 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRayRoPE: Projective Ray Positional Encoding for Multi-view Attention
Jan 21, 2026We study positional encodings for multi-view transformers that process tokens from a set of posed input images, and seek a mechanism that encodes patches uniquely, allows SE(3)-invariant attention with multi-frequency similarity, and can be adaptive to the geometry of the underlying scene. We find that prior (absolute or relative) encoding schemes for multi-view attention do not meet the above desiderata, and present RayRoPE to address this gap. RayRoPE represents patch positions based on associated rays but leverages a predicted point along the ray instead of the direction for a geometry-aware encoding. To achieve SE(3) invariance, RayRoPE computes query-frame projective coordinates for computing multi-frequency similarity. Lastly, as the 'predicted' 3D point along a ray may not be precise, RayRoPE presents a mechanism to analytically compute the expected position encoding under uncertainty. We validate RayRoPE on the tasks of novel-view synthesis and stereo depth estimation and show that it consistently improves over alternate position encoding schemes (e.g. 15% relative improvement on LPIPS in CO3D). We also show that RayRoPE can seamlessly incorporate RGB-D input, resulting in even larger gains over alternatives that cannot positionally encode this information.
AMUSE: Audio-Visual Benchmark and Alignment Framework for Agentic Multi-Speaker Understanding
Dec 18, 2025

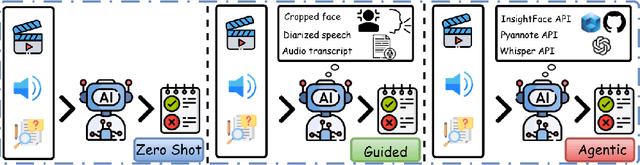
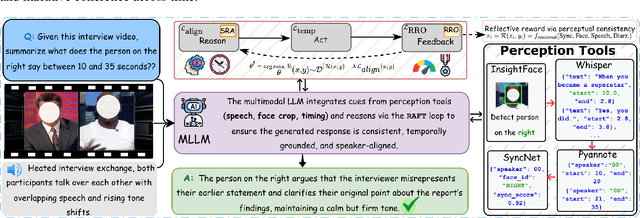
Recent multimodal large language models (MLLMs) such as GPT-4o and Qwen3-Omni show strong perception but struggle in multi-speaker, dialogue-centric settings that demand agentic reasoning tracking who speaks, maintaining roles, and grounding events across time. These scenarios are central to multimodal audio-video understanding, where models must jointly reason over audio and visual streams in applications such as conversational video assistants and meeting analytics. We introduce AMUSE, a benchmark designed around tasks that are inherently agentic, requiring models to decompose complex audio-visual interactions into planning, grounding, and reflection steps. It evaluates MLLMs across three modes zero-shot, guided, and agentic and six task families, including spatio-temporal speaker grounding and multimodal dialogue summarization. Across all modes, current models exhibit weak multi-speaker reasoning and inconsistent behavior under both non-agentic and agentic evaluation. Motivated by the inherently agentic nature of these tasks and recent advances in LLM agents, we propose RAFT, a data-efficient agentic alignment framework that integrates reward optimization with intrinsic multimodal self-evaluation as reward and selective parameter adaptation for data and parameter efficient updates. Using RAFT, we achieve up to 39.52\% relative improvement in accuracy on our benchmark. Together, AMUSE and RAFT provide a practical platform for examining agentic reasoning in multimodal models and improving their capabilities.
