 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Scenic Route to Deception: Dark Patterns and Explainability Pitfalls in Conversational Navigation
Mar 15, 2026As pedestrian navigation increasingly experiments with Generative AI, and in particular Large Language Models, the nature of routing risks transforming from a verifiable geometric task into an opaque, persuasive dialogue. While conversational interfaces promise personalisation, they introduce risks of manipulation and misplaced trust. We categorise these risks using a 2x2 framework based on intent and origin, distinguishing between intentional manipulations (dark patterns) and unintended harms (explainability pitfalls). We propose seamful design strategies to mitigate these harms. We suggest that one robust way to operationalise trustworthy conversational navigation is through neuro-symbolic architecture, where verifiable pathfinding algorithms ground GenAI's persuasive capabilities, ensuring systems explain their limitations and incentives as clearly as they explain the route.
A Contrastive Learning Framework Empowered by Attention-based Feature Adaptation for Street-View Image Classification
Feb 18, 2026Street-view image attribute classification is a vital downstream task of image classification, enabling applications such as autonomous driving, urban analytics, and high-definition map construction. It remains computationally demanding whether training from scratch, initialising from pre-trained weights, or fine-tuning large models. Although pre-trained vision-language models such as CLIP offer rich image representations, existing adaptation or fine-tuning methods often rely on their global image embeddings, limiting their ability to capture fine-grained, localised attributes essential in complex, cluttered street scenes. To address this, we propose CLIP-MHAdapter, a variant of the current lightweight CLIP adaptation paradigm that appends a bottleneck MLP equipped with multi-head self-attention operating on patch tokens to model inter-patch dependencies. With approximately 1.4 million trainable parameters, CLIP-MHAdapter achieves superior or competitive accuracy across eight attribute classification tasks on the Global StreetScapes dataset, attaining new state-of-the-art results while maintaining low computational cost. The code is available at https://github.com/SpaceTimeLab/CLIP-MHAdapter.
CLIP the Landscape: Automated Tagging of Crowdsourced Landscape Images
