 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConformal Margin Risk Minimization: An Envelope Framework for Robust Learning under Label Noise
Apr 07, 2026Most methods for learning with noisy labels require privileged knowledge such as noise transition matrices, clean subsets or pretrained feature extractors, resources typically unavailable when robustness is most needed. We propose Conformal Margin Risk Minimization (CMRM), a plug-and-play envelope framework that improves any classification loss under label noise by adding a single quantile-calibrated regularization term, with no privileged knowledge or training pipeline modification. CMRM measures the confidence margin between the observed label and competing labels, and thresholds it with a conformal quantile estimated per batch to focus training on high-margin samples while suppressing likely mislabeled ones. We derive a learning bound for CMRM under arbitrary label noise requiring only mild regularity of the margin distribution. Across five base methods and six benchmarks with synthetic and real-world noise, CMRM consistently improves accuracy (up to +3.39%), reduces conformal prediction set size (up to -20.44%) and does not hurt under 0% noise, showing that CMRM captures a method-agnostic uncertainty signal that existing mechanisms did not exploit.
Direct Prediction Set Minimization via Bilevel Conformal Classifier Training
Jun 07, 2025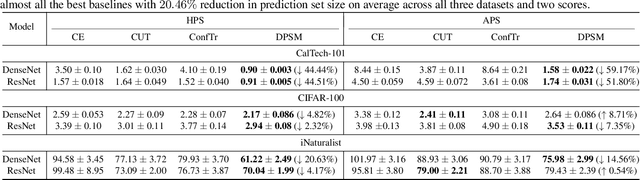



Conformal prediction (CP) is a promising uncertainty quantification framework which works as a wrapper around a black-box classifier to construct prediction sets (i.e., subset of candidate classes) with provable guarantees. However, standard calibration methods for CP tend to produce large prediction sets which makes them less useful in practice. This paper considers the problem of integrating conformal principles into the training process of deep classifiers to directly minimize the size of prediction sets. We formulate conformal training as a bilevel optimization problem and propose the {\em Direct Prediction Set Minimization (DPSM)} algorithm to solve it. The key insight behind DPSM is to minimize a measure of the prediction set size (upper level) that is conditioned on the learned quantile of conformity scores (lower level). We analyze that DPSM has a learning bound of $O(1/\sqrt{n})$ (with $n$ training samples), while prior conformal training methods based on stochastic approximation for the quantile has a bound of $\Omega(1/s)$ (with batch size $s$ and typically $s \ll \sqrt{n}$). Experiments on various benchmark datasets and deep models show that DPSM significantly outperforms the best prior conformal training baseline with $20.46\%\downarrow$ in the prediction set size and validates our theory.
Atleus: Accelerating Transformers on the Edge Enabled by 3D Heterogeneous Manycore Architectures
Jan 16, 2025Transformer architectures have become the standard neural network model for various machine learning applications including natural language processing and computer vision. However, the compute and memory requirements introduced by transformer models make them challenging to adopt for edge applications. Furthermore, fine-tuning pre-trained transformers (e.g., foundation models) is a common task to enhance the model's predictive performance on specific tasks/applications. Existing transformer accelerators are oblivious to complexities introduced by fine-tuning. In this paper, we propose the design of a three-dimensional (3D) heterogeneous architecture referred to as Atleus that incorporates heterogeneous computing resources specifically optimized to accelerate transformer models for the dual purposes of fine-tuning and inference. Specifically, Atleus utilizes non-volatile memory and systolic array for accelerating transformer computational kernels using an integrated 3D platform. Moreover, we design a suitable NoC to achieve high performance and energy efficiency. Finally, Atleus adopts an effective quantization scheme to support model compression. Experimental results demonstrate that Atleus outperforms existing state-of-the-art by up to 56x and 64.5x in terms of performance and energy efficiency respectively
Constraint-Adaptive Policy Switching for Offline Safe Reinforcement Learning
Dec 25, 2024Offline safe reinforcement learning (OSRL) involves learning a decision-making policy to maximize rewards from a fixed batch of training data to satisfy pre-defined safety constraints. However, adapting to varying safety constraints during deployment without retraining remains an under-explored challenge. To address this challenge, we introduce constraint-adaptive policy switching (CAPS), a wrapper framework around existing offline RL algorithms. During training, CAPS uses offline data to learn multiple policies with a shared representation that optimize different reward and cost trade-offs. During testing, CAPS switches between those policies by selecting at each state the policy that maximizes future rewards among those that satisfy the current cost constraint. Our experiments on 38 tasks from the DSRL benchmark demonstrate that CAPS consistently outperforms existing methods, establishing a strong wrapper-based baseline for OSRL. The code is publicly available at https://github.com/yassineCh/CAPS.