Learning to Reason for Hallucination Span Detection
Oct 02, 2025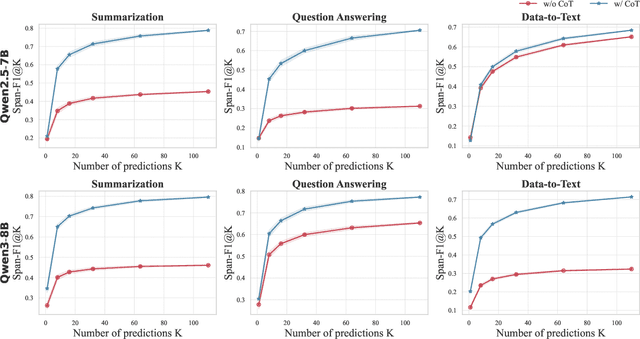
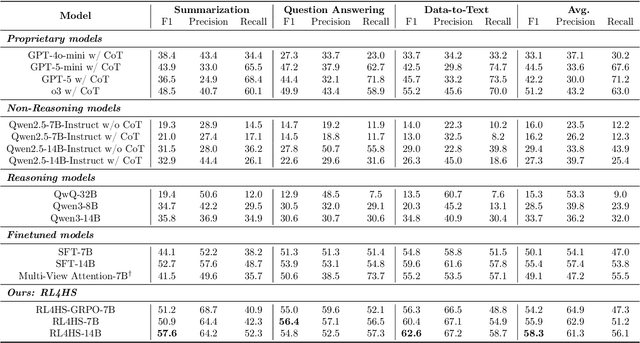
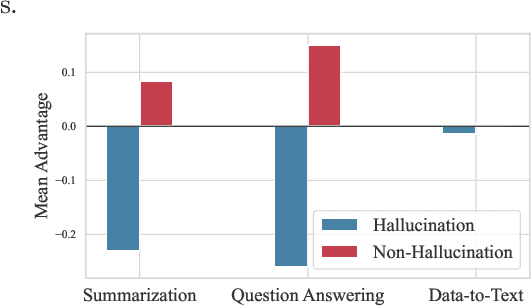
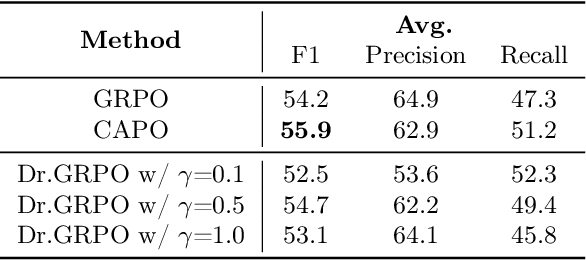
Large language models (LLMs) often generate hallucinations -- unsupported content that undermines reliability. While most prior works frame hallucination detection as a binary task, many real-world applications require identifying hallucinated spans, which is a multi-step decision making process. This naturally raises the question of whether explicit reasoning can help the complex task of detecting hallucination spans. To answer this question, we first evaluate pretrained models with and without Chain-of-Thought (CoT) reasoning, and show that CoT reasoning has the potential to generate at least one correct answer when sampled multiple times. Motivated by this, we propose RL4HS, a reinforcement learning framework that incentivizes reasoning with a span-level reward function. RL4HS builds on Group Relative Policy Optimization and introduces Class-Aware Policy Optimization to mitigate reward imbalance issue. Experiments on the RAGTruth benchmark (summarization, question answering, data-to-text) show that RL4HS surpasses pretrained reasoning models and supervised fine-tuning, demonstrating the necessity of reinforcement learning with span-level rewards for detecting hallucination spans.
