 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterplay: Training Independent Simulators for Reference-Free Conversational Recommendation
Mar 19, 2026Training conversational recommender systems (CRS) requires extensive dialogue data, which is challenging to collect at scale. To address this, researchers have used simulated user-recommender conversations. Traditional simulation approaches often utilize a single large language model (LLM) that generates entire conversations with prior knowledge of the target items, leading to scripted and artificial dialogues. We propose a reference-free simulation framework that trains two independent LLMs, one as the user and one as the conversational recommender. These models interact in real-time without access to predetermined target items, but preference summaries and target attributes, enabling the recommender to genuinely infer user preferences through dialogue. This approach produces more realistic and diverse conversations that closely mirror authentic human-AI interactions. Our reference-free simulators match or exceed existing methods in quality, while offering a scalable solution for generating high-quality conversational recommendation data without constraining conversations to pre-defined target items. We conduct both quantitative and human evaluations to confirm the effectiveness of our reference-free approach.
A Reproducibility and Generalizability Study of Large Language Models for Query Generation
Nov 22, 2024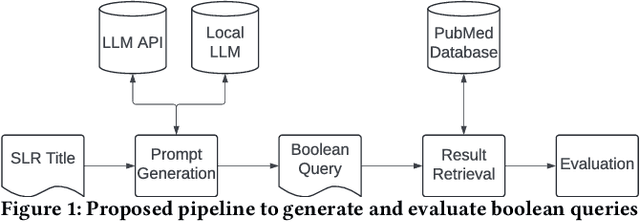
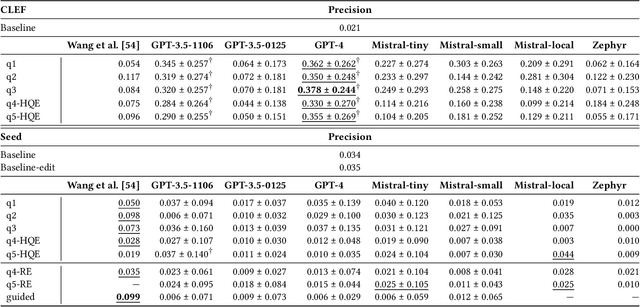

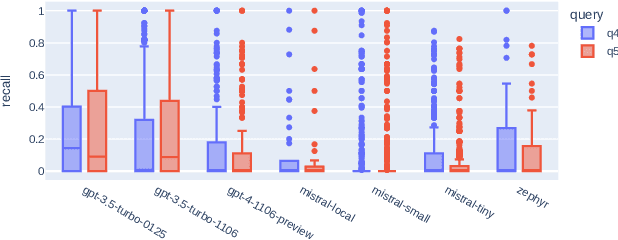
Systematic literature reviews (SLRs) are a cornerstone of academic research, yet they are often labour-intensive and time-consuming due to the detailed literature curation process. The advent of generative AI and large language models (LLMs) promises to revolutionize this process by assisting researchers in several tedious tasks, one of them being the generation of effective Boolean queries that will select the publications to consider including in a review. This paper presents an extensive study of Boolean query generation using LLMs for systematic reviews, reproducing and extending the work of Wang et al. and Alaniz et al. Our study investigates the replicability and reliability of results achieved using ChatGPT and compares its performance with open-source alternatives like Mistral and Zephyr to provide a more comprehensive analysis of LLMs for query generation. Therefore, we implemented a pipeline, which automatically creates a Boolean query for a given review topic by using a previously defined LLM, retrieves all documents for this query from the PubMed database and then evaluates the results. With this pipeline we first assess whether the results obtained using ChatGPT for query generation are reproducible and consistent. We then generalize our results by analyzing and evaluating open-source models and evaluating their efficacy in generating Boolean queries. Finally, we conduct a failure analysis to identify and discuss the limitations and shortcomings of using LLMs for Boolean query generation. This examination helps to understand the gaps and potential areas for improvement in the application of LLMs to information retrieval tasks. Our findings highlight the strengths, limitations, and potential of LLMs in the domain of information retrieval and literature review automation.