Non-Myopic Multi-Objective Bayesian Optimization
Dec 11, 2024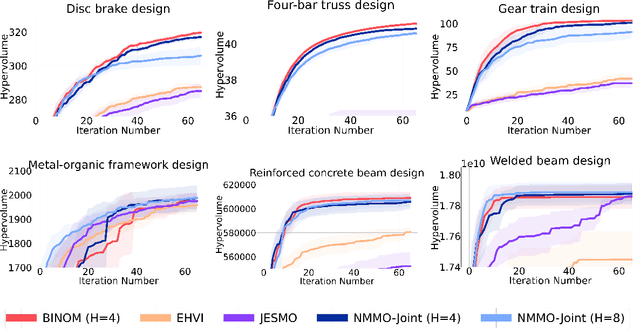

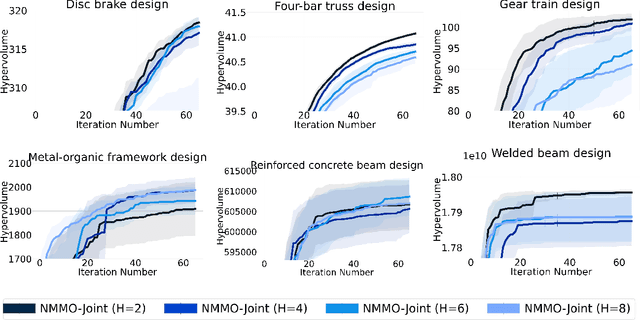

We consider the problem of finite-horizon sequential experimental design to solve multi-objective optimization (MOO) of expensive black-box objective functions. This problem arises in many real-world applications, including materials design, where we have a small resource budget to make and evaluate candidate materials in the lab. We solve this problem using the framework of Bayesian optimization (BO) and propose the first set of non-myopic methods for MOO problems. Prior work on non-myopic BO for single-objective problems relies on the Bellman optimality principle to handle the lookahead reasoning process. However, this principle does not hold for most MOO problems because the reward function needs to satisfy some conditions: scalar variable, monotonicity, and additivity. We address this challenge by using hypervolume improvement (HVI) as our scalarization approach, which allows us to use a lower-bound on the Bellman equation to approximate the finite-horizon using a batch expected hypervolume improvement (EHVI) acquisition function (AF) for MOO. Our formulation naturally allows us to use other improvement-based scalarizations and compare their efficacy to HVI. We derive three non-myopic AFs for MOBO: 1) the Nested AF, which is based on the exact computation of the lower bound, 2) the Joint AF, which is a lower bound on the nested AF, and 3) the BINOM AF, which is a fast and approximate variant based on batch multi-objective acquisition functions. Our experiments on multiple diverse real-world MO problems demonstrate that our non-myopic AFs substantially improve performance over the existing myopic AFs for MOBO.
HeTraX: Energy Efficient 3D Heterogeneous Manycore Architecture for Transformer Acceleration
Aug 06, 2024Transformers have revolutionized deep learning and generative modeling to enable unprecedented advancements in natural language processing tasks and beyond. However, designing hardware accelerators for executing transformer models is challenging due to the wide variety of computing kernels involved in the transformer architecture. Existing accelerators are either inadequate to accelerate end-to-end transformer models or suffer notable thermal limitations. In this paper, we propose the design of a three-dimensional heterogeneous architecture referred to as HeTraX specifically optimized to accelerate end-to-end transformer models. HeTraX employs hardware resources aligned with the computational kernels of transformers and optimizes both performance and energy. Experimental results show that HeTraX outperforms existing state-of-the-art by up to 5.6x in speedup and improves EDP by 14.5x while ensuring thermally feasibility.
