 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMM-Spatial: Exploring 3D Spatial Understanding in Multimodal LLMs
Mar 17, 2025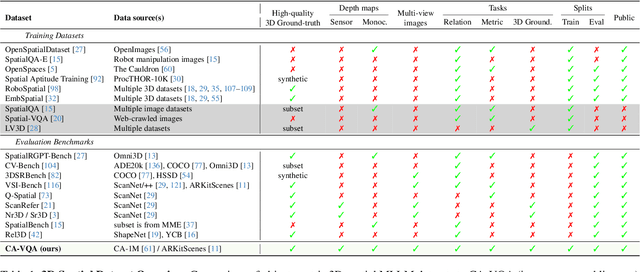

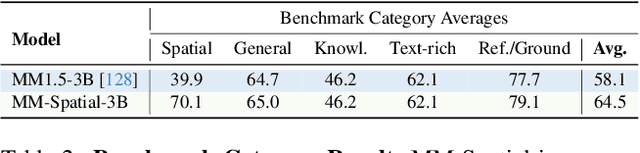

Multimodal large language models (MLLMs) excel at 2D visual understanding but remain limited in their ability to reason about 3D space. In this work, we leverage large-scale high-quality 3D scene data with open-set annotations to introduce 1) a novel supervised fine-tuning dataset and 2) a new evaluation benchmark, focused on indoor scenes. Our Cubify Anything VQA (CA-VQA) data covers diverse spatial tasks including spatial relationship prediction, metric size and distance estimation, and 3D grounding. We show that CA-VQA enables us to train MM-Spatial, a strong generalist MLLM that also achieves state-of-the-art performance on 3D spatial understanding benchmarks, including our own. We show how incorporating metric depth and multi-view inputs (provided in CA-VQA) can further improve 3D understanding, and demonstrate that data alone allows our model to achieve depth perception capabilities comparable to dedicated monocular depth estimation models. We will publish our SFT dataset and benchmark.
Cubify Anything: Scaling Indoor 3D Object Detection
Dec 05, 2024



We consider indoor 3D object detection with respect to a single RGB(-D) frame acquired from a commodity handheld device. We seek to significantly advance the status quo with respect to both data and modeling. First, we establish that existing datasets have significant limitations to scale, accuracy, and diversity of objects. As a result, we introduce the Cubify-Anything 1M (CA-1M) dataset, which exhaustively labels over 400K 3D objects on over 1K highly accurate laser-scanned scenes with near-perfect registration to over 3.5K handheld, egocentric captures. Next, we establish Cubify Transformer (CuTR), a fully Transformer 3D object detection baseline which rather than operating in 3D on point or voxel-based representations, predicts 3D boxes directly from 2D features derived from RGB(-D) inputs. While this approach lacks any 3D inductive biases, we show that paired with CA-1M, CuTR outperforms point-based methods - accurately recalling over 62% of objects in 3D, and is significantly more capable at handling noise and uncertainty present in commodity LiDAR-derived depth maps while also providing promising RGB only performance without architecture changes. Furthermore, by pre-training on CA-1M, CuTR can outperform point-based methods on a more diverse variant of SUN RGB-D - supporting the notion that while inductive biases in 3D are useful at the smaller sizes of existing datasets, they fail to scale to the data-rich regime of CA-1M. Overall, this dataset and baseline model provide strong evidence that we are moving towards models which can effectively Cubify Anything.
4M-21: An Any-to-Any Vision Model for Tens of Tasks and Modalities
Jun 14, 2024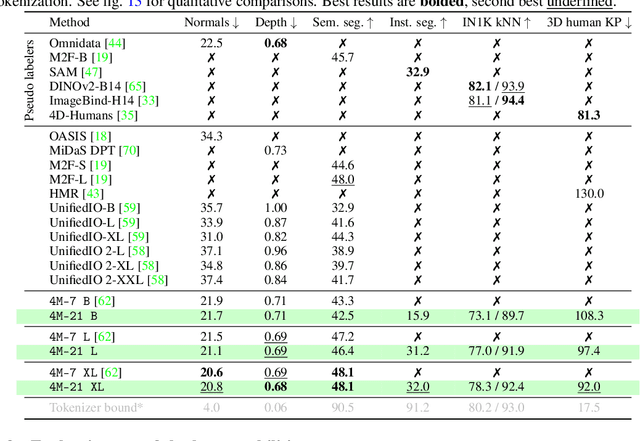

