 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time LiDAR Super-Resolution via Frequency-Aware Multi-Scale Fusion
Nov 10, 2025LiDAR super-resolution addresses the challenge of achieving high-quality 3D perception from cost-effective, low-resolution sensors. While recent transformer-based approaches like TULIP show promise, they remain limited to spatial-domain processing with restricted receptive fields. We introduce FLASH (Frequency-aware LiDAR Adaptive Super-resolution with Hierarchical fusion), a novel framework that overcomes these limitations through dual-domain processing. FLASH integrates two key innovations: (i) Frequency-Aware Window Attention that combines local spatial attention with global frequency-domain analysis via FFT, capturing both fine-grained geometry and periodic scanning patterns at log-linear complexity. (ii) Adaptive Multi-Scale Fusion that replaces conventional skip connections with learned position-specific feature aggregation, enhanced by CBAM attention for dynamic feature selection. Extensive experiments on KITTI demonstrate that FLASH achieves state-of-the-art performance across all evaluation metrics, surpassing even uncertainty-enhanced baselines that require multiple forward passes. Notably, FLASH outperforms TULIP with Monte Carlo Dropout while maintaining single-pass efficiency, which enables real-time deployment. The consistent superiority across all distance ranges validates that our dual-domain approach effectively handles uncertainty through architectural design rather than computationally expensive stochastic inference, making it practical for autonomous systems.
Multimodal Contrastive Learning of Urban Space Representations from POI Data
Nov 09, 2024Existing methods for learning urban space representations from Point-of-Interest (POI) data face several limitations, including issues with geographical delineation, inadequate spatial information modelling, underutilisation of POI semantic attributes, and computational inefficiencies. To address these issues, we propose CaLLiPer (Contrastive Language-Location Pre-training), a novel representation learning model that directly embeds continuous urban spaces into vector representations that can capture the spatial and semantic distribution of urban environment. This model leverages a multimodal contrastive learning objective, aligning location embeddings with textual POI descriptions, thereby bypassing the need for complex training corpus construction and negative sampling. We validate CaLLiPer's effectiveness by applying it to learning urban space representations in London, UK, where it demonstrates 5-15% improvement in predictive performance for land use classification and socioeconomic mapping tasks compared to state-of-the-art methods. Visualisations of the learned representations further illustrate our model's advantages in capturing spatial variations in urban semantics with high accuracy and fine resolution. Additionally, CaLLiPer achieves reduced training time, showcasing its efficiency and scalability. This work provides a promising pathway for scalable, semantically rich urban space representation learning that can support the development of geospatial foundation models. The implementation code is available at https://github.com/xlwang233/CaLLiPer.
V-RoAst: A New Dataset for Visual Road Assessment
Aug 21, 2024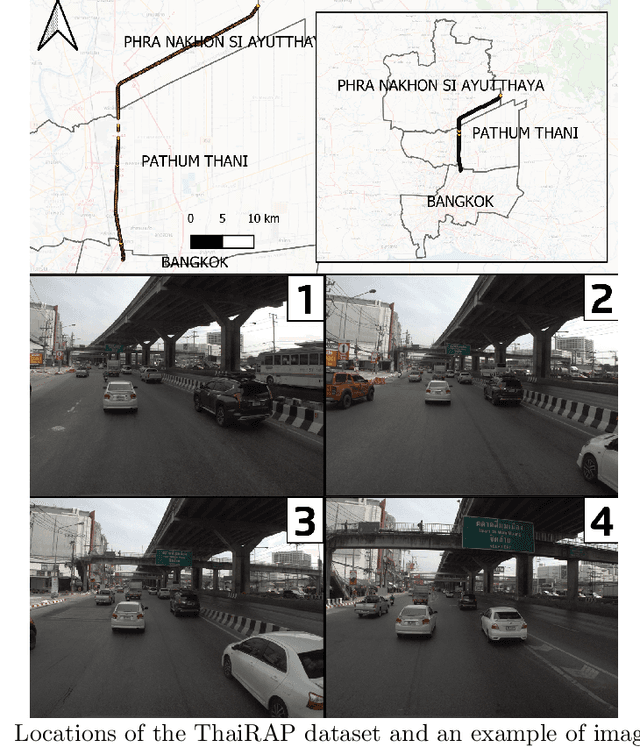
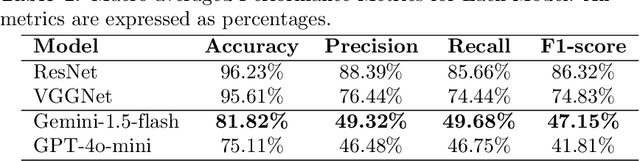
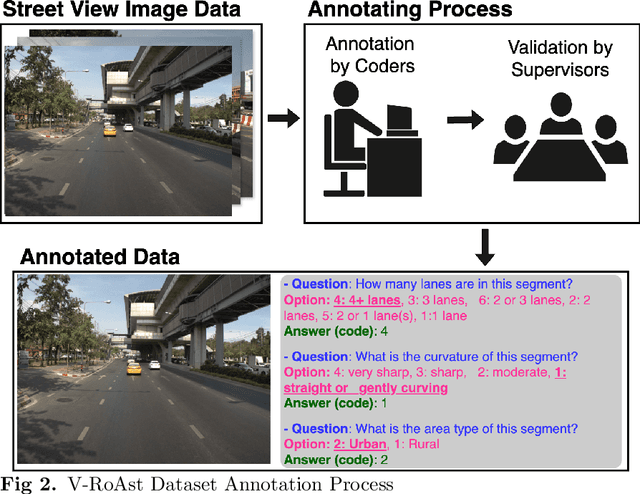
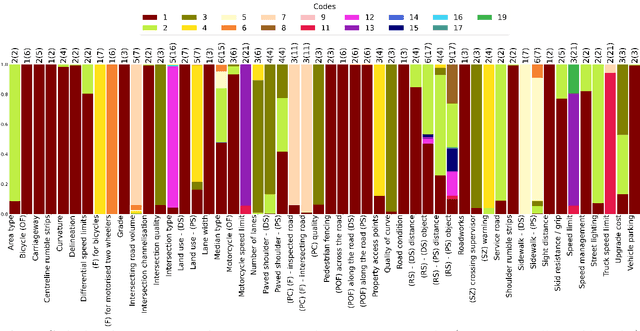
Road traffic crashes cause millions of deaths annually and have a significant economic impact, particularly in low- and middle-income countries (LMICs). This paper presents an approach using Vision Language Models (VLMs) for road safety assessment, overcoming the limitations of traditional Convolutional Neural Networks (CNNs). We introduce a new task ,V-RoAst (Visual question answering for Road Assessment), with a real-world dataset. Our approach optimizes prompt engineering and evaluates advanced VLMs, including Gemini-1.5-flash and GPT-4o-mini. The models effectively examine attributes for road assessment. Using crowdsourced imagery from Mapillary, our scalable solution influentially estimates road safety levels. In addition, this approach is designed for local stakeholders who lack resources, as it does not require training data. It offers a cost-effective and automated methods for global road safety assessments, potentially saving lives and reducing economic burdens.
Zero-shot Building Age Classification from Facade Image Using GPT-4
Apr 15, 2024