Active Learning for Derivative-Based Global Sensitivity Analysis with Gaussian Processes
Jul 13, 2024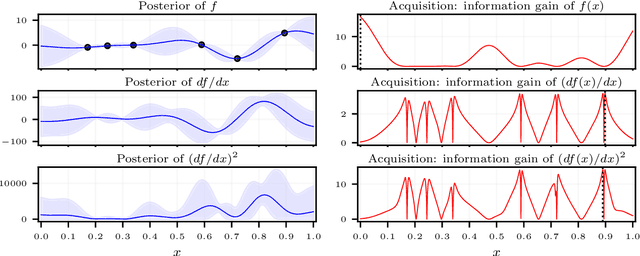
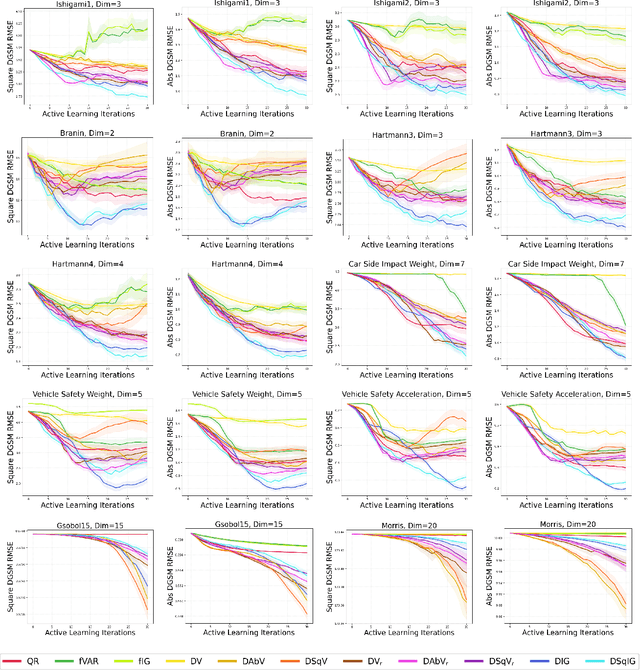
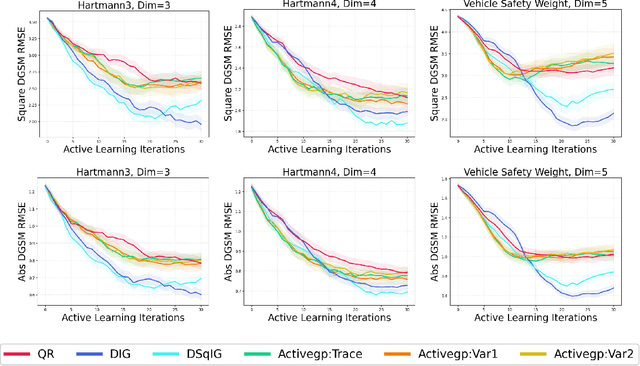
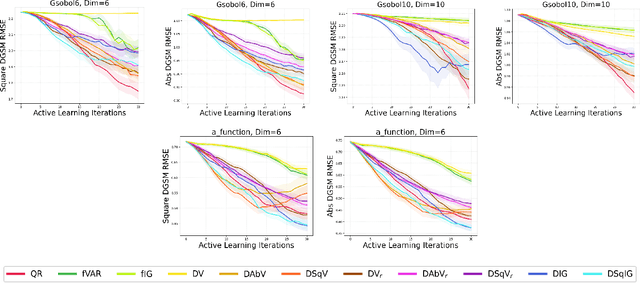
We consider the problem of active learning for global sensitivity analysis of expensive black-box functions. Our aim is to efficiently learn the importance of different input variables, e.g., in vehicle safety experimentation, we study the impact of the thickness of various components on safety objectives. Since function evaluations are expensive, we use active learning to prioritize experimental resources where they yield the most value. We propose novel active learning acquisition functions that directly target key quantities of derivative-based global sensitivity measures (DGSMs) under Gaussian process surrogate models. We showcase the first application of active learning directly to DGSMs, and develop tractable uncertainty reduction and information gain acquisition functions for these measures. Through comprehensive evaluation on synthetic and real-world problems, our study demonstrates how these active learning acquisition strategies substantially enhance the sample efficiency of DGSM estimation, particularly with limited evaluation budgets. Our work paves the way for more efficient and accurate sensitivity analysis in various scientific and engineering applications.