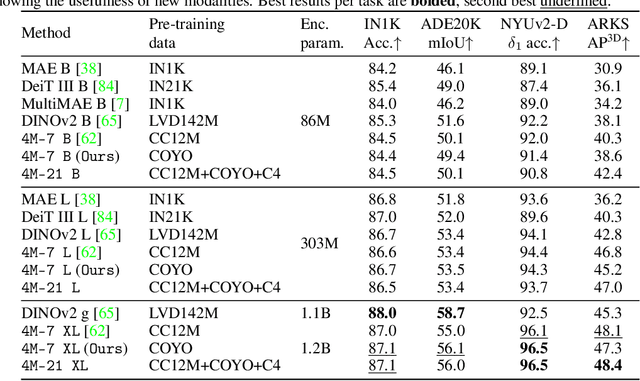
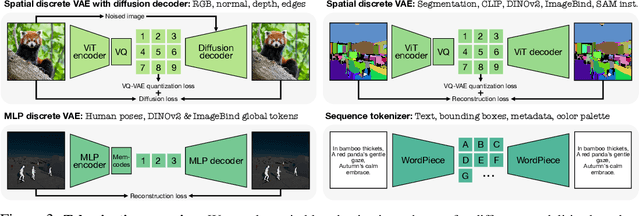
Current multimodal and multitask foundation models like 4M or UnifiedIO show promising results, but in practice their out-of-the-box abilities to accept diverse inputs and perform diverse tasks are limited by the (usually rather small) number of modalities and tasks they are trained on. In this paper, we expand upon the capabilities of them by training a single model on tens of highly diverse modalities and by performing co-training on large-scale multimodal datasets and text corpora. This includes training on several semantic and geometric modalities, feature maps from recent state of the art models like DINOv2 and ImageBind, pseudo labels of specialist models like SAM and 4DHumans, and a range of new modalities that allow for novel ways to interact with the model and steer the generation, for example image metadata or color palettes. A crucial step in this process is performing discrete tokenization on various modalities, whether they are image-like, neural network feature maps, vectors, structured data like instance segmentation or human poses, or data that can be represented as text. Through this, we expand on the out-of-the-box capabilities of multimodal models and specifically show the possibility of training one model to solve at least 3x more tasks/modalities than existing ones and doing so without a loss in performance. This enables more fine-grained and controllable multimodal generation capabilities and allows us to study the distillation of models trained on diverse data and objectives into a unified model. We successfully scale the training to a three billion parameter model using tens of modalities and different datasets. The resulting models and training code are open sourced at 4m.epfl.ch.
OutCast: Outdoor Single-image Relighting with Cast Shadows
Apr 20, 2022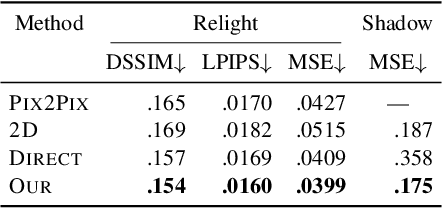
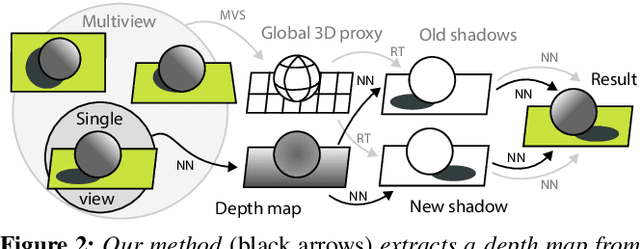
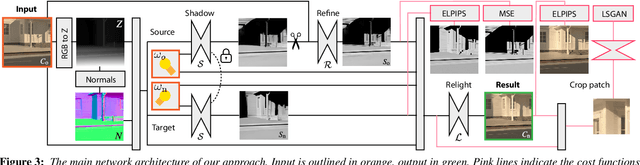
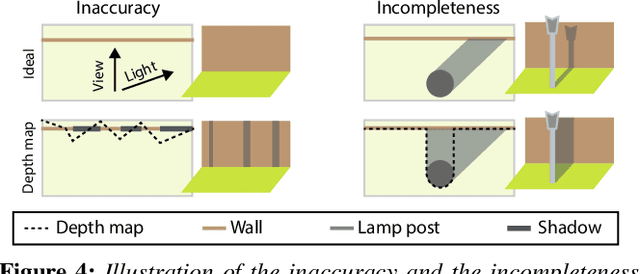
We propose a relighting method for outdoor images. Our method mainly focuses on predicting cast shadows in arbitrary novel lighting directions from a single image while also accounting for shading and global effects such the sun light color and clouds. Previous solutions for this problem rely on reconstructing occluder geometry, e.g. using multi-view stereo, which requires many images of the scene. Instead, in this work we make use of a noisy off-the-shelf single-image depth map estimation as a source of geometry. Whilst this can be a good guide for some lighting effects, the resulting depth map quality is insufficient for directly ray-tracing the shadows. Addressing this, we propose a learned image space ray-marching layer that converts the approximate depth map into a deep 3D representation that is fused into occlusion queries using a learned traversal. Our proposed method achieves, for the first time, state-of-the-art relighting results, with only a single image as input. For supplementary material visit our project page at: https://dgriffiths.uk/outcast.
Curiosity-driven 3D Scene Structure from Single-image Self-supervision
Dec 02, 2020


