 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePromoting Research Collaboration with Open Data Driven Team Recommendation in Response to Call for Proposals
Sep 27, 2023Building teams and promoting collaboration are two very common business activities. An example of these are seen in the TeamingForFunding problem, where research institutions and researchers are interested to identify collaborative opportunities when applying to funding agencies in response to latter's calls for proposals. We describe a novel system to recommend teams using a variety of AI methods, such that (1) each team achieves the highest possible skill coverage that is demanded by the opportunity, and (2) the workload of distributing the opportunities is balanced amongst the candidate members. We address these questions by extracting skills latent in open data of proposal calls (demand) and researcher profiles (supply), normalizing them using taxonomies, and creating efficient algorithms that match demand to supply. We create teams to maximize goodness along a novel metric balancing short- and long-term objectives. We validate the success of our algorithms (1) quantitatively, by evaluating the recommended teams using a goodness score and find that more informed methods lead to recommendations of smaller number of teams but higher goodness, and (2) qualitatively, by conducting a large-scale user study at a college-wide level, and demonstrate that users overall found the tool very useful and relevant. Lastly, we evaluate our system in two diverse settings in US and India (of researchers and proposal calls) to establish generality of our approach, and deploy it at a major US university for routine use.
Knowledge-based Refinement of Scientific Publication Knowledge Graphs
Sep 10, 2023
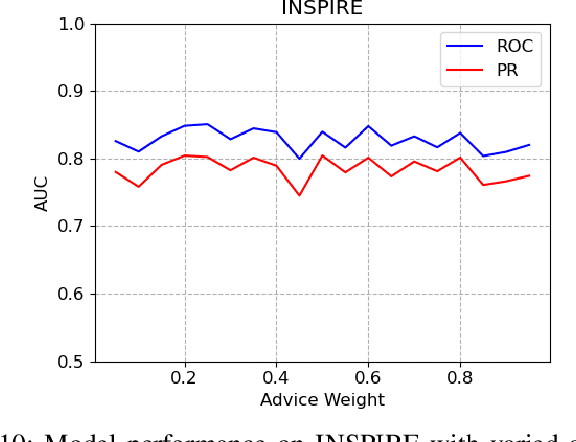
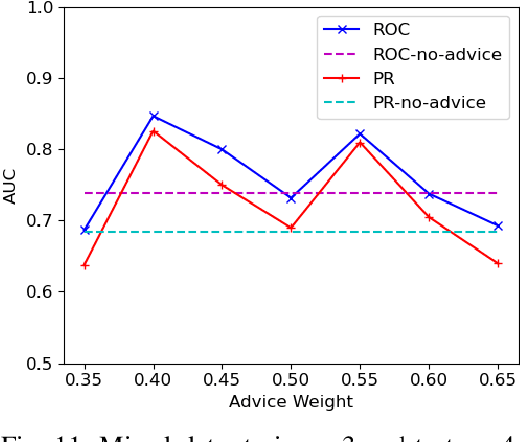
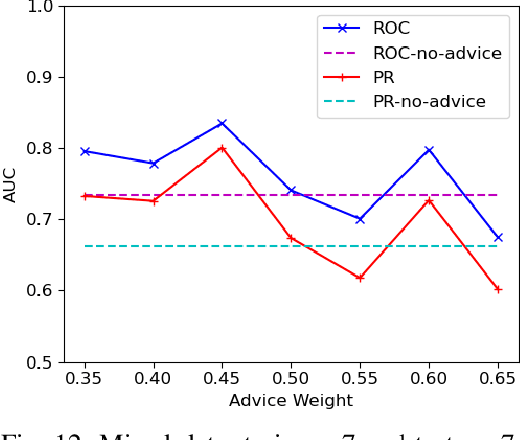
We consider the problem of identifying authorship by posing it as a knowledge graph construction and refinement. To this effect, we model this problem as learning a probabilistic logic model in the presence of human guidance (knowledge-based learning). Specifically, we learn relational regression trees using functional gradient boosting that outputs explainable rules. To incorporate human knowledge, advice in the form of first-order clauses is injected to refine the trees. We demonstrate the usefulness of human knowledge both quantitatively and qualitatively in seven authorship domains.