Preference Distillation for Personalized Generative Recommendation
Jul 06, 2024



Recently, researchers have investigated the capabilities of Large Language Models (LLMs) for generative recommender systems. Existing LLM-based recommender models are trained by adding user and item IDs to a discrete prompt template. However, the disconnect between IDs and natural language makes it difficult for the LLM to learn the relationship between users. To address this issue, we propose a PErsonAlized PrOmpt Distillation (PeaPOD) approach, to distill user preferences as personalized soft prompts. Considering the complexities of user preferences in the real world, we maintain a shared set of learnable prompts that are dynamically weighted based on the user's interests to construct the user-personalized prompt in a compositional manner. Experimental results on three real-world datasets demonstrate the effectiveness of our PeaPOD model on sequential recommendation, top-n recommendation, and explanation generation tasks.
Instruction Tuning With Loss Over Instructions
May 23, 2024Instruction tuning plays a crucial role in shaping the outputs of language models (LMs) to desired styles. In this work, we propose a simple yet effective method, Instruction Modelling (IM), which trains LMs by applying a loss function to the instruction and prompt part rather than solely to the output part. Through experiments across 21 diverse benchmarks, we show that, in many scenarios, IM can effectively improve the LM performance on both NLP tasks (e.g., MMLU, TruthfulQA, and HumanEval) and open-ended generation benchmarks (e.g., MT-Bench and AlpacaEval). Remarkably, in the most advantageous case, IM boosts model performance on AlpacaEval 1.0 by over 100%. We identify two key factors influencing the effectiveness of IM: (1) The ratio between instruction length and output length in the training data; and (2) The number of training examples. We observe that IM is especially beneficial when trained on datasets with lengthy instructions paired with brief outputs, or under the Superficial Alignment Hypothesis (SAH) where a small amount of training examples are used for instruction tuning. Further analysis substantiates our hypothesis that the improvement can be attributed to reduced overfitting to instruction tuning datasets. Our work provides practical guidance for instruction tuning LMs, especially in low-resource scenarios.
Do Sentence Transformers Learn Quasi-Geospatial Concepts from General Text?
Apr 05, 2024



Sentence transformers are language models designed to perform semantic search. This study investigates the capacity of sentence transformers, fine-tuned on general question-answering datasets for asymmetric semantic search, to associate descriptions of human-generated routes across Great Britain with queries often used to describe hiking experiences. We find that sentence transformers have some zero-shot capabilities to understand quasi-geospatial concepts, such as route types and difficulty, suggesting their potential utility for routing recommendation systems.
Natural Language User Profiles for Transparent and Scrutable Recommendations
Feb 08, 2024Current state-of-the-art recommender systems predominantly rely on either implicit or explicit feedback from users to suggest new items. While effective in recommending novel options, these conventional systems often use uninterpretable embeddings. This lack of transparency not only limits user understanding of why certain items are suggested but also reduces the user's ability to easily scrutinize and edit their preferences. For example, if a user has a change in interests, they would need to make significant changes to their interaction history to adjust the model's recommendations. To address these limitations, we introduce a novel method that utilizes user reviews to craft personalized, natural language profiles describing users' preferences. Through these descriptive profiles, our system provides transparent recommendations in natural language. Our evaluations show that this novel approach maintains a performance level on par with established recommender systems, but with the added benefits of transparency and user control. By enabling users to scrutinize why certain items are recommended, they can more easily verify, adjust, and have greater autonomy over their recommendations.
