 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster or Stronger: Towards Flexible Visual Place Recognition via Weighted Aggregation and Token Pruning
May 19, 2026Visual Place Recognition (VPR) aims to match a query image to reference images of the same place in a large-scale database. Recent state-of-the-art methods employ Vision Transformers (ViTs) as backbone foundation models to extract patch-level features that are robust to viewpoint, illumination, and seasonal variations, which are then aggregated into a compact global descriptor for retrieval. Most existing aggregation methods uniformly pool patch tokens into learned clusters, despite the fact that different clusters often encode distinct spatial or semantic patterns and contribute unequally to VPR performance. To address this limitation, we propose Weighted Aggregated Descriptor (WeiAD), which assigns weights to clusters during aggregation, producing more discriminative global representations. Beyond accuracy, retrieval latency is a critical concern for large-scale deployments and resource-constrained edge devices. Prior work mainly reduces latency by compressing global descriptors, while overlooking the cost of feature extraction, an issue exacerbated by ViT-based backbones. We therefore introduce WeiToP, a VPR-oriented token pruning framework that reduces feature extraction cost via self-distillation, where aggregation-induced token importance supervises a lightweight pruning module attached to an early transformer layer, enabling inference-time token pruning. After a single joint training phase, WeiToP enables plug-and-play token pruning at inference time, allowing flexible and on-demand control over the accuracy-efficiency trade-off without additional training. Moreover, WeiToP outperforms existing token pruning methods adapted from general vision tasks.
Real-Time LiDAR Super-Resolution via Frequency-Aware Multi-Scale Fusion
Nov 10, 2025LiDAR super-resolution addresses the challenge of achieving high-quality 3D perception from cost-effective, low-resolution sensors. While recent transformer-based approaches like TULIP show promise, they remain limited to spatial-domain processing with restricted receptive fields. We introduce FLASH (Frequency-aware LiDAR Adaptive Super-resolution with Hierarchical fusion), a novel framework that overcomes these limitations through dual-domain processing. FLASH integrates two key innovations: (i) Frequency-Aware Window Attention that combines local spatial attention with global frequency-domain analysis via FFT, capturing both fine-grained geometry and periodic scanning patterns at log-linear complexity. (ii) Adaptive Multi-Scale Fusion that replaces conventional skip connections with learned position-specific feature aggregation, enhanced by CBAM attention for dynamic feature selection. Extensive experiments on KITTI demonstrate that FLASH achieves state-of-the-art performance across all evaluation metrics, surpassing even uncertainty-enhanced baselines that require multiple forward passes. Notably, FLASH outperforms TULIP with Monte Carlo Dropout while maintaining single-pass efficiency, which enables real-time deployment. The consistent superiority across all distance ranges validates that our dual-domain approach effectively handles uncertainty through architectural design rather than computationally expensive stochastic inference, making it practical for autonomous systems.
Hybrid-Segmentor: A Hybrid Approach to Automated Fine-Grained Crack Segmentation in Civil Infrastructure
Sep 04, 2024
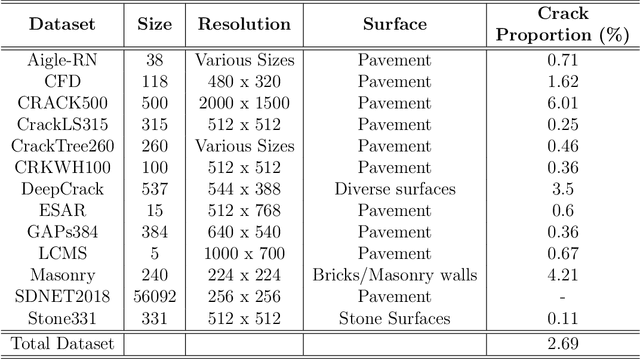