ToupleGDD: A Fine-Designed Solution of Influence Maximization by Deep Reinforcement Learning
Oct 18, 2022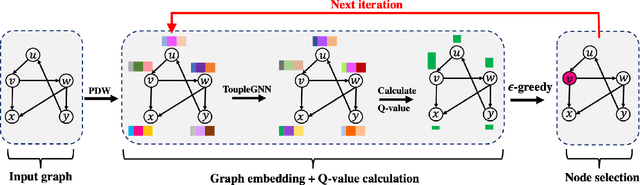

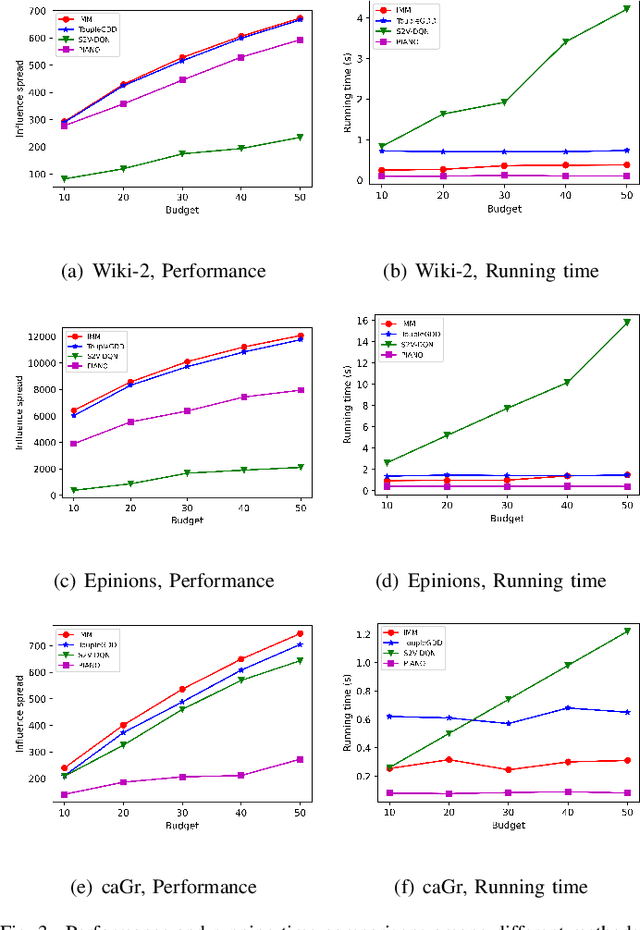

Online social platforms have become more and more popular, and the dissemination of information on social networks has attracted wide attention of the industries and academia. Aiming at selecting a small subset of nodes with maximum influence on networks, the Influence Maximization (IM) problem has been extensively studied. Since it is #P-hard to compute the influence spread given a seed set, the state-of-art methods, including heuristic and approximation algorithms, faced with great difficulties such as theoretical guarantee, time efficiency, generalization, etc. This makes it unable to adapt to large-scale networks and more complex applications. With the latest achievements of Deep Reinforcement Learning (DRL) in artificial intelligence and other fields, a lot of works has focused on exploiting DRL to solve the combinatorial optimization problems. Inspired by this, we propose a novel end-to-end DRL framework, ToupleGDD, to address the IM problem in this paper, which incorporates three coupled graph neural networks for network embedding and double deep Q-networks for parameters learning. Previous efforts to solve the IM problem with DRL trained their models on the subgraph of the whole network, and then tested their performance on the whole graph, which makes the performance of their models unstable among different networks. However, our model is trained on several small randomly generated graphs and tested on completely different networks, and can obtain results that are very close to the state-of-the-art methods. In addition, our model is trained with a small budget, and it can perform well under various large budgets in the test, showing strong generalization ability. Finally, we conduct entensive experiments on synthetic and realistic datasets, and the experimental results prove the effectiveness and superiority of our model.
Explainable Models via Compression of Tree Ensembles
Jun 16, 2022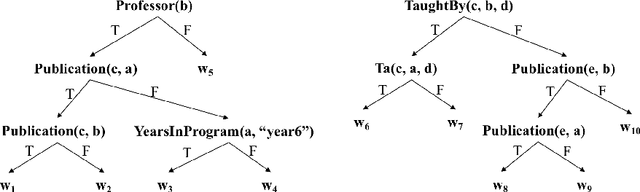
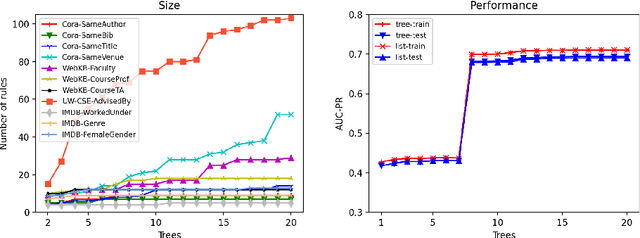
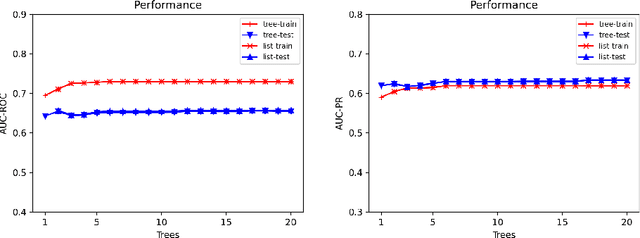
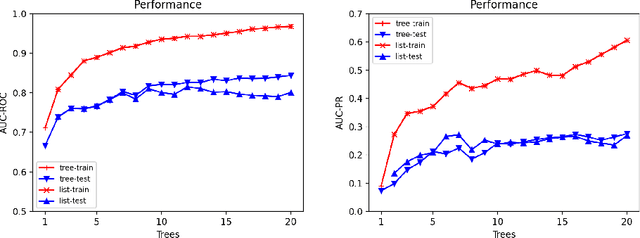
Ensemble models (bagging and gradient-boosting) of relational decision trees have proved to be one of the most effective learning methods in the area of probabilistic logic models (PLMs). While effective, they lose one of the most important aspect of PLMs -- interpretability. In this paper we consider the problem of compressing a large set of learned trees into a single explainable model. To this effect, we propose CoTE -- Compression of Tree Ensembles -- that produces a single small decision list as a compressed representation. CoTE first converts the trees to decision lists and then performs the combination and compression with the aid of the original training set. An experimental evaluation demonstrates the effectiveness of CoTE in several benchmark relational data sets.
