 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransforming CCTV cameras into NO$_2$ sensors at city scale for adaptive policymaking
Dec 28, 2024



Air pollution in cities, especially NO\textsubscript{2}, is linked to numerous health problems, ranging from mortality to mental health challenges and attention deficits in children. While cities globally have initiated policies to curtail emissions, real-time monitoring remains challenging due to limited environmental sensors and their inconsistent distribution. This gap hinders the creation of adaptive urban policies that respond to the sequence of events and daily activities affecting pollution in cities. Here, we demonstrate how city CCTV cameras can act as a pseudo-NO\textsubscript{2} sensors. Using a predictive graph deep model, we utilised traffic flow from London's cameras in addition to environmental and spatial factors, generating NO\textsubscript{2} predictions from over 133 million frames. Our analysis of London's mobility patterns unveiled critical spatiotemporal connections, showing how specific traffic patterns affect NO\textsubscript{2} levels, sometimes with temporal lags of up to 6 hours. For instance, if trucks only drive at night, their effects on NO\textsubscript{2} levels are most likely to be seen in the morning when people commute. These findings cast doubt on the efficacy of some of the urban policies currently being implemented to reduce pollution. By leveraging existing camera infrastructure and our introduced methods, city planners and policymakers could cost-effectively monitor and mitigate the impact of NO\textsubscript{2} and other pollutants.
Generating floorplans for various building functionalities via latent diffusion model
Dec 09, 2024In the domain of architectural design, the foundational essence of creativity and human intelligence lies in the mastery of solving floorplans, a skill demanding distinctive expertise and years of experience. Traditionally, the architectural design process of creating floorplans often requires substantial manual labour and architectural expertise. Even when relying on parametric design approaches, the process is limited based on the designer's ability to build a complex set of parameters to iteratively explore design alternatives. As a result, these approaches hinder creativity and limit discovery of an optimal solution. Here, we present a generative latent diffusion model that learns to generate floorplans for various building types based on building footprints and design briefs. The introduced model learns from the complexity of the inter-connections between diverse building types and the mutations of architectural designs. By harnessing the power of latent diffusion models, this research surpasses conventional limitations in the design process. The model's ability to learn from diverse building types means that it cannot only replicate existing designs but also produce entirely new configurations that fuse design elements in unexpected ways. This innovation introduces a new dimension of creativity into architectural design, allowing architects, urban planners and even individuals without specialised expertise to explore uncharted territories of form and function with speed and cost-effectiveness.
FaceTouch: Detecting hand-to-face touch with supervised contrastive learning to assist in tracing infectious disease
Aug 24, 2023Through our respiratory system, many viruses and diseases frequently spread and pass from one person to another. Covid-19 served as an example of how crucial it is to track down and cut back on contacts to stop its spread. There is a clear gap in finding automatic methods that can detect hand-to-face contact in complex urban scenes or indoors. In this paper, we introduce a computer vision framework, called FaceTouch, based on deep learning. It comprises deep sub-models to detect humans and analyse their actions. FaceTouch seeks to detect hand-to-face touches in the wild, such as through video chats, bus footage, or CCTV feeds. Despite partial occlusion of faces, the introduced system learns to detect face touches from the RGB representation of a given scene by utilising the representation of the body gestures such as arm movement. This has been demonstrated to be useful in complex urban scenarios beyond simply identifying hand movement and its closeness to faces. Relying on Supervised Contrastive Learning, the introduced model is trained on our collected dataset, given the absence of other benchmark datasets. The framework shows a strong validation in unseen datasets which opens the door for potential deployment.
ImageSig: A signature transform for ultra-lightweight image recognition
May 13, 2022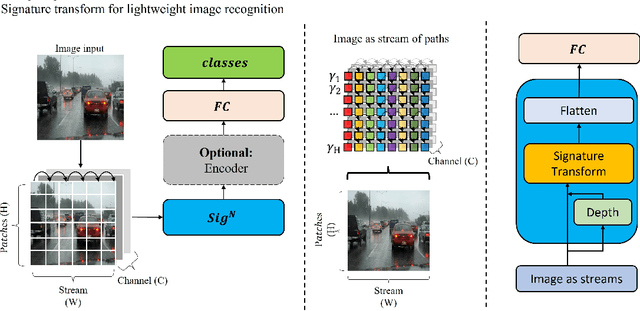