Pareto Front-Diverse Batch Multi-Objective Bayesian Optimization
Jun 13, 2024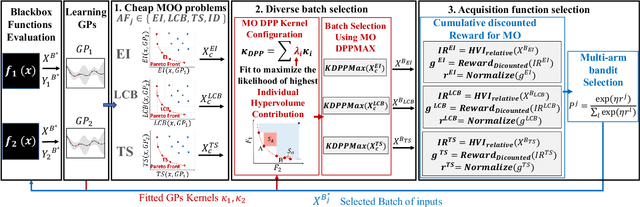
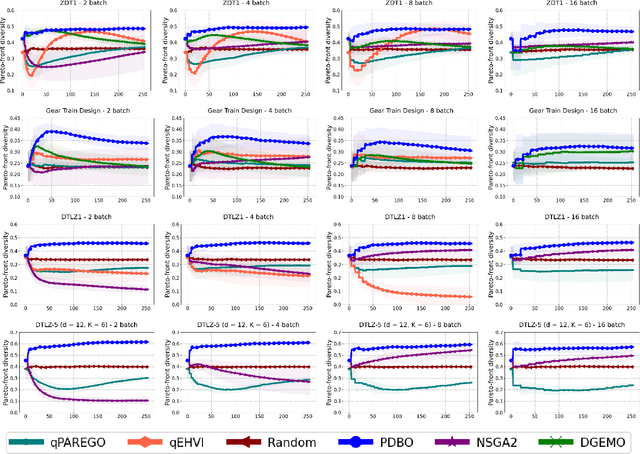
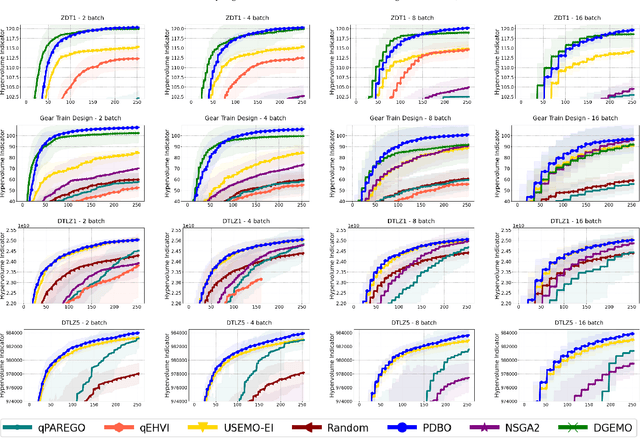
We consider the problem of multi-objective optimization (MOO) of expensive black-box functions with the goal of discovering high-quality and diverse Pareto fronts where we are allowed to evaluate a batch of inputs. This problem arises in many real-world applications including penicillin production where diversity of solutions is critical. We solve this problem in the framework of Bayesian optimization (BO) and propose a novel approach referred to as Pareto front-Diverse Batch Multi-Objective BO (PDBO). PDBO tackles two important challenges: 1) How to automatically select the best acquisition function in each BO iteration, and 2) How to select a diverse batch of inputs by considering multiple objectives. We propose principled solutions to address these two challenges. First, PDBO employs a multi-armed bandit approach to select one acquisition function from a given library. We solve a cheap MOO problem by assigning the selected acquisition function for each expensive objective function to obtain a candidate set of inputs for evaluation. Second, it utilizes Determinantal Point Processes (DPPs) to choose a Pareto-front-diverse batch of inputs for evaluation from the candidate set obtained from the first step. The key parameters for the methods behind these two steps are updated after each round of function evaluations. Experiments on multiple MOO benchmarks demonstrate that PDBO outperforms prior methods in terms of both the quality and diversity of Pareto solutions.
