 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirect Prediction Set Minimization via Bilevel Conformal Classifier Training
Jun 07, 2025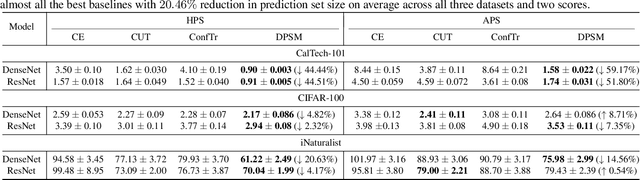



Conformal prediction (CP) is a promising uncertainty quantification framework which works as a wrapper around a black-box classifier to construct prediction sets (i.e., subset of candidate classes) with provable guarantees. However, standard calibration methods for CP tend to produce large prediction sets which makes them less useful in practice. This paper considers the problem of integrating conformal principles into the training process of deep classifiers to directly minimize the size of prediction sets. We formulate conformal training as a bilevel optimization problem and propose the {\em Direct Prediction Set Minimization (DPSM)} algorithm to solve it. The key insight behind DPSM is to minimize a measure of the prediction set size (upper level) that is conditioned on the learned quantile of conformity scores (lower level). We analyze that DPSM has a learning bound of $O(1/\sqrt{n})$ (with $n$ training samples), while prior conformal training methods based on stochastic approximation for the quantile has a bound of $\Omega(1/s)$ (with batch size $s$ and typically $s \ll \sqrt{n}$). Experiments on various benchmark datasets and deep models show that DPSM significantly outperforms the best prior conformal training baseline with $20.46\%\downarrow$ in the prediction set size and validates our theory.
Conformal Prediction Sets for Deep Generative Models via Reduction to Conformal Regression
Mar 13, 2025



We consider the problem of generating valid and small prediction sets by sampling outputs (e.g., software code and natural language text) from a black-box deep generative model for a given input (e.g., textual prompt). The validity of a prediction set is determined by a user-defined binary admissibility function depending on the target application. For example, requiring at least one program in the set to pass all test cases in code generation application. To address this problem, we develop a simple and effective conformal inference algorithm referred to as Generative Prediction Sets (GPS). Given a set of calibration examples and black-box access to a deep generative model, GPS can generate prediction sets with provable guarantees. The key insight behind GPS is to exploit the inherent structure within the distribution over the minimum number of samples needed to obtain an admissible output to develop a simple conformal regression approach over the minimum number of samples. Experiments on multiple datasets for code and math word problems using different large language models demonstrate the efficacy of GPS over state-of-the-art methods.
GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models
Oct 07, 2024
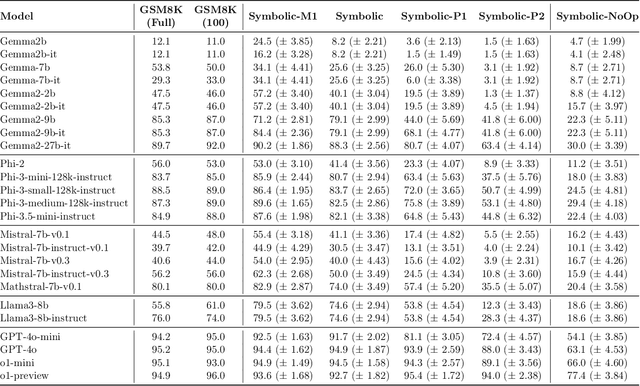
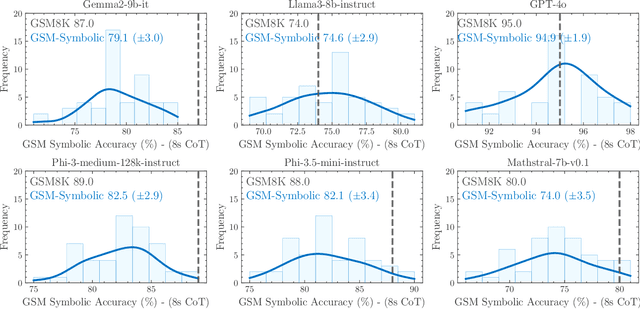

Recent advancements in Large Language Models (LLMs) have sparked interest in their formal reasoning capabilities, particularly in mathematics. The GSM8K benchmark is widely used to assess the mathematical reasoning of models on grade-school-level questions. While the performance of LLMs on GSM8K has significantly improved in recent years, it remains unclear whether their mathematical reasoning capabilities have genuinely advanced, raising questions about the reliability of the reported metrics. To address these concerns, we conduct a large-scale study on several SOTA open and closed models. To overcome the limitations of existing evaluations, we introduce GSM-Symbolic, an improved benchmark created from symbolic templates that allow for the generation of a diverse set of questions. GSM-Symbolic enables more controllable evaluations, providing key insights and more reliable metrics for measuring the reasoning capabilities of models.Our findings reveal that LLMs exhibit noticeable variance when responding to different instantiations of the same question. Specifically, the performance of all models declines when only the numerical values in the question are altered in the GSM-Symbolic benchmark. Furthermore, we investigate the fragility of mathematical reasoning in these models and show that their performance significantly deteriorates as the number of clauses in a question increases. We hypothesize that this decline is because current LLMs cannot perform genuine logical reasoning; they replicate reasoning steps from their training data. Adding a single clause that seems relevant to the question causes significant performance drops (up to 65%) across all state-of-the-art models, even though the clause doesn't contribute to the reasoning chain needed for the final answer. Overall, our work offers a more nuanced understanding of LLMs' capabilities and limitations in mathematical reasoning.