Predicting Drug-Drug Interactions from Heterogeneous Data: An Embedding Approach
Mar 19, 2021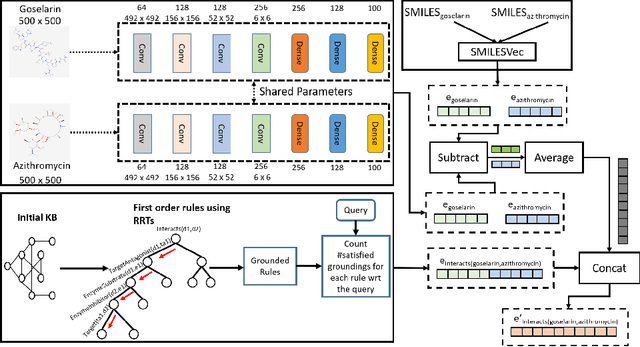
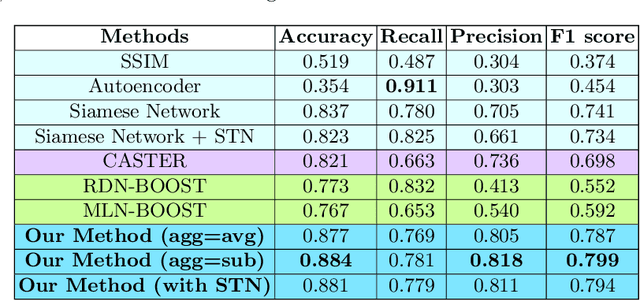
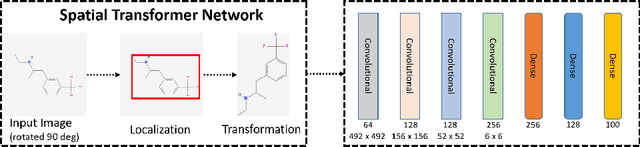
Predicting and discovering drug-drug interactions (DDIs) using machine learning has been studied extensively. However, most of the approaches have focused on text data or textual representation of the drug structures. We present the first work that uses multiple data sources such as drug structure images, drug structure string representation and relational representation of drug relationships as the input. To this effect, we exploit the recent advances in deep networks to integrate these varied sources of inputs in predicting DDIs. Our empirical evaluation against several state-of-the-art methods using standalone different data types for drugs clearly demonstrate the efficacy of combining heterogeneous data in predicting DDIs.
