 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-specific Credibility-aware Multimodal Fusion with Conditional Probabilistic Circuits
Mar 27, 2026Multimodal fusion requires integrating information from multiple sources that may conflict depending on context. Existing fusion approaches typically rely on static assumptions about source reliability, limiting their ability to resolve conflicts when a modality becomes unreliable due to situational factors such as sensor degradation or class-specific corruption. We introduce C$^2$MF, a context-specfic credibility-aware multimodal fusion framework that models per-instance source reliability using a Conditional Probabilistic Circuit (CPC). We formalize instance-level reliability through Context-Specific Information Credibility (CSIC), a KL-divergence-based measure computed exactly from the CPC. CSIC generalizes conventional static credibility estimates as a special case, enabling principled and adaptive reliability assessment. To evaluate robustness under cross-modal conflicts, we propose the Conflict benchmark, in which class-specific corruptions deliberately induce discrepancies between different modalities. Experimental results show that C$^2$MF improves predictive accuracy by up to 29% over static-reliability baselines in high-noise settings, while preserving the interpretability advantages of probabilistic circuit-based fusion.
Geometry-Aware Probabilistic Circuits via Voronoi Tessellations
Mar 12, 2026Probabilistic circuits (PCs) enable exact and tractable inference but employ data independent mixture weights that limit their ability to capture local geometry of the data manifold. We propose Voronoi tessellations (VT) as a natural way to incorporate geometric structure directly into the sum nodes of a PC. However, naïvely introducing such structure breaks tractability. We formalize this incompatibility and develop two complementary solutions: (1) an approximate inference framework that provides guaranteed lower and upper bounds for inference, and (2) a structural condition for VT under which exact tractable inference is recovered. Finally, we introduce a differentiable relaxation for VT that enables gradient-based learning and empirically validate the resulting approach on standard density estimation tasks.
Recursive Inference Machines for Neural Reasoning
Mar 05, 2026Neural reasoners such as Tiny Recursive Models (TRMs) solve complex problems by combining neural backbones with specialized inference schemes. Such inference schemes have been a central component of stochastic reasoning systems, where inference rules are applied to a stochastic model to derive answers to complex queries. In this work, we bridge these two paradigms by introducing Recursive Inference Machines (RIMs), a neural reasoning framework that explicitly incorporates recursive inference mechanisms inspired by classical inference engines. We show that TRMs can be expressed as an instance of RIMs, allowing us to extend them through a reweighting component, yielding better performance on challenging reasoning benchmarks, including ARC-AGI-1, ARC-AGI-2, and Sudoku Extreme. Furthermore, we show that RIMs can be used to improve reasoning on other tasks, such as the classification of tabular data, outperforming TabPFNs.
Tractable Sharpness-Aware Learning of Probabilistic Circuits
Aug 07, 2025Probabilistic Circuits (PCs) are a class of generative models that allow exact and tractable inference for a wide range of queries. While recent developments have enabled the learning of deep and expressive PCs, this increased capacity can often lead to overfitting, especially when data is limited. We analyze PC overfitting from a log-likelihood-landscape perspective and show that it is often caused by convergence to sharp optima that generalize poorly. Inspired by sharpness aware minimization in neural networks, we propose a Hessian-based regularizer for training PCs. As a key contribution, we show that the trace of the Hessian of the log-likelihood-a sharpness proxy that is typically intractable in deep neural networks-can be computed efficiently for PCs. Minimizing this Hessian trace induces a gradient-norm-based regularizer that yields simple closed-form parameter updates for EM, and integrates seamlessly with gradient based learning methods. Experiments on synthetic and real-world datasets demonstrate that our method consistently guides PCs toward flatter minima, improves generalization performance.
Combining Planning and Reinforcement Learning for Solving Relational Multiagent Domains
Feb 26, 2025Multiagent Reinforcement Learning (MARL) poses significant challenges due to the exponential growth of state and action spaces and the non-stationary nature of multiagent environments. This results in notable sample inefficiency and hinders generalization across diverse tasks. The complexity is further pronounced in relational settings, where domain knowledge is crucial but often underutilized by existing MARL algorithms. To overcome these hurdles, we propose integrating relational planners as centralized controllers with efficient state abstractions and reinforcement learning. This approach proves to be sample-efficient and facilitates effective task transfer and generalization.
