 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepMMSearch-R1: Empowering Multimodal LLMs in Multimodal Web Search
Oct 14, 2025Multimodal Large Language Models (MLLMs) in real-world applications require access to external knowledge sources and must remain responsive to the dynamic and ever-changing real-world information in order to address information-seeking and knowledge-intensive user queries. Existing approaches, such as retrieval augmented generation (RAG) methods, search agents, and search equipped MLLMs, often suffer from rigid pipelines, excessive search calls, and poorly constructed search queries, which result in inefficiencies and suboptimal outcomes. To address these limitations, we present DeepMMSearch-R1, the first multimodal LLM capable of performing on-demand, multi-turn web searches and dynamically crafting queries for both image and text search tools. Specifically, DeepMMSearch-R1 can initiate web searches based on relevant crops of the input image making the image search more effective, and can iteratively adapt text search queries based on retrieved information, thereby enabling self-reflection and self-correction. Our approach relies on a two-stage training pipeline: a cold start supervised finetuning phase followed by an online reinforcement learning optimization. For training, we introduce DeepMMSearchVQA, a novel multimodal VQA dataset created through an automated pipeline intermixed with real-world information from web search tools. This dataset contains diverse, multi-hop queries that integrate textual and visual information, teaching the model when to search, what to search for, which search tool to use and how to reason over the retrieved information. We conduct extensive experiments across a range of knowledge-intensive benchmarks to demonstrate the superiority of our approach. Finally, we analyze the results and provide insights that are valuable for advancing multimodal web-search.
MM-Spatial: Exploring 3D Spatial Understanding in Multimodal LLMs
Mar 17, 2025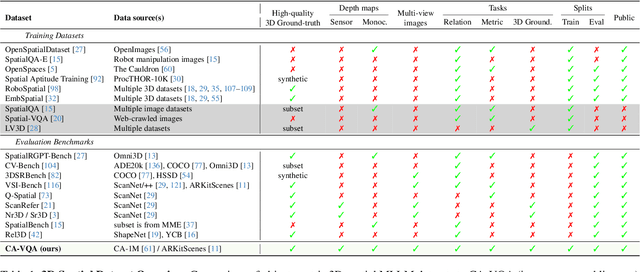

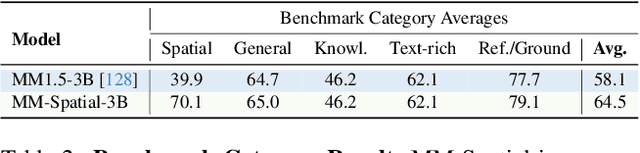

Multimodal large language models (MLLMs) excel at 2D visual understanding but remain limited in their ability to reason about 3D space. In this work, we leverage large-scale high-quality 3D scene data with open-set annotations to introduce 1) a novel supervised fine-tuning dataset and 2) a new evaluation benchmark, focused on indoor scenes. Our Cubify Anything VQA (CA-VQA) data covers diverse spatial tasks including spatial relationship prediction, metric size and distance estimation, and 3D grounding. We show that CA-VQA enables us to train MM-Spatial, a strong generalist MLLM that also achieves state-of-the-art performance on 3D spatial understanding benchmarks, including our own. We show how incorporating metric depth and multi-view inputs (provided in CA-VQA) can further improve 3D understanding, and demonstrate that data alone allows our model to achieve depth perception capabilities comparable to dedicated monocular depth estimation models. We will publish our SFT dataset and benchmark.