Bridging Graph Neural Networks and Statistical Relational Learning: Relational One-Class GCN
Feb 18, 2021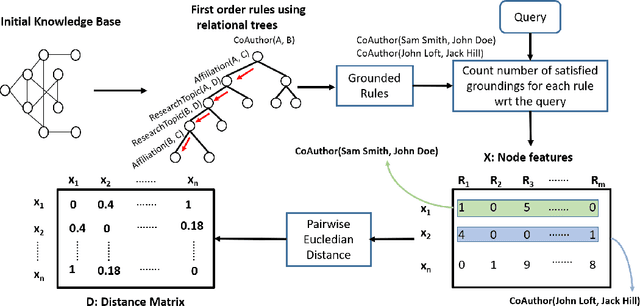

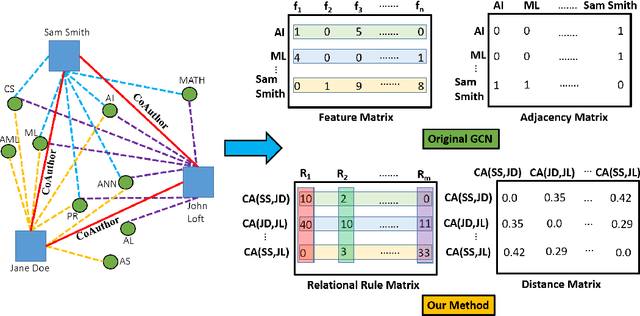
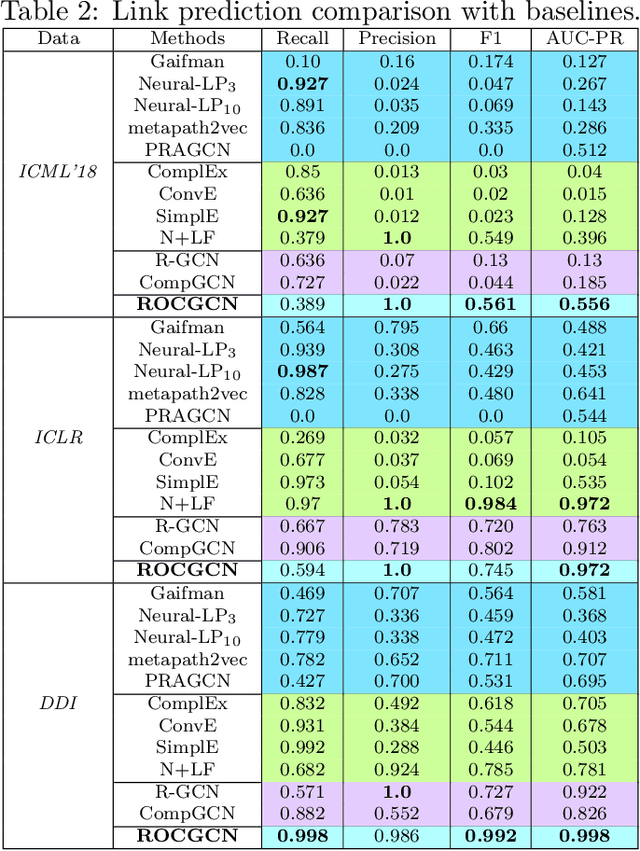
We consider the problem of learning Graph Convolutional Networks (GCNs) for relational data. Specifically, we consider the classic link prediction and node classification problems as relational modeling tasks and develop a relational extension to GCNs. Our method constructs a secondary graph using relational density estimation techniques where vertices correspond to the target triples. We emphasize the importance of learning features using the secondary graph and the advantages of employing a distance matrix over the typically used adjacency matrix. Our comprehensive empirical evaluation demonstrates the superiority of our approach over $\mathbf{12}$ different GCN models, relational embedding techniques, rule learning techniques and relational models.
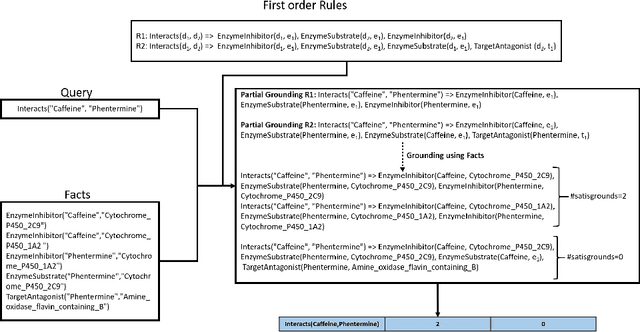
Non-Parametric Learning of Gaifman Models
Jan 15, 2020

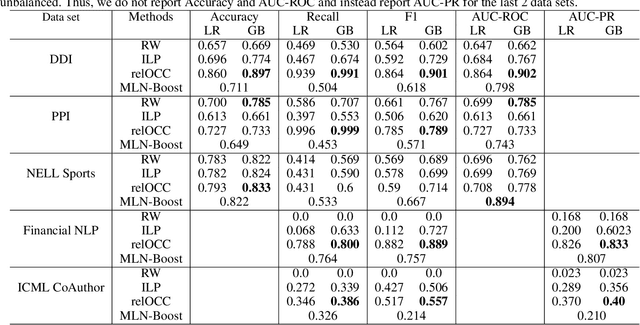
We consider the problem of structure learning for Gaifman models and learn relational features that can be used to derive feature representations from a knowledge base. These relational features are first-order rules that are then partially grounded and counted over local neighborhoods of a Gaifman model to obtain the feature representations. We propose a method for learning these relational features for a Gaifman model by using relational tree distances. Our empirical evaluation on real data sets demonstrates the superiority of our approach over classical rule-learning.