A Unified Framework for Human-Allied Learning of Probabilistic Circuits
May 03, 2024



Probabilistic Circuits (PCs) have emerged as an efficient framework for representing and learning complex probability distributions. Nevertheless, the existing body of research on PCs predominantly concentrates on data-driven parameter learning, often neglecting the potential of knowledge-intensive learning, a particular issue in data-scarce/knowledge-rich domains such as healthcare. To bridge this gap, we propose a novel unified framework that can systematically integrate diverse domain knowledge into the parameter learning process of PCs. Experiments on several benchmarks as well as real world datasets show that our proposed framework can both effectively and efficiently leverage domain knowledge to achieve superior performance compared to purely data-driven learning approaches.
Credibility-Aware Multi-Modal Fusion Using Probabilistic Circuits
Mar 05, 2024
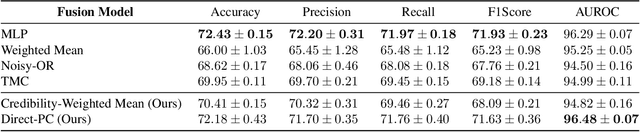
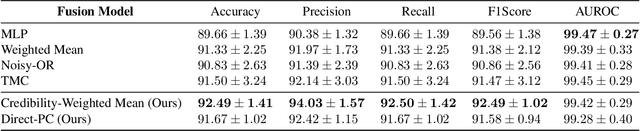
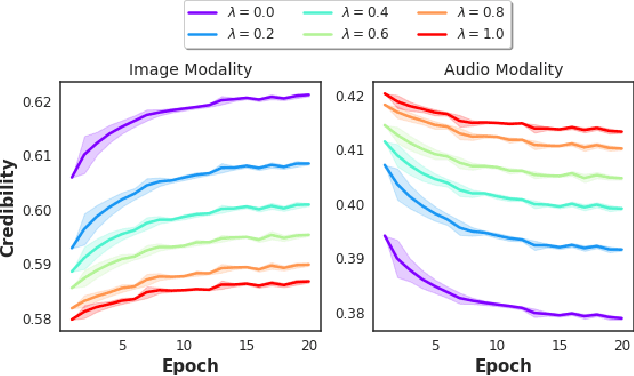
We consider the problem of late multi-modal fusion for discriminative learning. Motivated by noisy, multi-source domains that require understanding the reliability of each data source, we explore the notion of credibility in the context of multi-modal fusion. We propose a combination function that uses probabilistic circuits (PCs) to combine predictive distributions over individual modalities. We also define a probabilistic measure to evaluate the credibility of each modality via inference queries over the PC. Our experimental evaluation demonstrates that our fusion method can reliably infer credibility while maintaining competitive performance with the state-of-the-art.
Building Expressive and Tractable Probabilistic Generative Models: A Review
Feb 01, 2024We present a comprehensive survey of the advancements and techniques in the field of tractable probabilistic generative modeling, primarily focusing on Probabilistic Circuits (PCs). We provide a unified perspective on the inherent trade-offs between expressivity and the tractability, highlighting the design principles and algorithmic extensions that have enabled building expressive and efficient PCs, and provide a taxonomy of the field. We also discuss recent efforts to build deep and hybrid PCs by fusing notions from deep neural models, and outline the challenges and open questions that can guide future research in this evolving field.