Jun 13, 2025We present a CLIP-based, multi-modal, multi-label classifier for predicting geographical context tags from landscape photos in the Geograph dataset--a crowdsourced image archive spanning the British Isles, including remote regions lacking POIs and street-level imagery. Our approach addresses a Kaggle competition\footnote{https://www.kaggle.com/competitions/predict-geographic-context-from-landscape-photos} task based on a subset of Geograph's 8M images, with strict evaluation: exact match accuracy is required across 49 possible tags. We show that combining location and title embeddings with image features improves accuracy over using image embeddings alone. We release a lightweight pipeline\footnote{https://github.com/SpaceTimeLab/ClipTheLandscape} that trains on a modest laptop, using pre-trained CLIP image and text embeddings and a simple classification head. Predicted tags can support downstream tasks such as building location embedders for GeoAI applications, enriching spatial understanding in data-sparse regions.
V-RoAst: A New Dataset for Visual Road Assessment
Aug 21, 2024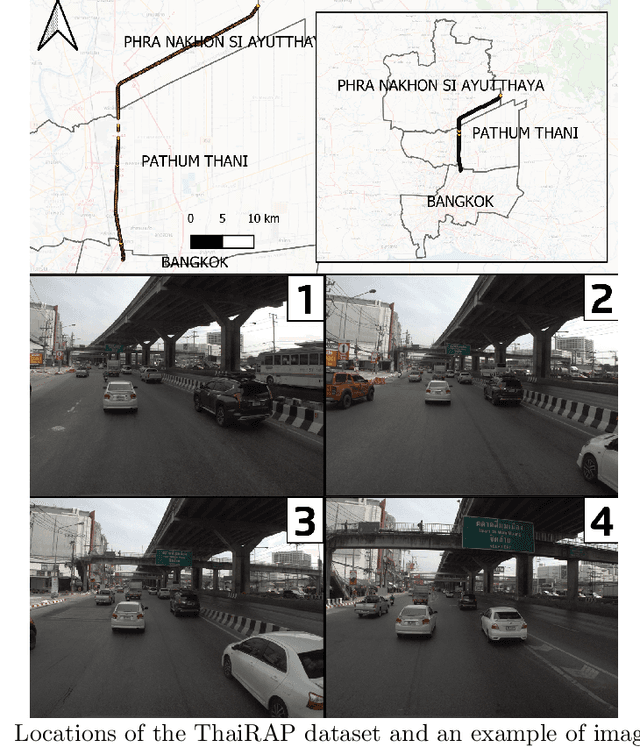
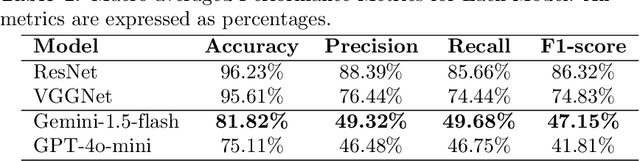
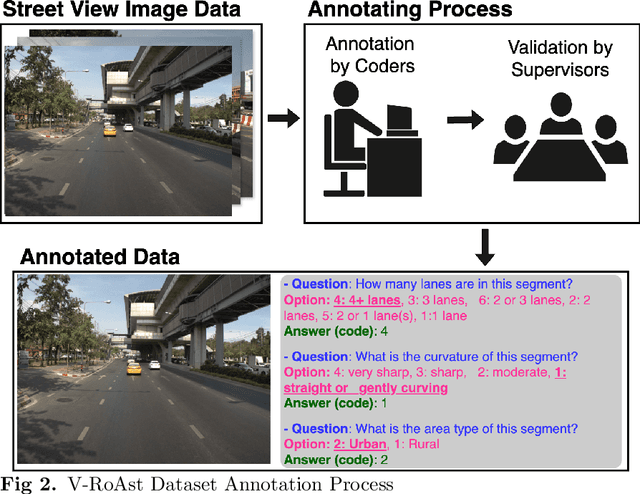
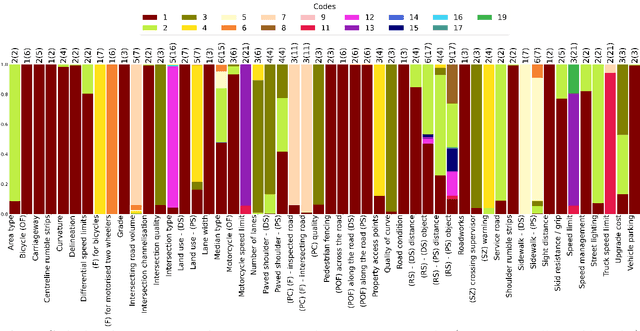
Road traffic crashes cause millions of deaths annually and have a significant economic impact, particularly in low- and middle-income countries (LMICs). This paper presents an approach using Vision Language Models (VLMs) for road safety assessment, overcoming the limitations of traditional Convolutional Neural Networks (CNNs). We introduce a new task ,V-RoAst (Visual question answering for Road Assessment), with a real-world dataset. Our approach optimizes prompt engineering and evaluates advanced VLMs, including Gemini-1.5-flash and GPT-4o-mini. The models effectively examine attributes for road assessment. Using crowdsourced imagery from Mapillary, our scalable solution influentially estimates road safety levels. In addition, this approach is designed for local stakeholders who lack resources, as it does not require training data. It offers a cost-effective and automated methods for global road safety assessments, potentially saving lives and reducing economic burdens.
SMA-Hyper: Spatiotemporal Multi-View Fusion Hypergraph Learning for Traffic Accident Prediction
Jul 24, 2024
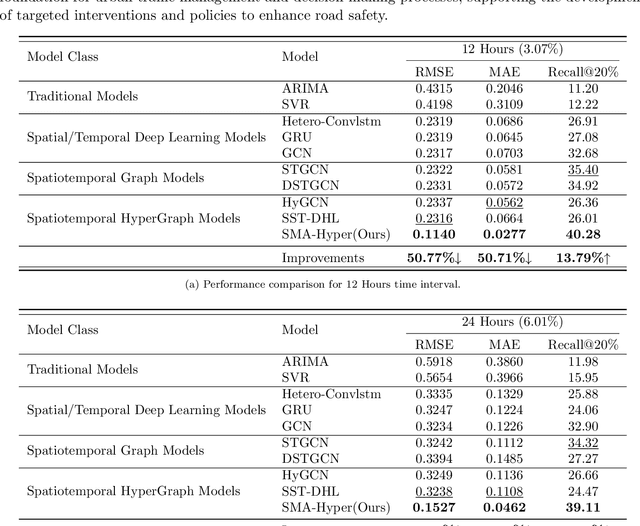

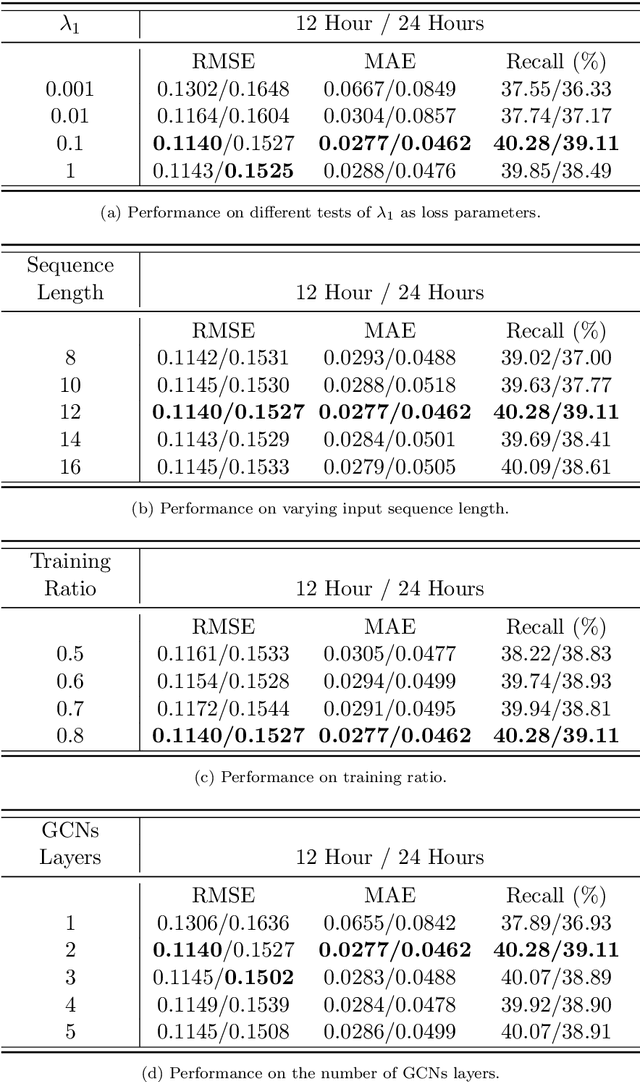
Predicting traffic accidents is the key to sustainable city management, which requires effective address of the dynamic and complex spatiotemporal characteristics of cities. Current data-driven models often struggle with data sparsity and typically overlook the integration of diverse urban data sources and the high-order dependencies within them. Additionally, they frequently rely on predefined topologies or weights, limiting their adaptability in spatiotemporal predictions. To address these issues, we introduce the Spatiotemporal Multiview Adaptive HyperGraph Learning (SMA-Hyper) model, a dynamic deep learning framework designed for traffic accident