Detecting and segmenting cracks in infrastructure, such as roads and buildings, is crucial for safety and cost-effective maintenance. In spite of the potential of deep learning, there are challenges in achieving precise results and handling diverse crack types. With the proposed dataset and model, we aim to enhance crack detection and infrastructure maintenance. We introduce Hybrid-Segmentor, an encoder-decoder based approach that is capable of extracting both fine-grained local and global crack features. This allows the model to improve its generalization capabilities in distinguish various type of shapes, surfaces and sizes of cracks. To keep the computational performances low for practical purposes, while maintaining the high the generalization capabilities of the model, we incorporate a self-attention model at the encoder level, while reducing the complexity of the decoder component. The proposed model outperforms existing benchmark models across 5 quantitative metrics (accuracy 0.971, precision 0.804, recall 0.744, F1-score 0.770, and IoU score 0.630), achieving state-of-the-art status.
Zero-shot detection of buildings in mobile LiDAR using Language Vision Model
Apr 15, 2024
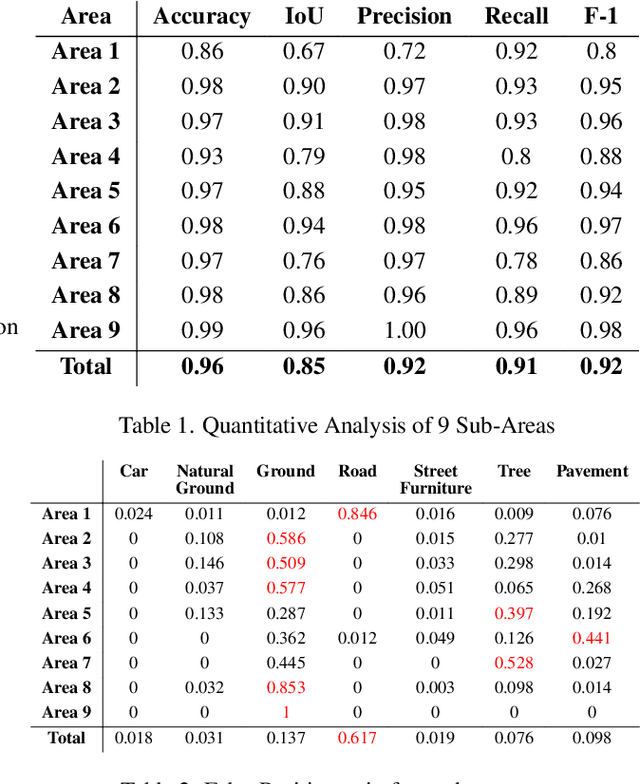

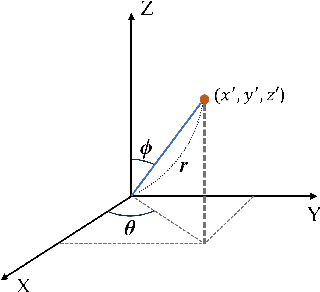
Recent advances have demonstrated that Language Vision Models (LVMs) surpass the existing State-of-the-Art (SOTA) in two-dimensional (2D) computer vision tasks, motivating attempts to apply LVMs to three-dimensional (3D) data. While LVMs are efficient and effective in addressing various downstream 2D vision tasks without training, they face significant challenges when it comes to point clouds, a representative format for representing 3D data. It is more difficult to extract features from 3D data and there are challenges due to large data sizes and the cost of the collection and labelling, resulting in a notably limited availability of datasets. Moreover, constructing LVMs for point clouds is even more challenging due to the requirements for large amounts of data and training time. To address these issues, our research aims to 1) apply the Grounded SAM through Spherical Projection to transfer 3D to 2D, and 2) experiment with synthetic data to evaluate its effectiveness in bridging the gap between synthetic and real-world data domains. Our approach exhibited high performance with an accuracy of 0.96, an IoU of 0.85, precision of 0.92, recall of 0.91, and an F1 score of 0.92, confirming its potential. However, challenges such as occlusion problems and pixel-level overlaps of multi-label points during spherical image generation remain to be addressed in future studies.
Zero-shot Building Age Classification from Facade Image Using GPT-4
Apr 15, 2024

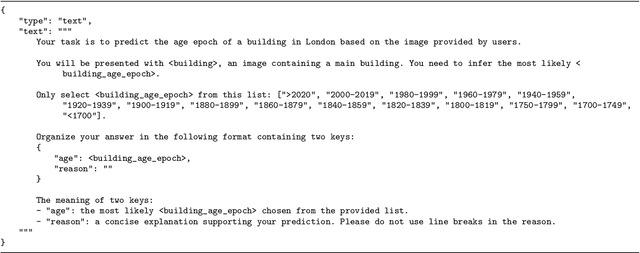

A building's age of construction is crucial for supporting many geospatial applications. Much current research focuses on estimating building age from facade images using deep learning. However, building an accurate deep learning model requires a considerable amount of labelled training data, and the trained models often have geographical constraints. Recently, large pre-trained vision language models (VLMs) such as GPT-4 Vision, which demonstrate significant generalisation capabilities, have emerged as potential training-free tools for dealing with specific vision tasks, but their applicability and reliability for building information remain unexplored. In this study, a zero-shot building age classifier for facade images is developed using prompts that include logical instructions. Taking London as a test case, we introduce a new dataset, FI-London, comprising facade images and building age epochs. Although the training-free classifier achieved a modest accuracy of 39.69%, the mean absolute error of 0.85 decades indicates that the model can predict building age epochs successfully albeit with a small bias. The ensuing discussion reveals that the classifier struggles to predict the age of very old buildings and is challenged by fine-grained predictions within 2 decades. Overall, the classifier utilising GPT-4 Vision is capable of predicting the rough age epoch of a building from a single facade image without any training.
Curiosity-driven 3D Scene Structure from Single-image Self-supervision
Dec 02, 2020