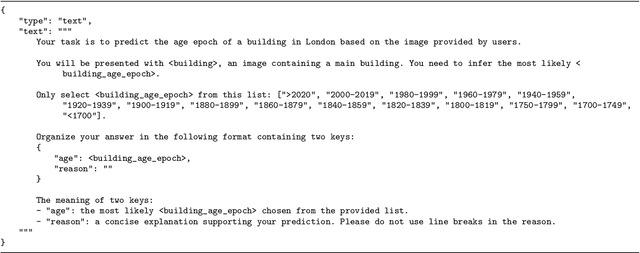

A building's age of construction is crucial for supporting many geospatial applications. Much current research focuses on estimating building age from facade images using deep learning. However, building an accurate deep learning model requires a considerable amount of labelled training data, and the trained models often have geographical constraints. Recently, large pre-trained vision language models (VLMs) such as GPT-4 Vision, which demonstrate significant generalisation capabilities, have emerged as potential training-free tools for dealing with specific vision tasks, but their applicability and reliability for building information remain unexplored. In this study, a zero-shot building age classifier for facade images is developed using prompts that include logical instructions. Taking London as a test case, we introduce a new dataset, FI-London, comprising facade images and building age epochs. Although the training-free classifier achieved a modest accuracy of 39.69%, the mean absolute error of 0.85 decades indicates that the model can predict building age epochs successfully albeit with a small bias. The ensuing discussion reveals that the classifier struggles to predict the age of very old buildings and is challenged by fine-grained predictions within 2 decades. Overall, the classifier utilising GPT-4 Vision is capable of predicting the rough age epoch of a building from a single facade image without any training.
Zero-shot detection of buildings in mobile LiDAR using Language Vision Model
Apr 15, 2024
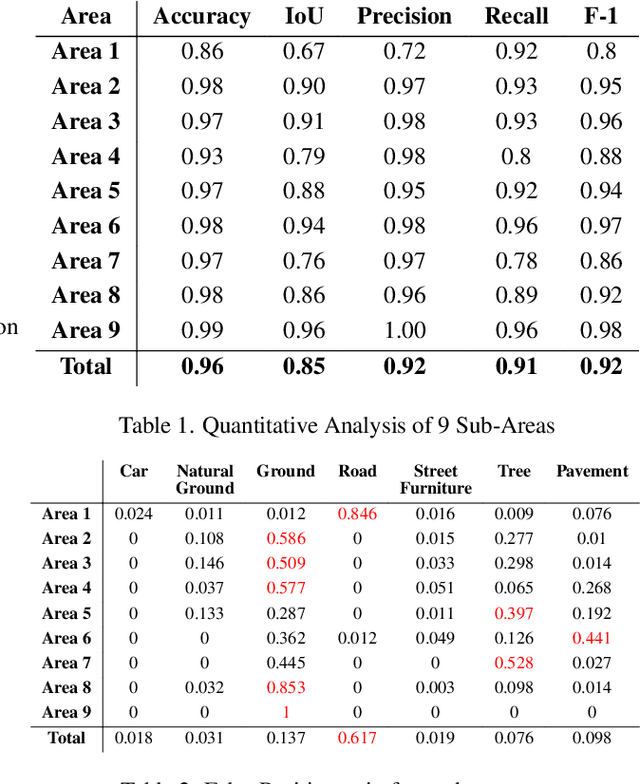