prediction. Building on previous research, this innovative model incorporates dual adaptive spatiotemporal graph learning mechanisms that enable high-order cross-regional learning through hypergraphs and dynamic adaptation to evolving urban data. It also utilises contrastive learning to enhance global and local data representations in sparse datasets and employs an advance attention mechanism to fuse multiple views of accident data and urban functional features, thereby enriching the contextual understanding of risk factors. Extensive testing on the London traffic accident dataset demonstrates that the SMA-Hyper model significantly outperforms baseline models across various temporal horizons and multistep outputs, affirming the effectiveness of its multiview fusion and adaptive learning strategies. The interpretability of the results further underscores its potential to improve urban traffic management and safety by leveraging complex spatiotemporal urban data, offering a scalable framework adaptable to diverse urban environments.
Multiple Object Detection and Tracking in Panoramic Videos for Cycling Safety Analysis
Jul 21, 2024



Panoramic cycling videos can record 360{\deg} views around the cyclists. Thus, it is essential to conduct automatic road user analysis on them using computer vision models to provide data for studies on cycling safety. However, the features of panoramic data such as severe distortions, large number of small objects and boundary continuity have brought great challenges to the existing CV models, including poor performance and evaluation methods that are no longer applicable. In addition, due to the lack of data with annotations, it is not easy to re-train the models. In response to these problems, the project proposed and implemented a three-step methodology: (1) improve the prediction performance of the pre-trained object detection models on panoramic data by projecting the original image into 4 perspective sub-images; (2) introduce supports for boundary continuity and category information into DeepSORT, a commonly used multiple object tracking model, and set an improved detection model as its detector; (3) using the tracking results, develop an application for detecting the overtaking behaviour of the surrounding vehicles. Evaluated on the panoramic cycling dataset built by the project, the proposed methodology improves the average precision of YOLO v5m6 and Faster RCNN-FPN under any input resolution setting. In addition, it raises MOTA and IDF1 of DeepSORT by 7.6\% and 9.7\% respectively. When detecting the overtakes in the test videos, it achieves the F-score of 0.88. The code is available on GitHub at github.com/cuppp1998/360_object_tracking to ensure the reproducibility and further improvements of results.