Previous work has demonstrated learning isolated 3D objects (voxel grids, point clouds, meshes, etc.) from 2D-only self-supervision. We here set out to extend this to entire 3D scenes made out of multiple objects, including their location, orientation and type, and the scenes illumination. Once learned, we can map arbitrary 2D images to 3D scene structure. We analyze why analysis-by-synthesis-like losses for supervision of 3D scene structure using differentiable rendering is not practical, as it almost always gets stuck in local minima of visual ambiguities. This can be overcome by a novel form of training: we use an additional network to steer the optimization itself to explore the full gamut of possible solutions i.e. to be curious, and hence, to resolve those ambiguities and find workable minima. The resulting system converts 2D images of different virtual or real images into complete 3D scenes, learned only from 2D images of those scenes.
Finding Your Center: 3D Object Detection Using a Learned Loss
Apr 06, 2020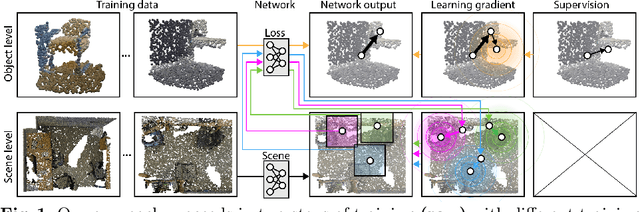



Massive semantic labeling is readily available for 2D images, but much harder to achieve for 3D scenes. Objects in 3D repositories like ShapeNet are labeled, but regrettably only in isolation, so without context. 3D scenes can be acquired by range scanners on city-level scale, but much fewer with semantic labels. Addressing this disparity, we introduce a new optimization procedure, which allows training for 3D detection with raw 3D scans while using as little as 5% of the object labels and still achieve comparable performance. Our optimization uses two networks. A scene network maps an entire 3D scene to a set of 3D object centers. As we assume the scene not to be labeled by centers, no classic loss, such as chamfer can be used to train it. Instead, we use another network to emulate the loss. This loss network is trained on a small labeled subset and maps a non-centered 3D object in the presence of distractions to its own center. This function is very similar - and hence can be used instead of - the gradient the supervised loss would have. Our evaluation documents competitive fidelity at a much lower level of supervision, respectively higher quality at comparable supervision. Supplementary material can be found at: https://dgriffiths3.github.io.
SynthCity: A large scale synthetic point cloud
Jul 10, 2019