This paper introduces a new lightweight method for image recognition. ImageSig is based on computing signatures and does not require a convolutional structure or an attention-based encoder. It is striking to the authors that it achieves: a) an accuracy for 64 X 64 RGB images that exceeds many of the state-of-the-art methods and simultaneously b) requires orders of magnitude less FLOPS, power and memory footprint. The pretrained model can be as small as 44.2 KB in size. ImageSig shows unprecedented performance on hardware such as Raspberry Pi and Jetson-nano. ImageSig treats images as streams with multiple channels. These streams are parameterized by spatial directions. We contribute to the functionality of signature and rough path theory to stream-like data and vision tasks on static images beyond temporal streams. With very few parameters and small size models, the key advantage is that one could have many of these "detectors" assembled on the same chip; moreover, the feature acquisition can be performed once and shared between different models of different tasks - further accelerating the process. This contributes to energy efficiency and the advancements of embedded AI at the edge.
Re-designing cities with conditional adversarial networks
Apr 14, 2021

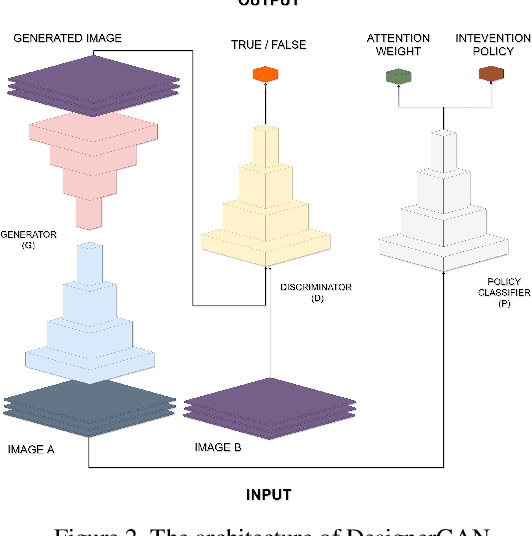

This paper introduces a conditional generative adversarial network to redesign a street-level image of urban scenes by generating 1) an urban intervention policy, 2) an attention map that localises where intervention is needed, 3) a high-resolution street-level image (1024 X 1024 or 1536 X1536) after implementing the intervention. We also introduce a new dataset that comprises aligned street-level images of before and after urban interventions from real-life scenarios that make this research possible. The introduced method has been trained on different ranges of urban interventions applied to realistic images. The trained model shows strong performance in re-modelling cities, outperforming existing methods that apply image-to-image translation in other domains that is computed in a single GPU. This research opens the door for machine intelligence to play a role in re-thinking and re-designing the different attributes of cities based on adversarial learning, going beyond the mainstream of facial landmarks manipulation or image synthesis from semantic segmentation.
CyclingNet: Detecting cycling near misses from video streams in complex urban scenes with deep learning
Jan 31, 2021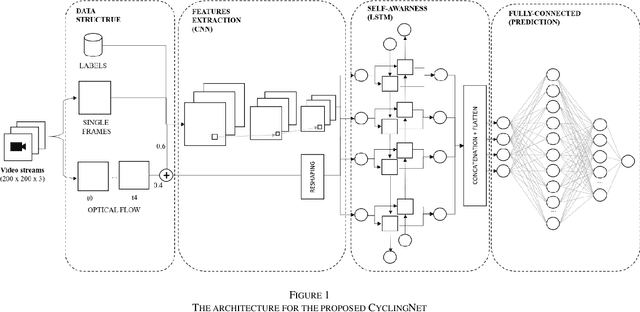



Cycling is a promising sustainable mode for commuting and leisure in cities, however, the fear of getting hit or fall reduces its wide expansion as a commuting mode. In this paper, we introduce a novel method called CyclingNet for detecting cycling near misses from video streams generated by a mounted frontal camera on a bike regardless of the camera position, the conditions of the built, the visual conditions and without any restrictions on the riding behaviour. CyclingNet is a deep computer vision model based on convolutional structure embedded with self-attention bidirectional long-short term memory (LSTM) blocks that aim to understand near misses from both sequential images of scenes and their optical flows. The model is trained on scenes of both safe rides and near misses. After 42 hours of training on a single GPU, the model shows high accuracy on the training, testing and validation sets. The model is intended to be used for generating information that can draw significant conclusions regarding cycling behaviour in cities and elsewhere, which could help planners and policy-makers to better understand the requirement of safety measures when designing infrastructure or drawing policies. As for future work, the model can be pipelined with other state-of-the-art classifiers and object detectors simultaneously to understand the causality of near misses based on factors related to interactions of road-users, the built and the natural environments.
WeatherNet: Recognising weather and visual conditions from street-level images using deep residual learning
Oct 22, 2019