MobileCLIP2: Improving Multi-Modal Reinforced Training
Aug 28, 2025Foundation image-text models such as CLIP with zero-shot capabilities enable a wide array of applications. MobileCLIP is a recent family of image-text models at 3-15ms latency and 50-150M parameters with state-of-the-art zero-shot accuracy. The main ingredients in MobileCLIP were its low-latency and light architectures and a novel multi-modal reinforced training that made knowledge distillation from multiple caption-generators and CLIP teachers efficient, scalable, and reproducible. In this paper, we improve the multi-modal reinforced training of MobileCLIP through: 1) better CLIP teacher ensembles trained on the DFN dataset, 2) improved captioner teachers trained on the DFN dataset and fine-tuned on a diverse selection of high-quality image-caption datasets. We discover new insights through ablations such as the importance of temperature tuning in contrastive knowledge distillation, the effectiveness of caption-generator fine-tuning for caption diversity, and the additive improvement from combining synthetic captions generated by multiple models. We train a new family of models called MobileCLIP2 and achieve state-of-the-art ImageNet-1k zero-shot accuracies at low latencies. In particular, we observe 2.2% improvement in ImageNet-1k accuracy for MobileCLIP2-B compared with MobileCLIP-B architecture. Notably, MobileCLIP2-S4 matches the zero-shot accuracy of SigLIP-SO400M/14 on ImageNet-1k while being 2$\times$ smaller and improves on DFN ViT-L/14 at 2.5$\times$ lower latency. We release our pretrained models (https://github.com/apple/ml-mobileclip) and the data generation code (https://github.com/apple/ml-mobileclip-dr). The data generation code makes it easy to create new reinforced datasets with arbitrary teachers using distributed scalable processing.
Proxy-FDA: Proxy-based Feature Distribution Alignment for Fine-tuning Vision Foundation Models without Forgetting
May 30, 2025



Vision foundation models pre-trained on massive data encode rich representations of real-world concepts, which can be adapted to downstream tasks by fine-tuning. However, fine-tuning foundation models on one task often leads to the issue of concept forgetting on other tasks. Recent methods of robust fine-tuning aim to mitigate forgetting of prior knowledge without affecting the fine-tuning performance. Knowledge is often preserved by matching the original and fine-tuned model weights or feature pairs. However, such point-wise matching can be too strong, without explicit awareness of the feature neighborhood structures that encode rich knowledge as well. We propose a novel regularization method Proxy-FDA that explicitly preserves the structural knowledge in feature space. Proxy-FDA performs Feature Distribution Alignment (using nearest neighbor graphs) between the pre-trained and fine-tuned feature spaces, and the alignment is further improved by informative proxies that are generated dynamically to increase data diversity. Experiments show that Proxy-FDA significantly reduces concept forgetting during fine-tuning, and we find a strong correlation between forgetting and a distributional distance metric (in comparison to L2 distance). We further demonstrate Proxy-FDA's benefits in various fine-tuning settings (end-to-end, few-shot and continual tuning) and across different tasks like image classification, captioning and VQA.
FocalLens: Instruction Tuning Enables Zero-Shot Conditional Image Representations
Apr 11, 2025



Visual understanding is inherently contextual -- what we focus on in an image depends on the task at hand. For instance, given an image of a person holding a bouquet of flowers, we may focus on either the person such as their clothing, or the type of flowers, depending on the context of interest. Yet, most existing image encoding paradigms represent an image as a fixed, generic feature vector, overlooking the potential needs of prioritizing varying visual information for different downstream use cases. In this work, we introduce FocalLens, a conditional visual encoding method that produces different representations for the same image based on the context of interest, expressed flexibly through natural language. We leverage vision instruction tuning data and contrastively finetune a pretrained vision encoder to take natural language instructions as additional inputs for producing conditional image representations. Extensive experiments validate that conditional image representation from FocalLens better pronounce the visual features of interest compared to generic features produced by standard vision encoders like CLIP. In addition, we show FocalLens further leads to performance improvements on a range of downstream tasks including image-image retrieval, image classification, and image-text retrieval, with an average gain of 5 and 10 points on the challenging SugarCrepe and MMVP-VLM benchmarks, respectively.