FastVLM: Efficient Vision Encoding for Vision Language Models
Dec 17, 2024



Scaling the input image resolution is essential for enhancing the performance of Vision Language Models (VLMs), particularly in text-rich image understanding tasks. However, popular visual encoders such as ViTs become inefficient at high resolutions due to the large number of tokens and high encoding latency caused by stacked self-attention layers. At different operational resolutions, the vision encoder of a VLM can be optimized along two axes: reducing encoding latency and minimizing the number of visual tokens passed to the LLM, thereby lowering overall latency. Based on a comprehensive efficiency analysis of the interplay between image resolution, vision latency, token count, and LLM size, we introduce FastVLM, a model that achieves an optimized trade-off between latency, model size and accuracy. FastVLM incorporates FastViTHD, a novel hybrid vision encoder designed to output fewer tokens and significantly reduce encoding time for high-resolution images. Unlike previous methods, FastVLM achieves the optimal balance between visual token count and image resolution solely by scaling the input image, eliminating the need for additional token pruning and simplifying the model design. In the LLaVA-1.5 setup, FastVLM achieves 3.2$\times$ improvement in time-to-first-token (TTFT) while maintaining similar performance on VLM benchmarks compared to prior works. Compared to LLaVa-OneVision at the highest resolution (1152$\times$1152), FastVLM achieves comparable performance on key benchmarks like SeedBench and MMMU, using the same 0.5B LLM, but with 85$\times$ faster TTFT and a vision encoder that is 3.4$\times$ smaller.
Revisit Large-Scale Image-Caption Data in Pre-training Multimodal Foundation Models
Oct 03, 2024Recent advancements in multimodal models highlight the value of rewritten captions for improving performance, yet key challenges remain. For example, while synthetic captions often provide superior quality and image-text alignment, it is not clear whether they can fully replace AltTexts: the role of synthetic captions and their interaction with original web-crawled AltTexts in pre-training is still not well understood. Moreover, different multimodal foundation models may have unique preferences for specific caption formats, but efforts to identify the optimal captions for each model remain limited. In this work, we propose a novel, controllable, and scalable captioning pipeline designed to generate diverse caption formats tailored to various multimodal models. By examining Short Synthetic Captions (SSC) towards Dense Synthetic Captions (DSC+) as case studies, we systematically explore their effects and interactions with AltTexts across models such as CLIP, multimodal LLMs, and diffusion models. Our findings reveal that a hybrid approach that keeps both synthetic captions and AltTexts can outperform the use of synthetic captions alone, improving both alignment and performance, with each model demonstrating preferences for particular caption formats. This comprehensive analysis provides valuable insights into optimizing captioning strategies, thereby advancing the pre-training of multimodal foundation models.
MM1.5: Methods, Analysis & Insights from Multimodal LLM Fine-tuning
Sep 30, 2024
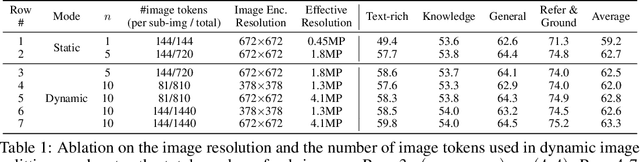

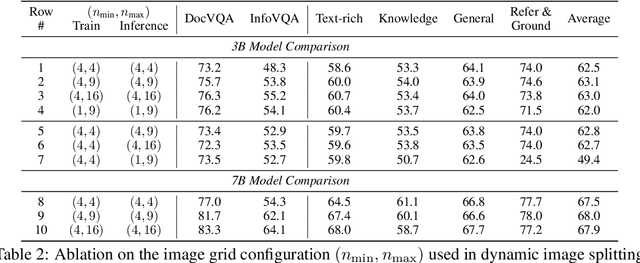
We present MM1.5, a new family of multimodal large language models (MLLMs) designed to enhance capabilities in text-rich image understanding, visual referring and grounding, and multi-image reasoning. Building upon the MM1 architecture, MM1.5 adopts a data-centric approach to model training, systematically exploring the impact of diverse data mixtures across the entire model training lifecycle. This includes high-quality OCR data and synthetic captions for continual pre-training, as well as an optimized visual instruction-tuning data mixture for supervised fine-tuning. Our models range from 1B to 30B parameters, encompassing both dense and mixture-of-experts (MoE) variants, and demonstrate that careful data curation and training strategies can yield strong performance even at small scales (1B and 3B). Additionally, we introduce two specialized variants: MM1.5-Video, designed for video understanding, and MM1.5-UI, tailored for mobile UI understanding. Through extensive empirical studies and ablations, we provide detailed insights into the training processes and decisions that inform our final designs, offering valuable guidance for future research in MLLM development.
