explanations, ultimately providing human-understandable explanations for model decisions on a large scale.
Self-attention-based Diffusion Model for Time-series Imputation in Partial Blackout Scenarios
Mar 03, 2025Missing values in multivariate time series data can harm machine learning performance and introduce bias. These gaps arise from sensor malfunctions, blackouts, and human error and are typically addressed by data imputation. Previous work has tackled the imputation of missing data in random, complete blackouts and forecasting scenarios. The current paper addresses a more general missing pattern, which we call "partial blackout," where a subset of features is missing for consecutive time steps. We introduce a two-stage imputation process using self-attention and diffusion processes to model feature and temporal correlations. Notably, our model effectively handles missing data during training, enhancing adaptability and ensuring reliable imputation and performance, even with incomplete datasets. Our experiments on benchmark and two real-world time series datasets demonstrate that our model outperforms the state-of-the-art in partial blackout scenarios and shows better scalability.
Combining Planning and Reinforcement Learning for Solving Relational Multiagent Domains
Feb 26, 2025Multiagent Reinforcement Learning (MARL) poses significant challenges due to the exponential growth of state and action spaces and the non-stationary nature of multiagent environments. This results in notable sample inefficiency and hinders generalization across diverse tasks. The complexity is further pronounced in relational settings, where domain knowledge is crucial but often underutilized by existing MARL algorithms. To overcome these hurdles, we propose integrating relational planners as centralized controllers with efficient state abstractions and reinforcement learning. This approach proves to be sample-efficient and facilitates effective task transfer and generalization.
GABAR: Graph Attention-Based Action Ranking for Relational Policy Learning
Dec 06, 2024We propose a novel approach to learn relational policies for classical planning based on learning to rank actions. We introduce a new graph representation that explicitly captures action information and propose a Graph Neural Network architecture augmented with Gated Recurrent Units (GRUs) to learn action rankings. Our model is trained on small problem instances and generalizes to significantly larger instances where traditional planning becomes computationally expensive. Experimental results across standard planning benchmarks demonstrate that our action-ranking approach achieves generalization to significantly larger problems than those used in training.
Hierarchical Object-Oriented POMDP Planning for Object Rearrangement
Dec 02, 2024



We present an online planning framework for solving multi-object rearrangement problems in partially observable, multi-room environments. Current object rearrangement solutions, primarily based on Reinforcement Learning or hand-coded planning methods, often lack adaptability to diverse challenges. To address this limitation, we introduce a novel Hierarchical Object-Oriented Partially Observed Markov Decision Process (HOO-POMDP) planning approach. This approach comprises of (a) an object-oriented POMDP planner generating sub-goals, (b) a set of low-level policies for sub-goal achievement, and (c) an abstraction system converting the continuous low-level world into a representation suitable for abstract planning. We evaluate our system on varying numbers of objects, rooms, and problem types in AI2-THOR simulated environments with promising results.
Chess Rating Estimation from Moves and Clock Times Using a CNN-LSTM
Sep 17, 2024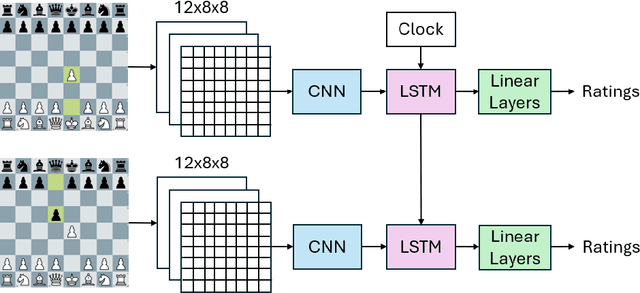
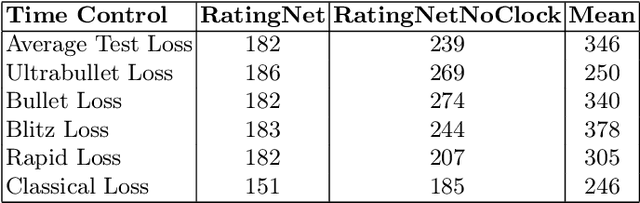
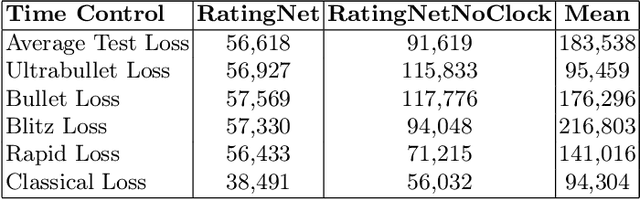