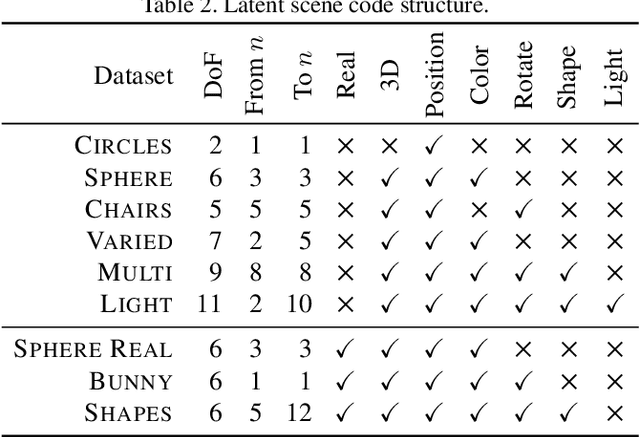
Previous work has demonstrated learning isolated 3D objects (voxel grids, point clouds, meshes, etc.) from 2D-only self-supervision. We here set out to extend this to entire 3D scenes made out of multiple objects, including their location, orientation and type, and the scenes illumination. Once learned, we can map arbitrary 2D images to 3D scene structure. We analyze why analysis-by-synthesis-like losses for supervision of 3D scene structure using differentiable rendering is not practical, as it almost always gets stuck in local minima of visual ambiguities. This can be overcome by a novel form of training: we use an additional network to steer the optimization itself to explore the full gamut of possible solutions i.e. to be curious, and hence, to resolve those ambiguities and find workable minima. The resulting system converts 2D images of different virtual or real images into complete 3D scenes, learned only from 2D images of those scenes.
Finding Your Center: 3D Object Detection Using a Learned Loss
Apr 06, 2020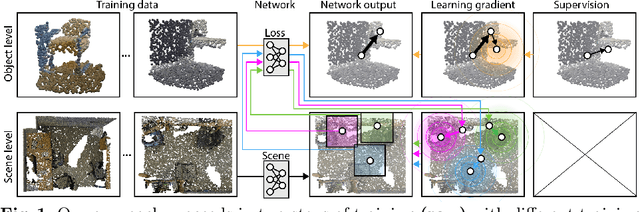



Massive semantic labeling is readily available for 2D images, but much harder to achieve for 3D scenes. Objects in 3D repositories like ShapeNet are labeled, but regrettably only in isolation, so without context. 3D scenes can be acquired by range scanners on city-level scale, but much fewer with semantic labels. Addressing this disparity, we introduce a new optimization procedure, which allows training for 3D detection with raw 3D scans while using as little as 5% of the object labels and still achieve comparable performance. Our optimization uses two networks. A scene network maps an entire 3D scene to a set of 3D object centers. As we assume the scene not to be labeled by centers, no classic loss, such as chamfer can be used to train it. Instead, we use another network to emulate the loss. This loss network is trained on a small labeled subset and maps a non-centered 3D object in the presence of distractions to its own center. This function is very similar - and hence can be used instead of - the gradient the supervised loss would have. Our evaluation documents competitive fidelity at a much lower level of supervision, respectively higher quality at comparable supervision. Supplementary material can be found at: https://dgriffiths3.github.io.
SynthCity: A large scale synthetic point cloud
Jul 10, 2019