Understanding Alignment in Multimodal LLMs: A Comprehensive Study
Jul 02, 2024



Preference alignment has become a crucial component in enhancing the performance of Large Language Models (LLMs), yet its impact in Multimodal Large Language Models (MLLMs) remains comparatively underexplored. Similar to language models, MLLMs for image understanding tasks encounter challenges like hallucination. In MLLMs, hallucination can occur not only by stating incorrect facts but also by producing responses that are inconsistent with the image content. A primary objective of alignment for MLLMs is to encourage these models to align responses more closely with image information. Recently, multiple works have introduced preference datasets for MLLMs and examined different alignment methods, including Direct Preference Optimization (DPO) and Proximal Policy Optimization (PPO). However, due to variations in datasets, base model types, and alignment methods, it remains unclear which specific elements contribute most significantly to the reported improvements in these works. In this paper, we independently analyze each aspect of preference alignment in MLLMs. We start by categorizing the alignment algorithms into two groups, offline (such as DPO), and online (such as online-DPO), and show that combining offline and online methods can improve the performance of the model in certain scenarios. We review a variety of published multimodal preference datasets and discuss how the details of their construction impact model performance. Based on these insights, we introduce a novel way of creating multimodal preference data called Bias-Driven Hallucination Sampling (BDHS) that needs neither additional annotation nor external models, and show that it can achieve competitive performance to previously published alignment work for multimodal models across a range of benchmarks.
MIA-Bench: Towards Better Instruction Following Evaluation of Multimodal LLMs
Jul 01, 2024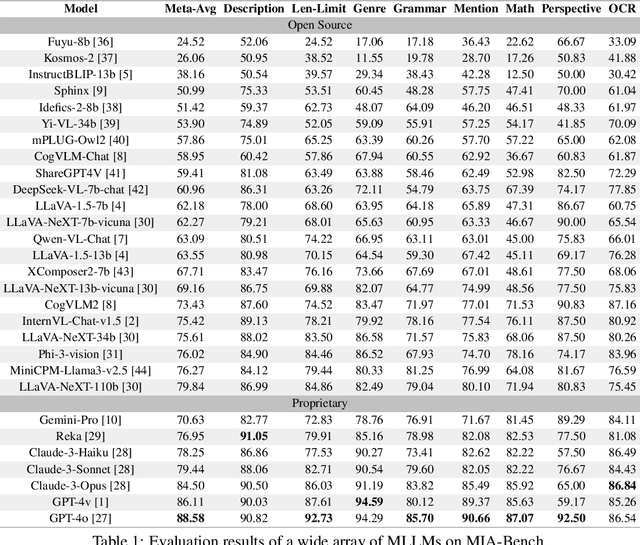
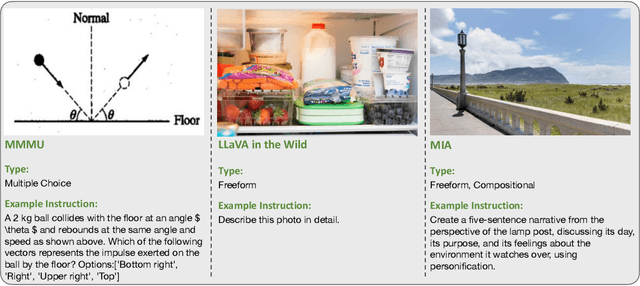
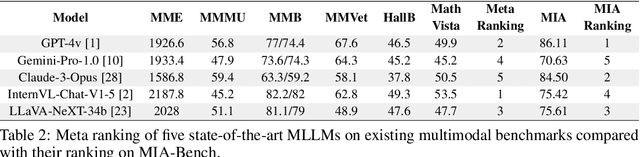
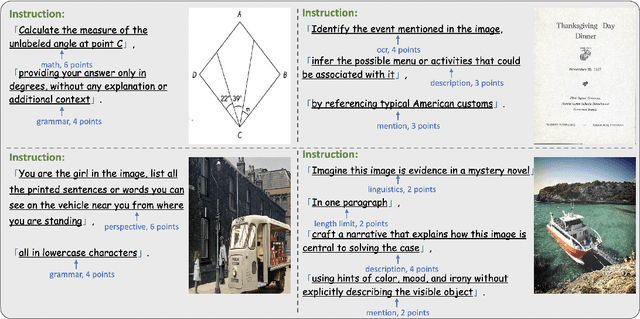
We introduce MIA-Bench, a new benchmark designed to evaluate multimodal large language models (MLLMs) on their ability to strictly adhere to complex instructions. Our benchmark comprises a diverse set of 400 image-prompt pairs, each crafted to challenge the models' compliance with layered instructions in generating accurate responses that satisfy specific requested patterns. Evaluation results from a wide array of state-of-the-art MLLMs reveal significant variations in performance, highlighting areas for improvement in instruction fidelity. Additionally, we create extra training data and explore supervised fine-tuning to enhance the models' ability to strictly follow instructions without compromising performance on other tasks. We hope this benchmark not only serves as a tool for measuring MLLM adherence to instructions, but also guides future developments in MLLM training methods.
MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training
Mar 22, 2024



In this work, we discuss building performant Multimodal Large Language Models (MLLMs). In particular, we study the importance of various architecture components and data choices. Through careful and comprehensive ablations of the image encoder, the vision language connector, and various pre-training data choices, we identified several crucial design lessons. For example, we demonstrate that for large-scale multimodal pre-training using a careful mix of image-caption, interleaved image-text, and text-only data is crucial for achieving state-of-the-art (SOTA) few-shot results across multiple benchmarks, compared to other published pre-training results. Further, we show that the image encoder together with image resolution and the image token count has substantial impact, while the vision-language connector design is of comparatively negligible importance. By scaling up the presented recipe, we build MM1, a family of multimodal models up to 30B parameters, including both dense models and mixture-of-experts (MoE) variants, that are SOTA in pre-training metrics and achieve competitive performance after supervised fine-tuning on a range of established multimodal benchmarks. Thanks to large-scale pre-training, MM1 enjoys appealing properties such as enhanced in-context learning, and multi-image reasoning, enabling few-shot chain-of-thought prompting.
Model Stability with Continuous Data Updates
Jan 14, 2022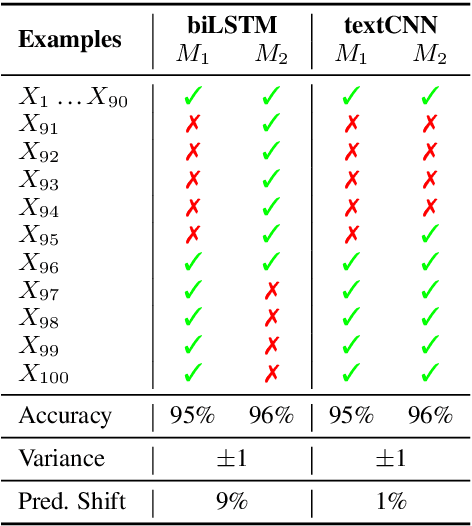
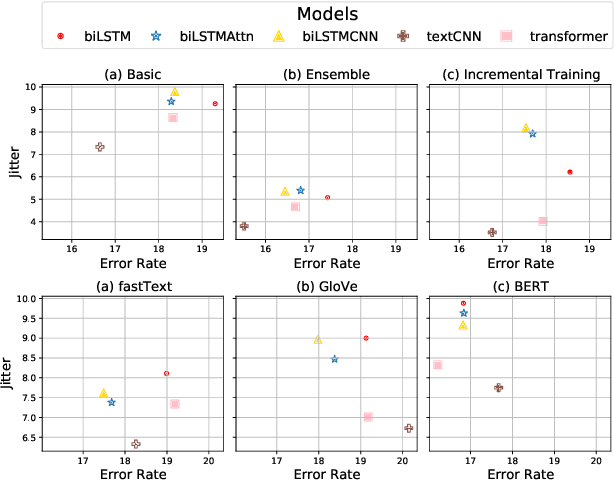
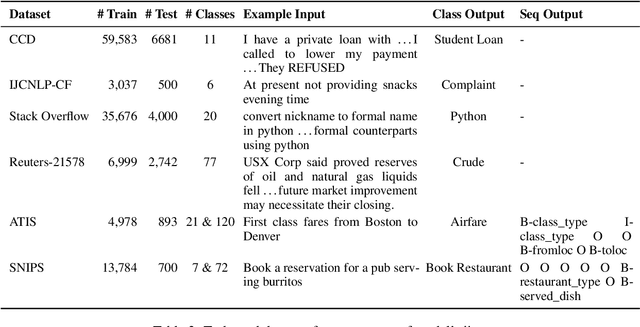
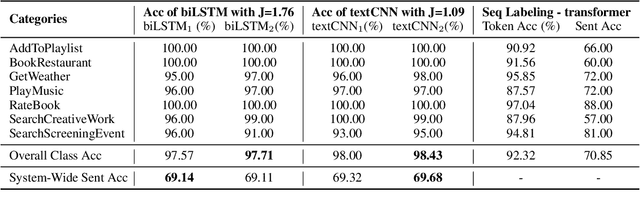
In this paper, we study the "stability" of machine learning (ML) models within the context of larger, complex NLP systems with continuous training data updates. For this study, we propose a methodology for the assessment of model stability (which we refer to as jitter under various experimental conditions. We