Current rating systems update ratings incrementally and may not always accurately reflect a player's true strength at all times, especially for rapidly improving players or very rusty players. To overcome this, we explore a method to estimate player ratings directly from game moves and clock times. We compiled a benchmark dataset from Lichess, encompassing various time controls and including move sequences and clock times. Our model architecture comprises a CNN to learn positional features, which are then integrated with clock-time data into a bidirectional LSTM, predicting player ratings after each move. The model achieved an MAE of 182 rating points in the test data. Additionally, we applied our model to the 2024 IEEE Big Data Cup Chess Puzzle Difficulty Competition dataset, predicted puzzle ratings and achieved competitive results. This model is the first to use no hand-crafted features to estimate chess ratings and also the first to output a rating prediction for each move. Our method highlights the potential of using move-based rating estimation for enhancing rating systems and potentially other applications such as cheating detection.
Language-Informed Beam Search Decoding for Multilingual Machine Translation
Aug 11, 2024Beam search decoding is the de-facto method for decoding auto-regressive Neural Machine Translation (NMT) models, including multilingual NMT where the target language is specified as an input. However, decoding multilingual NMT models commonly produces ``off-target'' translations -- yielding translation outputs not in the intended language. In this paper, we first conduct an error analysis of off-target translations for a strong multilingual NMT model and identify how these decodings are produced during beam search. We then propose Language-informed Beam Search (LiBS), a general decoding algorithm incorporating an off-the-shelf Language Identification (LiD) model into beam search decoding to reduce off-target translations. LiBS is an inference-time procedure that is NMT-model agnostic and does not require any additional parallel data. Results show that our proposed LiBS algorithm on average improves +1.1 BLEU and +0.9 BLEU on WMT and OPUS datasets, and reduces off-target rates from 22.9\% to 7.7\% and 65.8\% to 25.3\% respectively.
Adversarial Attacks on Combinatorial Multi-Armed Bandits
Oct 08, 2023We study reward poisoning attacks on Combinatorial Multi-armed Bandits (CMAB). We first provide a sufficient and necessary condition for the attackability of CMAB, which depends on the intrinsic properties of the corresponding CMAB instance such as the reward distributions of super arms and outcome distributions of base arms. Additionally, we devise an attack algorithm for attackable CMAB instances. Contrary to prior understanding of multi-armed bandits, our work reveals a surprising fact that the attackability of a specific CMAB instance also depends on whether the bandit instance is known or unknown to the adversary. This finding indicates that adversarial attacks on CMAB are difficult in practice and a general attack strategy for any CMAB instance does not exist since the environment is mostly unknown to the adversary. We validate our theoretical findings via extensive experiments on real-world CMAB applications including probabilistic maximum covering problem, online minimum spanning tree, cascading bandits for online ranking, and online shortest path.
Parametrically Retargetable Decision-Makers Tend To Seek Power
Jun 27, 2022

If capable AI agents are generally incentivized to seek power in service of the objectives we specify for them, then these systems will pose enormous risks, in addition to enormous benefits. In fully observable environments, most reward functions have an optimal policy which seeks power by keeping options open and staying alive. However, the real world is neither fully observable, nor will agents be perfectly optimal. We consider a range of models of AI decision-making, from optimal, to random, to choices informed by learning and interacting with an environment. We discover that many decision-making functions are retargetable, and that retargetability is sufficient to cause power-seeking tendencies. Our functional criterion is simple and broad. We show that a range of qualitatively dissimilar decision-making procedures incentivize agents to seek power. We demonstrate the flexibility of our results by reasoning about learned policy incentives in Montezuma's Revenge. These results suggest a safety risk: Eventually, highly retargetable training procedures may train real-world agents which seek power over humans.