Lexical Entrainment for Conversational Systems
Oct 14, 2023Conversational agents have become ubiquitous in assisting with daily tasks, and are expected to possess human-like features. One such feature is lexical entrainment (LE), a phenomenon in which speakers in human-human conversations tend to naturally and subconsciously align their lexical choices with those of their interlocutors, leading to more successful and engaging conversations. As an example, if a digital assistant replies 'Your appointment for Jinling Noodle Pub is at 7 pm' to the question 'When is my reservation for Jinling Noodle Bar today?', it may feel as though the assistant is trying to correct the speaker, whereas a response of 'Your reservation for Jinling Noodle Bar is at 7 pm' would likely be perceived as more positive. This highlights the importance of LE in establishing a shared terminology for maximum clarity and reducing ambiguity in conversations. However, we demonstrate in this work that current response generation models do not adequately address this crucial humanlike phenomenon. To address this, we propose a new dataset, named MULTIWOZ-ENTR, and a measure for LE for conversational systems. Additionally, we suggest a way to explicitly integrate LE into conversational systems with two new tasks, a LE extraction task and a LE generation task. We also present two baseline approaches for the LE extraction task, which aim to detect LE expressions from dialogue contexts.
DePT: Decomposed Prompt Tuning for Parameter-Efficient Fine-tuning
Sep 11, 2023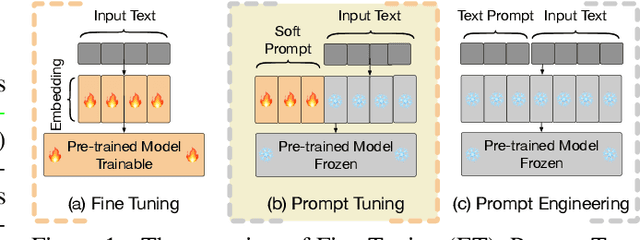
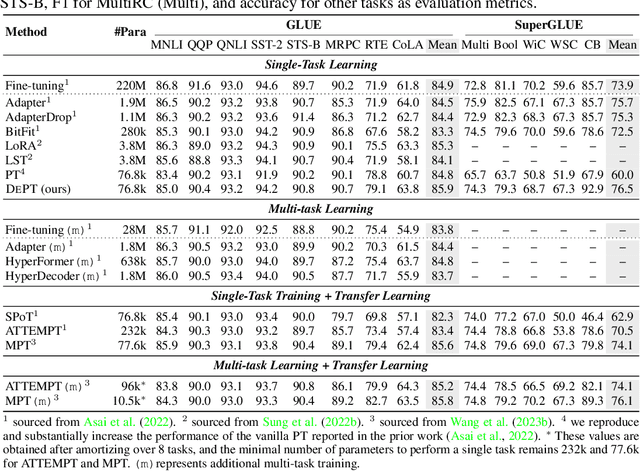
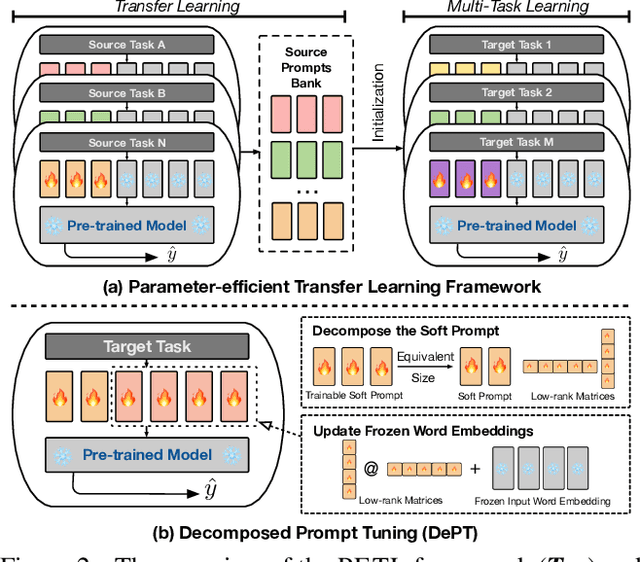
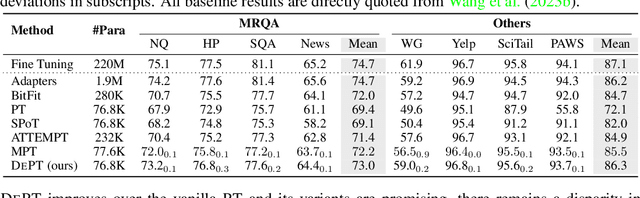
Prompt tuning (PT), where a small amount of trainable soft (continuous) prompt vectors is affixed to the input of language models (LM), has shown promising results across various tasks and models for parameter-efficient fine-tuning (PEFT). PT stands out from other PEFT approaches because it maintains competitive performance with fewer trainable parameters and does not drastically scale up its parameters as the model size expands. However, PT introduces additional soft prompt tokens, leading to longer input sequences, which significantly impacts training and inference time and memory usage due to the Transformer's quadratic complexity. Particularly concerning for Large Language Models (LLMs) that face heavy daily querying. To address this issue, we propose Decomposed Prompt Tuning (DePT), which decomposes the soft prompt into a shorter soft prompt and a pair of low-rank matrices that are then optimised with two different learning rates. This allows DePT to achieve better performance while saving over 20% memory and time costs compared to vanilla PT and its variants, without changing trainable parameter sizes. Through extensive experiments on 23 natural language processing (NLP) and vision-language (VL) tasks, we demonstrate that DePT outperforms state-of-the-art PEFT approaches, including the full fine-tuning baseline in some scenarios. Additionally, we empirically show that DEPT grows more efficient as the model size increases. Our further study reveals that DePT integrates seamlessly with parameter-efficient transfer learning in the few-shot learning setting and highlights its adaptability to various model architectures and sizes.