Quantifying Geospatial in the Common Crawl Corpus
Jun 07, 2024Large language models (LLMs) exhibit emerging geospatial capabilities, stemming from their pre-training on vast unlabelled text datasets that are often derived from the Common Crawl corpus. However, the geospatial content within CC remains largely unexplored, impacting our understanding of LLMs' spatial reasoning. This paper investigates the prevalence of geospatial data in recent Common Crawl releases using Gemini, a powerful language model. By analyzing a sample of documents and manually revising the results, we estimate that between 1 in 5 and 1 in 6 documents contain geospatial information such as coordinates and street addresses. Our findings provide quantitative insights into the nature and extent of geospatial data within Common Crawl, and web crawl data in general. Furthermore, we formulate questions to guide future investigations into the geospatial content of available web crawl datasets and its influence on LLMs.
CC-GPX: Extracting High-Quality Annotated Geospatial Data from Common Crawl
May 17, 2024The Common Crawl (CC) corpus is the largest open web crawl dataset containing 9.5+ petabytes of data captured since 2008. The dataset is instrumental in training large language models, and as such it has been studied for (un)desirable content, and distilled for smaller, domain-specific datasets. However, to our knowledge, no research has been dedicated to using CC as a source of annotated geospatial data. In this paper, we introduce an efficient pipeline to extract annotated user-generated tracks from GPX files found in CC, and the resulting multimodal dataset with 1,416 pairings of human-written descriptions and MultiLineString vector data. The dataset can be used to study people's outdoor activity patterns, the way people talk about their outdoor experiences, and for developing trajectory generation or track annotation models.
Do Sentence Transformers Learn Quasi-Geospatial Concepts from General Text?
Apr 05, 2024



Sentence transformers are language models designed to perform semantic search. This study investigates the capacity of sentence transformers, fine-tuned on general question-answering datasets for asymmetric semantic search, to associate descriptions of human-generated routes across Great Britain with queries often used to describe hiking experiences. We find that sentence transformers have some zero-shot capabilities to understand quasi-geospatial concepts, such as route types and difficulty, suggesting their potential utility for routing recommendation systems.
Spatiotemporal Graph Neural Networks with Uncertainty Quantification for Traffic Incident Risk Prediction
Sep 10, 2023
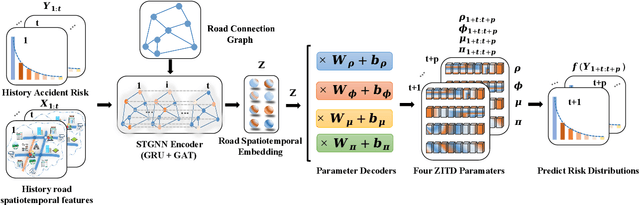

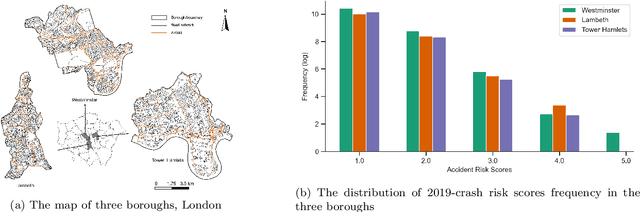
Predicting traffic incident risks at granular spatiotemporal levels is challenging. The datasets predominantly feature zero values, indicating no incidents, with sporadic high-risk values for severe incidents. Notably, a majority of current models, especially deep learning methods, focus solely on estimating risk values, overlooking the uncertainties arising from the inherently unpredictable nature of incidents. To tackle this challenge, we introduce the Spatiotemporal Zero-Inflated Tweedie Graph Neural Networks (STZITD-GNNs). Our model merges the reliability of traditional statistical models with the flexibility of graph neural networks, aiming to precisely quantify uncertainties associated with road-level traffic incident risks. This model strategically employs a compound model from the Tweedie family, as a Poisson distribution to model risk frequency and a Gamma distribution to account for incident severity. Furthermore, a zero-inflated component helps to identify the non-incident risk scenarios. As a result, the STZITD-GNNs effectively capture the dataset's skewed distribution, placing emphasis on infrequent but impactful severe incidents. Empirical tests using real-world traffic data from London, UK, demonstrate that our model excels beyond current benchmarks. The forte of STZITD-GNN resides not only in its accuracy but also in its adeptness at curtailing uncertainties, delivering robust predictions over short (7 days) and extended (14 days) timeframes.