Extracting information related to weather and visual conditions at a given time and space is indispensable for scene awareness, which strongly impacts our behaviours, from simply walking in a city to riding a bike, driving a car, or autonomous drive-assistance. Despite the significance of this subject, it is still not been fully addressed by the machine intelligence relying on deep learning and computer vision to detect the multi-labels of weather and visual conditions with a unified method that can be easily used for practice. What has been achieved to-date is rather sectorial models that address limited number of labels that do not cover the wide spectrum of weather and visual conditions. Nonetheless, weather and visual conditions are often addressed individually. In this paper, we introduce a novel framework to automatically extract this information from street-level images relying on deep learning and computer vision using a unified method without any pre-defined constraints in the processed images. A pipeline of four deep Convolutional Neural Network (CNN) models, so-called the WeatherNet, is trained, relying on residual learning using ResNet50 architecture, to extract various weather and visual conditions such as Dawn/dusk, day and night for time detection, and glare for lighting conditions, and clear, rainy, snowy, and foggy for weather conditions. The WeatherNet shows strong performance in extracting this information from user-defined images or video streams that can be used not limited to: autonomous vehicles and drive-assistance systems, tracking behaviours, safety-related research, or even for better understanding cities through images for policy-makers.
URBAN-i: From urban scenes to mapping slums, transport modes, and pedestrians in cities using deep learning and computer vision
Sep 10, 2018



Within the burgeoning expansion of deep learning and computer vision across the different fields of science, when it comes to urban development, deep learning and computer vision applications are still limited towards the notions of smart cities and autonomous vehicles. Indeed, a wide gap of knowledge appears when it comes to cities and urban regions in less developed countries where the chaos of informality is the dominant scheme. How can deep learning and Artificial Intelligence (AI) untangle the complexities of informality to advance urban modelling and our understanding of cities? Various questions and debates can be raised concerning the future of cities of the North and the South in the paradigm of AI and computer vision. In this paper, we introduce a new method for multipurpose realistic-dynamic urban modelling relying on deep learning and computer vision, using deep Convolutional Neural Networks (CNN), to sense and detect informality and slums in urban scenes from aerial and street view images in addition to detection of pedestrian and transport modes. The model has been trained on images of urban scenes in cities across the globe. The model shows a good validation of understanding a wide spectrum of nuances among the planned and the unplanned regions, including informal and slum areas. We attempt to advance urban modelling for better understanding the dynamics of city developments. We also aim to exemplify the significant impacts of AI in cities beyond how smart cities are discussed and perceived in the mainstream. The algorithms of the URBAN-i model are fully-coded in Python programming with the pre-trained deep learning models to be used as a tool for mapping and city modelling in the various corner of the globe, including informal settlements and slum regions.
predictSLUMS: A new model for identifying and predicting informal settlements and slums in cities from street intersections using machine learning
Aug 14, 2018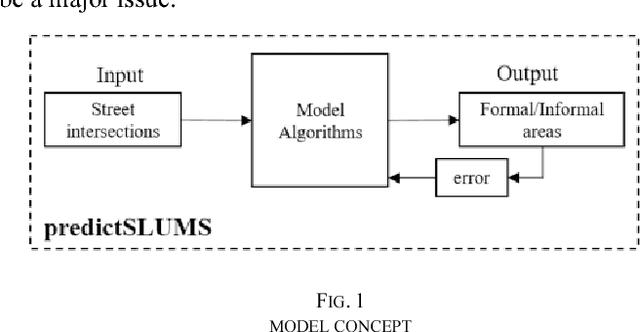
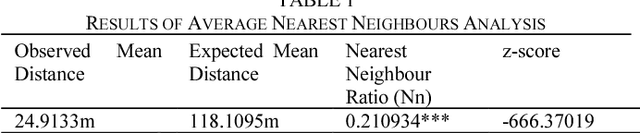


Identifying current and future informal regions within cities remains a crucial issue for policymakers and governments in developing countries. The delineation process of identifying such regions in cities requires a lot of resources. While there are various studies that identify informal settlements based on satellite image classification, relying on both supervised or unsupervised machine learning approaches, these models either require multiple input data to function or need further development with regards to precision. In this paper, we introduce a novel method for identifying and predicting informal settlements using only street intersections data, regardless of the variation of urban form, number of floors, materials used for construction or street width. With such minimal input data, we attempt to provide planners and policy-makers with a pragmatic tool that can aid in identifying informal zones in cities. The algorithm of the model is based on spatial statistics and a machine learning approach, using Multinomial Logistic Regression (MNL) and Artificial Neural Networks (ANN). The proposed model relies on defining informal settlements based on two ubiquitous characteristics that these regions tend to be filled in with smaller subdivided lots of housing relative to the formal areas within the local context, and the paucity of services and infrastructure within the boundary of these settlements that require relatively bigger lots. We applied the model in five major cities in Egypt and India that have spatial structures in which informality is present. These cities are Greater Cairo, Alexandria, Hurghada and Minya in Egypt, and Mumbai in India. The predictSLUMS model shows high validity and accuracy for identifying and predicting informality within the same city the model was trained on or in different ones of a similar context.