Application of Zone Method based Machine Learning and Physics-Informed Neural Networks in Reheating Furnaces
Aug 30, 2023Despite the high economic relevance of Foundation Industries, certain components like Reheating furnaces within their manufacturing chain are energy-intensive. Notable energy consumption reduction could be obtained by reducing the overall heating time in furnaces. Computer-integrated Machine Learning (ML) and Artificial Intelligence (AI) powered control systems in furnaces could be enablers in achieving the Net-Zero goals in Foundation Industries for sustainable manufacturing. In this work, due to the infeasibility of achieving good quality data in scenarios like reheating furnaces, classical Hottel's zone method based computational model has been used to generate data for ML and Deep Learning (DL) based model training via regression. It should be noted that the zone method provides an elegant way to model the physical phenomenon of Radiative Heat Transfer (RHT), the dominating heat transfer mechanism in high-temperature processes inside heating furnaces. Using this data, an extensive comparison among a wide range of state-of-the-art, representative ML and DL methods has been made against their temperature prediction performances in varying furnace environments. Owing to their holistic balance among inference times and model performance, DL stands out among its counterparts. To further enhance the Out-Of-Distribution (OOD) generalization capability of the trained DL models, we propose a Physics-Informed Neural Network (PINN) by incorporating prior physical knowledge using a set of novel Energy-Balance regularizers. Our setup is a generic framework, is geometry-agnostic of the 3D structure of the underlying furnace, and as such could accommodate any standard ML regression model, to serve as a Digital Twin of the underlying physical processes, for transitioning Foundation Industries towards Industry 4.0.
Unlocking the Potential of User Feedback: Leveraging Large Language Model as User Simulator to Enhance Dialogue System
Jun 16, 2023



Dialogue systems and large language models (LLMs) have gained considerable attention. However, the direct utilization of LLMs as task-oriented dialogue (TOD) models has been found to underperform compared to smaller task-specific models. Nonetheless, it is crucial to acknowledge the significant potential of LLMs and explore improved approaches for leveraging their impressive abilities. Motivated by the goal of leveraging LLMs, we propose an alternative approach called User-Guided Response Optimization (UGRO) to combine it with a smaller TOD model. This approach uses LLM as annotation-free user simulator to assess dialogue responses, combining them with smaller fine-tuned end-to-end TOD models. By utilizing the satisfaction feedback generated by LLMs, UGRO further optimizes the supervised fine-tuned TOD model. Specifically, the TOD model takes the dialogue history as input and, with the assistance of the user simulator's feedback, generates high-satisfaction responses that meet the user's requirements. Through empirical experiments on two TOD benchmarks, we validate the effectiveness of our method. The results demonstrate that our approach outperforms previous state-of-the-art (SOTA) results.