Conformal Prediction for Class-wise Coverage via Augmented Label Rank Calibration
Jun 10, 2024
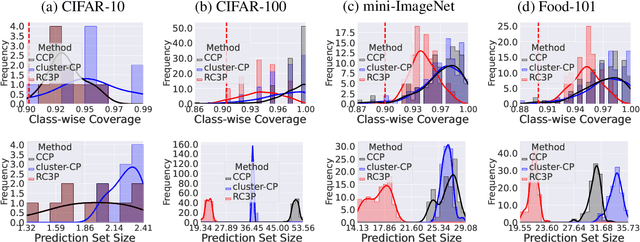


Conformal prediction (CP) is an emerging uncertainty quantification framework that allows us to construct a prediction set to cover the true label with a pre-specified marginal or conditional probability. Although the valid coverage guarantee has been extensively studied for classification problems, CP often produces large prediction sets which may not be practically useful. This issue is exacerbated for the setting of class-conditional coverage on imbalanced classification tasks. This paper proposes the Rank Calibrated Class-conditional CP (RC3P) algorithm to reduce the prediction set sizes to achieve class-conditional coverage, where the valid coverage holds for each class. In contrast to the standard class-conditional CP (CCP) method that uniformly thresholds the class-wise conformity score for each class, the augmented label rank calibration step allows RC3P to selectively iterate this class-wise thresholding subroutine only for a subset of classes whose class-wise top-k error is small. We prove that agnostic to the classifier and data distribution, RC3P achieves class-wise coverage. We also show that RC3P reduces the size of prediction sets compared to the CCP method. Comprehensive experiments on multiple real-world datasets demonstrate that RC3P achieves class-wise coverage and 26.25% reduction in prediction set sizes on average.
Streamflow Prediction with Uncertainty Quantification for Water Management: A Constrained Reasoning and Learning Approach
May 31, 2024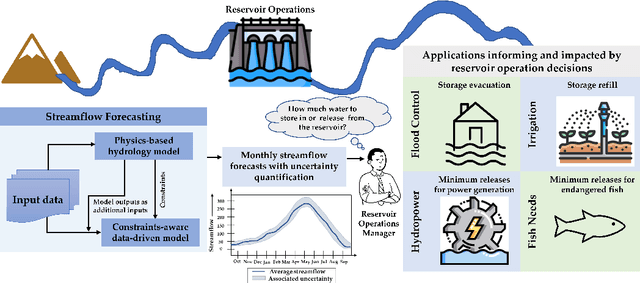


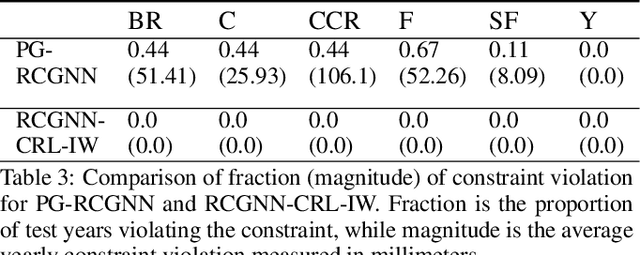
Predicting the spatiotemporal variation in streamflow along with uncertainty quantification enables decision-making for sustainable management of scarce water resources. Process-based hydrological models (aka physics-based models) are based on physical laws, but using simplifying assumptions which can lead to poor accuracy. Data-driven approaches offer a powerful alternative, but they require large amount of training data and tend to produce predictions that are inconsistent with physical laws. This paper studies a constrained reasoning and learning (CRL) approach where physical laws represented as logical constraints are integrated as a layer in the deep neural network. To address small data setting, we develop a theoretically-grounded training approach to improve the generalization accuracy of deep models. For uncertainty quantification, we combine the synergistic strengths of Gaussian processes (GPs) and deep temporal models (i.e., deep models for time-series forecasting) by passing the learned latent representation as input to a standard distance-based kernel. Experiments on multiple real-world datasets demonstrate the effectiveness of both CRL and GP with deep kernel approaches over strong baseline methods.