With deep learning becoming a more prominent approach for automatic classification of three-dimensional point cloud data, a key bottleneck is the amount of high quality training data, especially when compared to that available for two-dimensional images. One potential solution is the use of synthetic data for pre-training networks, however the ability for models to generalise from synthetic data to real world data has been poorly studied for point clouds. Despite this, a huge wealth of 3D virtual environments exist which, if proved effective can be exploited. We therefore argue that research in this domain would be of significant use. In this paper we present SynthCity an open dataset to help aid research. SynthCity is a 367.9M point synthetic full colour Mobile Laser Scanning point cloud. Every point is assigned a label from one of nine categories. We generate our point cloud in a typical Urban/Suburban environment using the Blensor plugin for Blender.
A review on deep learning techniques for 3D sensed data classification
Jul 09, 2019
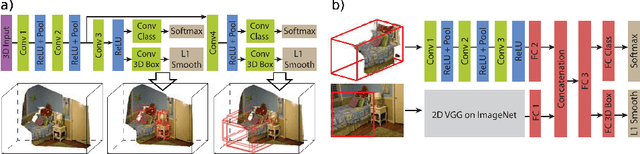
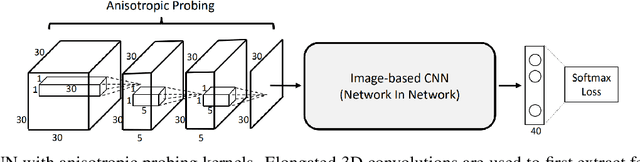
Over the past decade deep learning has driven progress in 2D image understanding. Despite these advancements, techniques for automatic 3D sensed data understanding, such as point clouds, is comparatively immature. However, with a range of important applications from indoor robotics navigation to national scale remote sensing there is a high demand for algorithms that can learn to automatically understand and classify 3D sensed data. In this paper we review the current state-of-the-art deep learning architectures for processing unstructured Euclidean data. We begin by addressing the background concepts and traditional methodologies. We review the current main approaches including; RGB-D, multi-view, volumetric and fully end-to-end architecture designs. Datasets for each category are documented and explained. Finally, we give a detailed discussion about the future of deep learning for 3D sensed data, using literature to justify the areas where future research would be most valuable.
Weighted Point Cloud Augmentation for Neural Network Training Data Class-Imbalance
Apr 09, 2019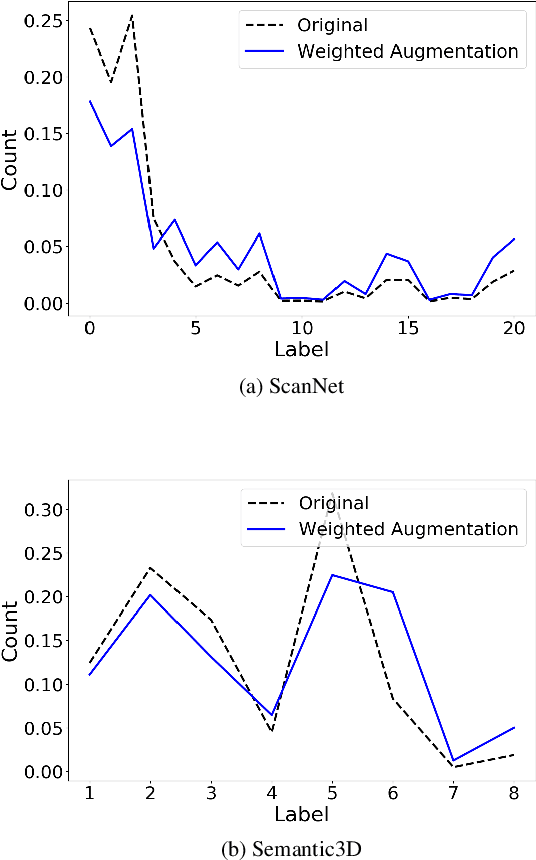



Recent developments in the field of deep learning for 3D data have demonstrated promising potential for end-to-end learning directly from point clouds. However, many real-world point clouds contain a large class im-balance due to the natural class im-balance observed in nature. For example, a 3D scan of an urban environment will consist mostly of road and facade, whereas other objects such as poles will be under-represented. In this paper we address this issue by employing a weighted augmentation to increase classes that contain fewer points. By mitigating the class im-balance present in the data we demonstrate that a standard PointNet++ deep neural network can achieve higher performance at inference on validation data. This was observed as an increase of F1 score of 19% and 25% on two test benchmark datasets; ScanNet and Semantic3D respectively where no class im-balance pre-processing had been performed. Our networks performed better on both highly-represented and under-represented classes, which indicates that the network is learning more robust and meaningful features when the loss function is not overly exposed to only a few classes.