 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV-RoAst: A New Dataset for Visual Road Assessment
Aug 21, 2024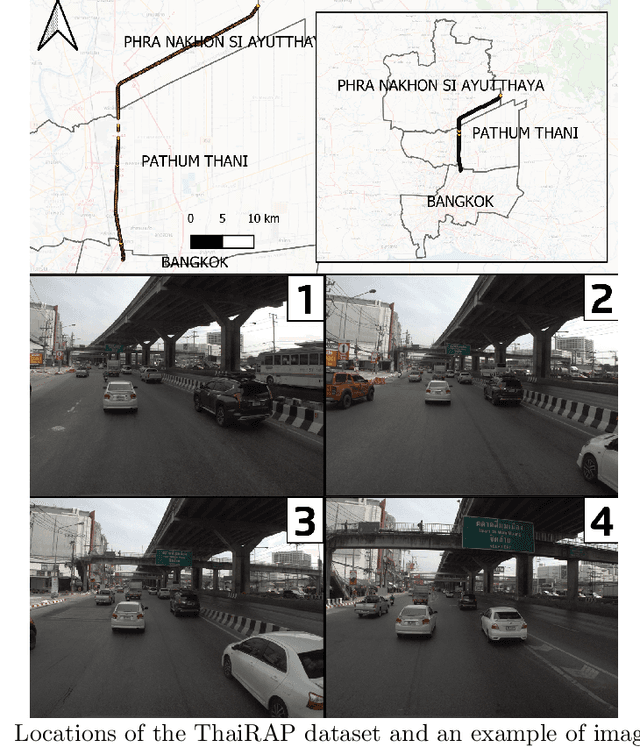
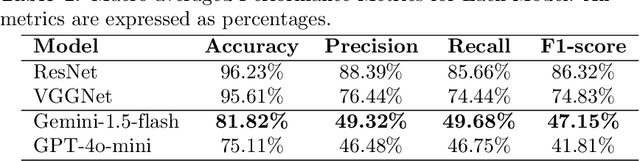
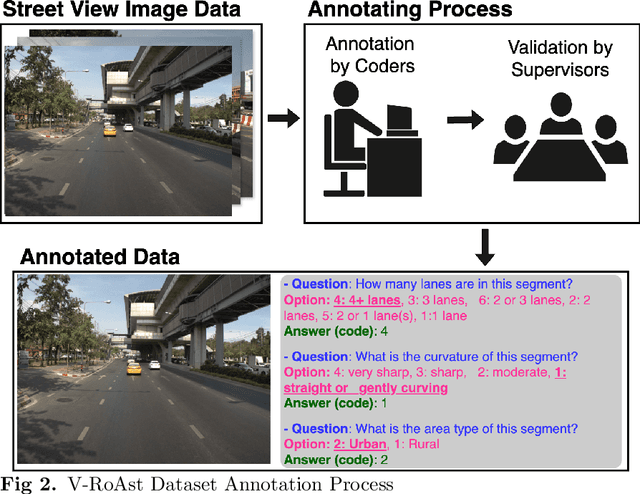
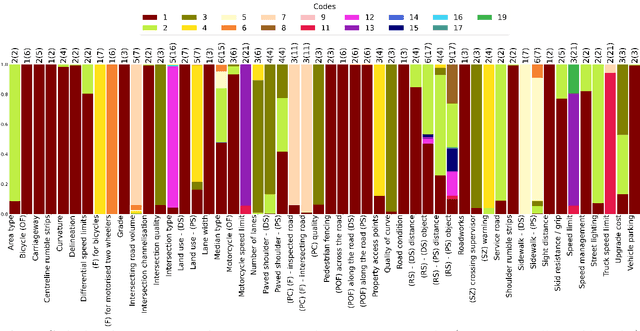
Road traffic crashes cause millions of deaths annually and have a significant economic impact, particularly in low- and middle-income countries (LMICs). This paper presents an approach using Vision Language Models (VLMs) for road safety assessment, overcoming the limitations of traditional Convolutional Neural Networks (CNNs). We introduce a new task ,V-RoAst (Visual question answering for Road Assessment), with a real-world dataset. Our approach optimizes prompt engineering and evaluates advanced VLMs, including Gemini-1.5-flash and GPT-4o-mini. The models effectively examine attributes for road assessment. Using crowdsourced imagery from Mapillary, our scalable solution influentially estimates road safety levels. In addition, this approach is designed for local stakeholders who lack resources, as it does not require training data. It offers a cost-effective and automated methods for global road safety assessments, potentially saving lives and reducing economic burdens.
Multiple Object Detection and Tracking in Panoramic Videos for Cycling Safety Analysis
Jul 21, 2024