Promoting Research Collaboration with Open Data Driven Team Recommendation in Response to Call for Proposals
Sep 27, 2023Building teams and promoting collaboration are two very common business activities. An example of these are seen in the TeamingForFunding problem, where research institutions and researchers are interested to identify collaborative opportunities when applying to funding agencies in response to latter's calls for proposals. We describe a novel system to recommend teams using a variety of AI methods, such that (1) each team achieves the highest possible skill coverage that is demanded by the opportunity, and (2) the workload of distributing the opportunities is balanced amongst the candidate members. We address these questions by extracting skills latent in open data of proposal calls (demand) and researcher profiles (supply), normalizing them using taxonomies, and creating efficient algorithms that match demand to supply. We create teams to maximize goodness along a novel metric balancing short- and long-term objectives. We validate the success of our algorithms (1) quantitatively, by evaluating the recommended teams using a goodness score and find that more informed methods lead to recommendations of smaller number of teams but higher goodness, and (2) qualitatively, by conducting a large-scale user study at a college-wide level, and demonstrate that users overall found the tool very useful and relevant. Lastly, we evaluate our system in two diverse settings in US and India (of researchers and proposal calls) to establish generality of our approach, and deploy it at a major US university for routine use.
Knowledge-based Refinement of Scientific Publication Knowledge Graphs
Sep 10, 2023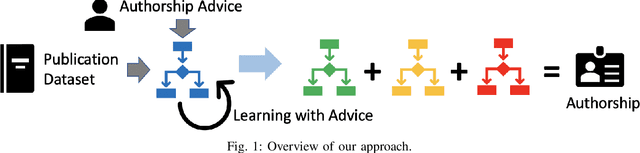
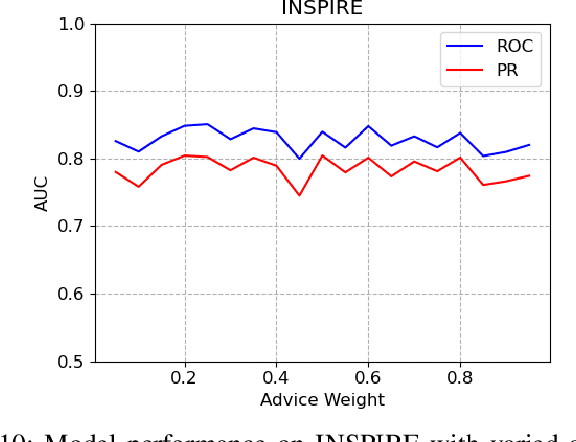
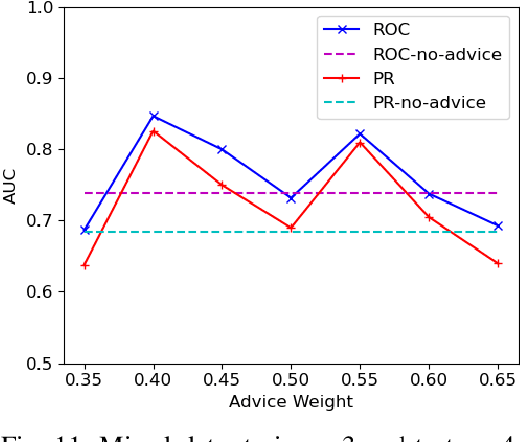
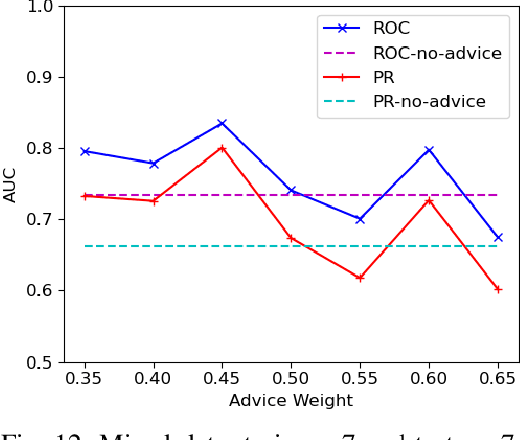
We consider the problem of identifying authorship by posing it as a knowledge graph construction and refinement. To this effect, we model this problem as learning a probabilistic logic model in the presence of human guidance (knowledge-based learning). Specifically, we learn relational regression trees using functional gradient boosting that outputs explainable rules. To incorporate human knowledge, advice in the form of first-order clauses is injected to refine the trees. We demonstrate the usefulness of human knowledge both quantitatively and qualitatively in seven authorship domains.