 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Models via Compression of Tree Ensembles
Paper and Code
Jun 16, 2022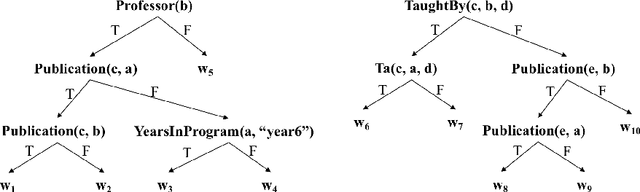
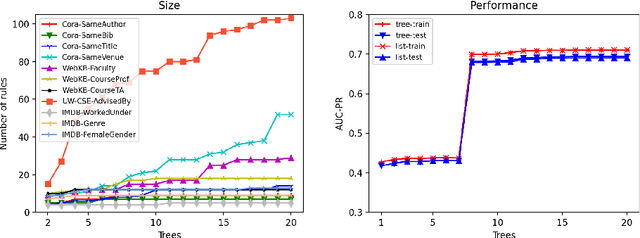
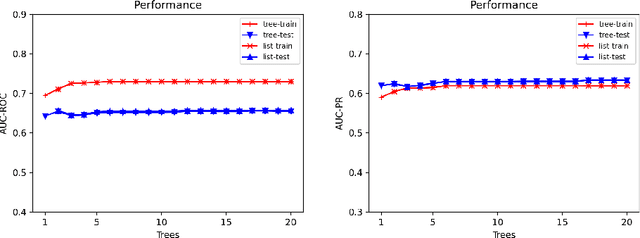
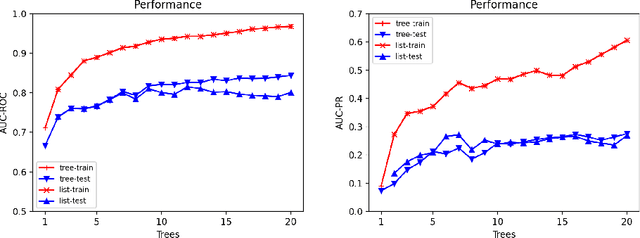
Ensemble models (bagging and gradient-boosting) of relational decision trees have proved to be one of the most effective learning methods in the area of probabilistic logic models (PLMs). While effective, they lose one of the most important aspect of PLMs -- interpretability. In this paper we consider the problem of compressing a large set of learned trees into a single explainable model. To this effect, we propose CoTE -- Compression of Tree Ensembles -- that produces a single small decision list as a compressed representation. CoTE first converts the trees to decision lists and then performs the combination and compression with the aid of the original training set. An experimental evaluation demonstrates the effectiveness of CoTE in several benchmark relational data sets.