find that model design choices, including network architecture and input representation, have a critical impact on stability through experiments on four text classification tasks and two sequence labeling tasks. In classification tasks, non-RNN-based models are observed to be more stable than RNN-based ones, while the encoder-decoder model is less stable in sequence labeling tasks. Moreover, input representations based on pre-trained fastText embeddings contribute to more stability than other choices. We also show that two learning strategies -- ensemble models and incremental training -- have a significant influence on stability. We recommend ML model designers account for trade-offs in accuracy and jitter when making modeling choices.
Noise-robust Named Entity Understanding for Virtual Assistants
May 29, 2020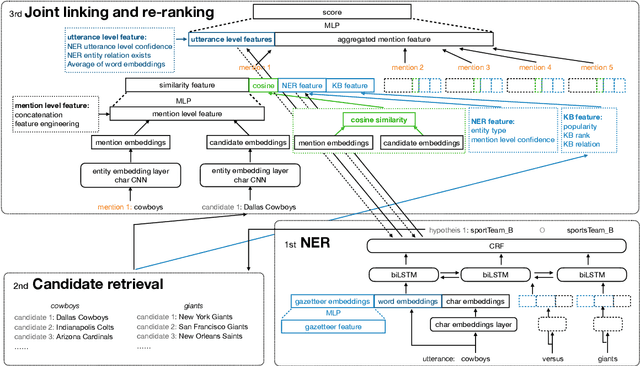
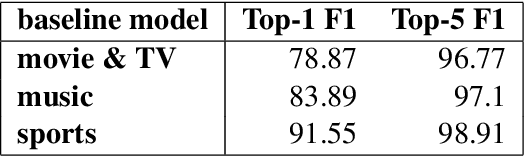
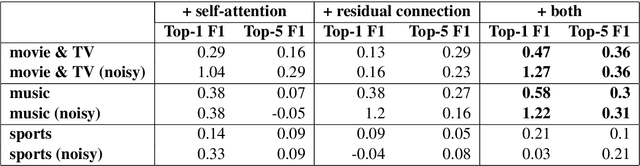
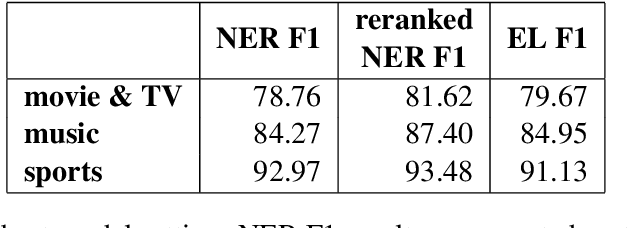
Named Entity Understanding (NEU) plays an essential role in interactions between users and voice assistants, since successfully identifying entities and correctly linking them to their standard forms is crucial to understanding the user's intent. NEU is a challenging task in voice assistants due to the ambiguous nature of natural language and because noise introduced by speech transcription and user errors occur frequently in spoken natural language queries. In this paper, we propose an architecture with novel features that jointly solves the recognition of named entities (a.k.a. Named Entity Recognition, or NER) and the resolution to their canonical forms (a.k.a. Entity Linking, or EL). We show that by combining NER and EL information in a joint reranking module, our proposed framework improves accuracy in both tasks. This improved performance and the features that enable it, also lead to better accuracy in downstream tasks, such as domain classification and semantic parsing.