Recent advances have demonstrated that Language Vision Models (LVMs) surpass the existing State-of-the-Art (SOTA) in two-dimensional (2D) computer vision tasks, motivating attempts to apply LVMs to three-dimensional (3D) data. While LVMs are efficient and effective in addressing various downstream 2D vision tasks without training, they face significant challenges when it comes to point clouds, a representative format for representing 3D data. It is more difficult to extract features from 3D data and there are challenges due to large data sizes and the cost of the collection and labelling, resulting in a notably limited availability of datasets. Moreover, constructing LVMs for point clouds is even more challenging due to the requirements for large amounts of data and training time. To address these issues, our research aims to 1) apply the Grounded SAM through Spherical Projection to transfer 3D to 2D, and 2) experiment with synthetic data to evaluate its effectiveness in bridging the gap between synthetic and real-world data domains. Our approach exhibited high performance with an accuracy of 0.96, an IoU of 0.85, precision of 0.92, recall of 0.91, and an F1 score of 0.92, confirming its potential. However, challenges such as occlusion problems and pixel-level overlaps of multi-label points during spherical image generation remain to be addressed in future studies.
Where Would I Go Next? Large Language Models as Human Mobility Predictors
Aug 29, 2023

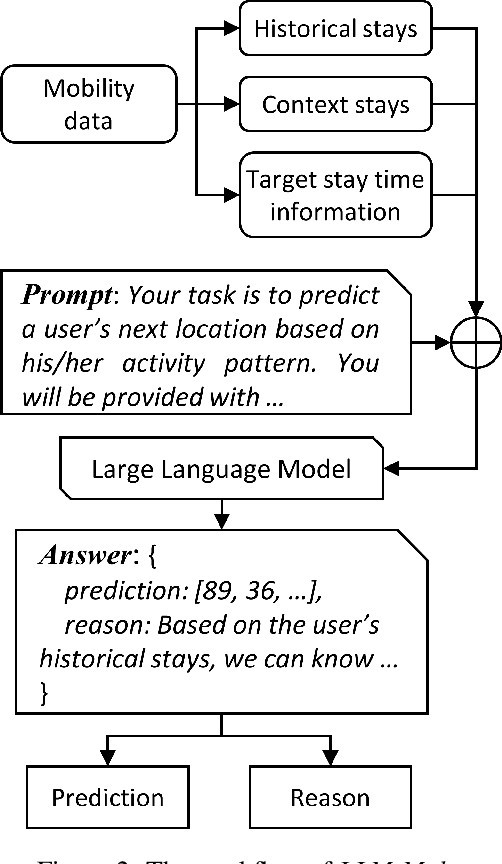

Accurate human mobility prediction underpins many important applications across a variety of domains, including epidemic modelling, transport planning, and emergency responses. Due to the sparsity of mobility data and the stochastic nature of people's daily activities, achieving precise predictions of people's locations remains a challenge. While recently developed large language models (LLMs) have demonstrated superior performance across numerous language-related tasks, their applicability to human mobility studies remains unexplored. Addressing this gap, this article delves into the potential of LLMs for human mobility prediction tasks. We introduce a novel method, LLM-Mob, which leverages the language understanding and reasoning capabilities of LLMs for analysing human mobility data. We present concepts of historical stays and context stays to capture both long-term and short-term dependencies in human movement and enable time-aware prediction by using time information of the prediction target. Additionally, we design context-inclusive prompts that enable LLMs to generate more accurate predictions. Comprehensive evaluations of our method reveal that LLM-Mob excels in providing accurate and interpretable predictions, highlighting the untapped potential of LLMs in advancing human mobility prediction techniques. We posit that our research marks a significant paradigm shift in human mobility modelling, transitioning from building complex domain-specific models to harnessing general-purpose LLMs that yield accurate predictions through language instructions. The code for this work is available at https://github.com/xlwang233/LLM-Mob.