Panoramic cycling videos can record 360{\deg} views around the cyclists. Thus, it is essential to conduct automatic road user analysis on them using computer vision models to provide data for studies on cycling safety. However, the features of panoramic data such as severe distortions, large number of small objects and boundary continuity have brought great challenges to the existing CV models, including poor performance and evaluation methods that are no longer applicable. In addition, due to the lack of data with annotations, it is not easy to re-train the models. In response to these problems, the project proposed and implemented a three-step methodology: (1) improve the prediction performance of the pre-trained object detection models on panoramic data by projecting the original image into 4 perspective sub-images; (2) introduce supports for boundary continuity and category information into DeepSORT, a commonly used multiple object tracking model, and set an improved detection model as its detector; (3) using the tracking results, develop an application for detecting the overtaking behaviour of the surrounding vehicles. Evaluated on the panoramic cycling dataset built by the project, the proposed methodology improves the average precision of YOLO v5m6 and Faster RCNN-FPN under any input resolution setting. In addition, it raises MOTA and IDF1 of DeepSORT by 7.6\% and 9.7\% respectively. When detecting the overtakes in the test videos, it achieves the F-score of 0.88. The code is available on GitHub at github.com/cuppp1998/360_object_tracking to ensure the reproducibility and further improvements of results.
Quantifying Geospatial in the Common Crawl Corpus
Jun 07, 2024Large language models (LLMs) exhibit emerging geospatial capabilities, stemming from their pre-training on vast unlabelled text datasets that are often derived from the Common Crawl corpus. However, the geospatial content within CC remains largely unexplored, impacting our understanding of LLMs' spatial reasoning. This paper investigates the prevalence of geospatial data in recent Common Crawl releases using Gemini, a powerful language model. By analyzing a sample of documents and manually revising the results, we estimate that between 1 in 5 and 1 in 6 documents contain geospatial information such as coordinates and street addresses. Our findings provide quantitative insights into the nature and extent of geospatial data within Common Crawl, and web crawl data in general. Furthermore, we formulate questions to guide future investigations into the geospatial content of available web crawl datasets and its influence on LLMs.
Zero-shot Building Age Classification from Facade Image Using GPT-4
Apr 15, 2024

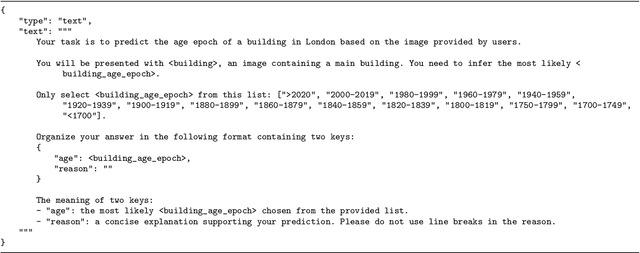

A building's age of construction is crucial for supporting many geospatial applications. Much current research focuses on estimating building age from facade images using deep learning. However, building an accurate deep learning model requires a considerable amount of labelled training data, and the trained models often have geographical constraints. Recently, large pre-trained vision language models (VLMs) such as GPT-4 Vision, which demonstrate significant generalisation capabilities, have emerged as potential training-free tools for dealing with specific vision tasks, but their applicability and reliability for building information remain unexplored. In this study, a zero-shot building age classifier for facade images is developed using prompts that include logical instructions. Taking London as a test case, we introduce a new dataset, FI-London, comprising facade images and building age epochs. Although the training-free classifier achieved a modest accuracy of 39.69%, the mean absolute error of 0.85 decades indicates that the model can predict building age epochs successfully albeit with a small bias. The ensuing discussion reveals that the classifier struggles to predict the age of very old buildings and is challenged by fine-grained predictions within 2 decades. Overall, the classifier utilising GPT-4 Vision is capable of predicting the rough age epoch of a building from a single facade image without any training.
Attention-based Ingredient Phrase Parser
Oct 05, 2022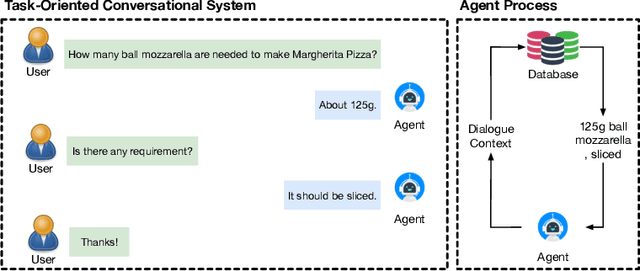
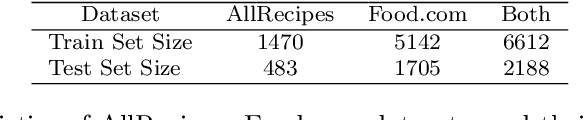
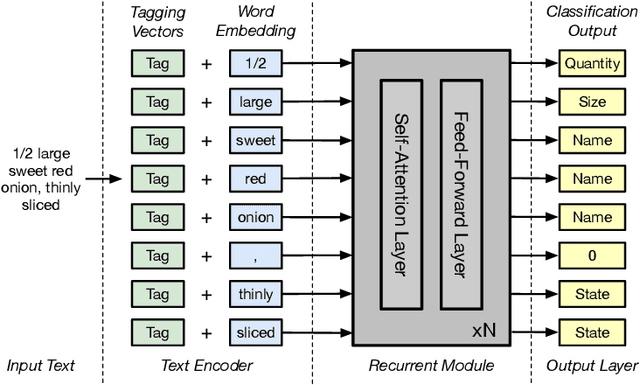
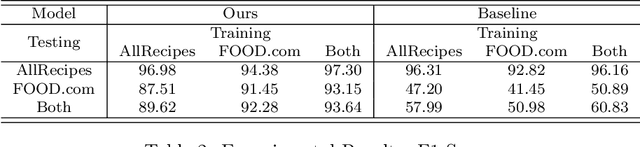
As virtual personal assistants have now penetrated the consumer market, with products such as Siri and Alexa, the research community has produced several works on task-oriented dialogue tasks such as hotel booking, restaurant booking, and movie recommendation. Assisting users to cook is one of these tasks that are expected to be solved by intelligent assistants, where ingredients and their corresponding attributes, such as name, unit, and quantity, should be provided to users precisely and promptly. However, existing ingredient information scraped from the cooking website is in the unstructured form with huge variation in the lexical structure, for example, '1 garlic clove, crushed', and '1 (8 ounce) package cream cheese, softened', making it difficult to extract information exactly. To provide an engaged and successful conversational service to users for cooking tasks, we propose a new ingredient parsing model that can parse an ingredient phrase of recipes into the structure form with its corresponding attributes with over 0.93 F1-score. Experimental results show that our model achieves state-of-the-art performance on AllRecipes and Food.com datasets.