TiC-LM: A Web-Scale Benchmark for Time-Continual LLM Pretraining
Apr 02, 2025Large Language Models (LLMs) trained on historical web data inevitably become outdated. We investigate evaluation strategies and update methods for LLMs as new data becomes available. We introduce a web-scale dataset for time-continual pretraining of LLMs derived from 114 dumps of Common Crawl (CC) - orders of magnitude larger than previous continual language modeling benchmarks. We also design time-stratified evaluations across both general CC data and specific domains (Wikipedia, StackExchange, and code documentation) to assess how well various continual learning methods adapt to new data while retaining past knowledge. Our findings demonstrate that, on general CC data, autoregressive meta-schedules combined with a fixed-ratio replay of older data can achieve comparable held-out loss to re-training from scratch, while requiring significantly less computation (2.6x). However, the optimal balance between incorporating new data and replaying old data differs as replay is crucial to avoid forgetting on generic web data but less so on specific domains.
Mutual Reinforcement of LLM Dialogue Synthesis and Summarization Capabilities for Few-Shot Dialogue Summarization
Feb 24, 2025In this work, we propose Mutual Reinforcing Data Synthesis (MRDS) within LLMs to improve few-shot dialogue summarization task. Unlike prior methods that require external knowledge, we mutually reinforce the LLM\'s dialogue synthesis and summarization capabilities, allowing them to complement each other during training and enhance overall performances. The dialogue synthesis capability is enhanced by directed preference optimization with preference scoring from summarization capability. The summarization capability is enhanced by the additional high quality dialogue-summary paired data produced by the dialogue synthesis capability. By leveraging the proposed MRDS mechanism, we elicit the internal knowledge of LLM in the format of synthetic data, and use it to augment the few-shot real training dataset. Empirical results demonstrate that our method improves dialogue summarization, achieving a 1.5% increase in ROUGE scores and a 0.3% improvement in BERT scores in few-shot settings. Furthermore, our method attains the highest average scores in human evaluations, surpassing both the pre-trained models and the baselines fine-tuned solely for summarization tasks.
3D Shape Tokenization
Dec 24, 2024



We introduce Shape Tokens, a 3D representation that is continuous, compact, and easy to incorporate into machine learning models. Shape Tokens act as conditioning vectors that represent shape information in a 3D flow-matching model. The flow-matching model is trained to approximate probability density functions corresponding to delta functions concentrated on the surfaces of shapes in 3D. By attaching Shape Tokens to various machine learning models, we can generate new shapes, convert images to 3D, align 3D shapes with text and images, and render shapes directly at variable, user specified, resolution. Moreover, Shape Tokens enable a systematic analysis of geometric properties such as normal, density, and deformation field. Across all tasks and experiments, utilizing Shape Tokens demonstrate strong performance compared to existing baselines.
FastVLM: Efficient Vision Encoding for Vision Language Models
Dec 17, 2024



Scaling the input image resolution is essential for enhancing the performance of Vision Language Models (VLMs), particularly in text-rich image understanding tasks. However, popular visual encoders such as ViTs become inefficient at high resolutions due to the large number of tokens and high encoding latency caused by stacked self-attention layers. At different operational resolutions, the vision encoder of a VLM can be optimized along two axes: reducing encoding latency and minimizing the number of visual tokens passed to the LLM, thereby lowering overall latency. Based on a comprehensive efficiency analysis of the interplay between image resolution, vision latency, token count, and LLM size, we introduce FastVLM, a model that achieves an optimized trade-off between latency, model size and accuracy. FastVLM incorporates FastViTHD, a novel hybrid vision encoder designed to output fewer tokens and significantly reduce encoding time for high-resolution images. Unlike previous methods, FastVLM achieves the optimal balance between visual token count and image resolution solely by scaling the input image, eliminating the need for additional token pruning and simplifying the model design. In the LLaVA-1.5 setup, FastVLM achieves 3.2$\times$ improvement in time-to-first-token (TTFT) while maintaining similar performance on VLM benchmarks compared to prior works. Compared to LLaVa-OneVision at the highest resolution (1152$\times$1152), FastVLM achieves comparable performance on key benchmarks like SeedBench and MMMU, using the same 0.5B LLM, but with 85$\times$ faster TTFT and a vision encoder that is 3.4$\times$ smaller.