With deep learning becoming a more prominent approach for automatic classification of three-dimensional point cloud data, a key bottleneck is the amount of high quality training data, especially when compared to that available for two-dimensional images. One potential solution is the use of synthetic data for pre-training networks, however the ability for models to generalise from synthetic data to real world data has been poorly studied for point clouds. Despite this, a huge wealth of 3D virtual environments exist which, if proved effective can be exploited. We therefore argue that research in this domain would be of significant use. In this paper we present SynthCity an open dataset to help aid research. SynthCity is a 367.9M point synthetic full colour Mobile Laser Scanning point cloud. Every point is assigned a label from one of nine categories. We generate our point cloud in a typical Urban/Suburban environment using the Blensor plugin for Blender.
A review on deep learning techniques for 3D sensed data classification
Jul 09, 2019
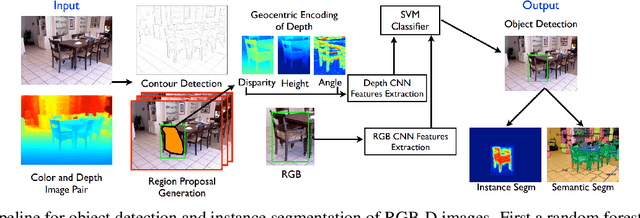
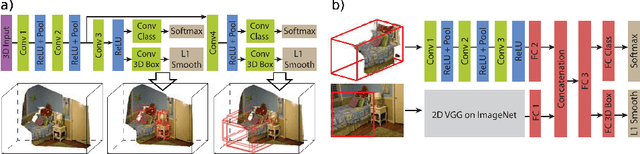
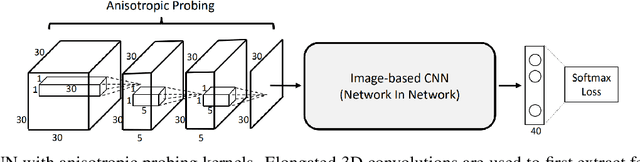
Over the past decade deep learning has driven progress in 2D image understanding. Despite these advancements, techniques for automatic 3D sensed data understanding, such as point clouds, is comparatively immature. However, with a range of important applications from indoor robotics navigation to national scale remote sensing there is a high demand for algorithms that can learn to automatically understand and classify 3D sensed data. In this paper we review the current state-of-the-art deep learning architectures for processing unstructured Euclidean data. We begin by addressing the background concepts and traditional methodologies. We review the current main approaches including; RGB-D, multi-view, volumetric and fully end-to-end architecture designs. Datasets for each category are documented and explained. Finally, we give a detailed discussion about the future of deep learning for 3D sensed data, using literature to justify the areas where future research would be most valuable.
Weighted Point Cloud Augmentation for Neural Network Training Data Class-Imbalance
Apr 09, 2019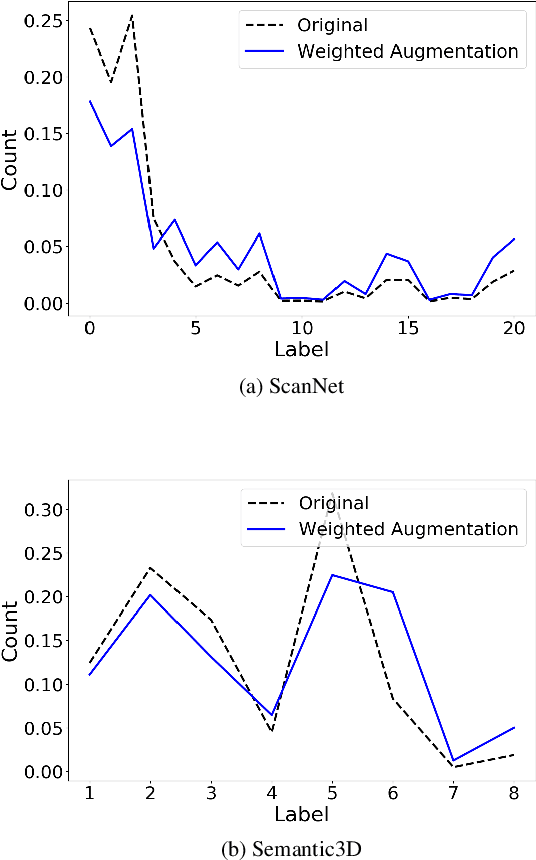



Recent developments in the field of deep learning for 3D data have demonstrated promising potential for end-to-end learning directly from point clouds. However, many real-world point clouds contain a large class im-balance due to the natural class im-balance observed in nature. For example, a 3D scan of an urban environment will consist mostly of road and facade, whereas other objects such as poles will be under-represented. In this paper we address this issue by employing a weighted augmentation to increase classes that contain fewer points. By mitigating the class im-balance present in the data we demonstrate that a standard PointNet++ deep neural network can achieve higher performance at inference on validation data. This was observed as an increase of F1 score of 19% and 25% on two test benchmark datasets; ScanNet and Semantic3D respectively where no class im-balance pre-processing had been performed. Our networks performed better on both highly-represented and under-represented classes, which indicates that the network is learning more robust and meaningful features when the loss function is not overly exposed to only a few classes.