 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Contrastive Learning of Urban Space Representations from POI Data
Nov 09, 2024Existing methods for learning urban space representations from Point-of-Interest (POI) data face several limitations, including issues with geographical delineation, inadequate spatial information modelling, underutilisation of POI semantic attributes, and computational inefficiencies. To address these issues, we propose CaLLiPer (Contrastive Language-Location Pre-training), a novel representation learning model that directly embeds continuous urban spaces into vector representations that can capture the spatial and semantic distribution of urban environment. This model leverages a multimodal contrastive learning objective, aligning location embeddings with textual POI descriptions, thereby bypassing the need for complex training corpus construction and negative sampling. We validate CaLLiPer's effectiveness by applying it to learning urban space representations in London, UK, where it demonstrates 5-15% improvement in predictive performance for land use classification and socioeconomic mapping tasks compared to state-of-the-art methods. Visualisations of the learned representations further illustrate our model's advantages in capturing spatial variations in urban semantics with high accuracy and fine resolution. Additionally, CaLLiPer achieves reduced training time, showcasing its efficiency and scalability. This work provides a promising pathway for scalable, semantically rich urban space representation learning that can support the development of geospatial foundation models. The implementation code is available at https://github.com/xlwang233/CaLLiPer.
V-RoAst: A New Dataset for Visual Road Assessment
Aug 21, 2024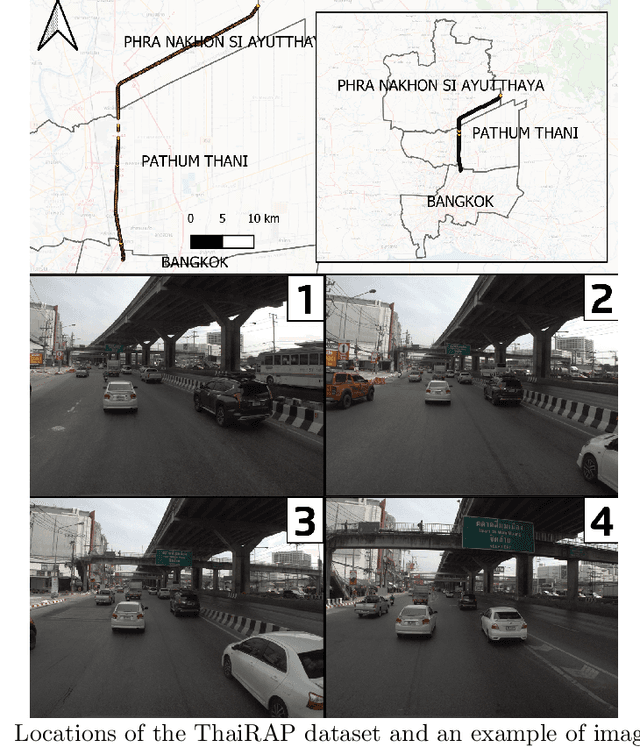
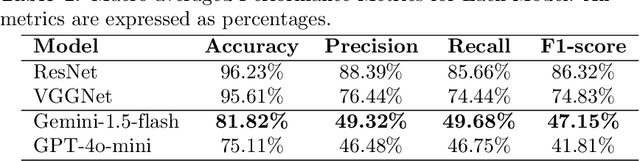
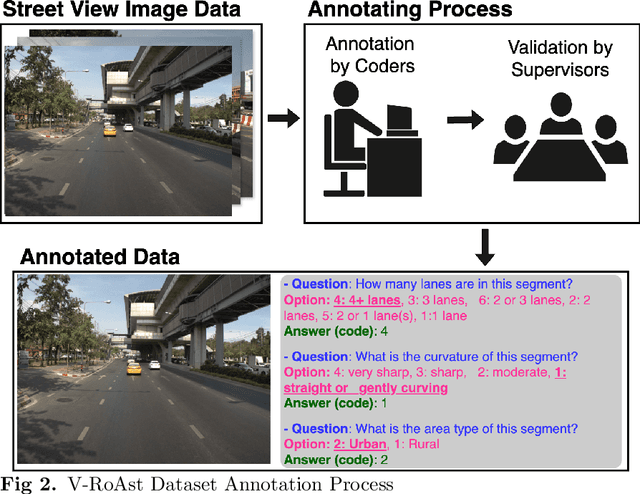
Road traffic crashes cause millions of deaths annually and have a significant economic impact, particularly in low- and middle-income countries (LMICs). This paper presents an approach using Vision Language Models (VLMs) for road safety assessment, overcoming the limitations of traditional Convolutional Neural Networks (CNNs). We introduce a new task ,V-RoAst (Visual question answering for Road Assessment), with a real-world dataset. Our approach optimizes prompt engineering and evaluates advanced VLMs, including Gemini-1.5-flash and GPT-4o-mini. The models effectively examine attributes for road assessment. Using crowdsourced imagery from Mapillary, our scalable solution influentially estimates road safety levels. In addition, this approach is designed for local stakeholders who lack resources, as it does not require training data. It offers a cost-effective and automated methods for global road safety assessments, potentially saving lives and reducing economic burdens.
Zero-shot Building Age Classification from Facade Image Using GPT-4
Apr 15, 2024

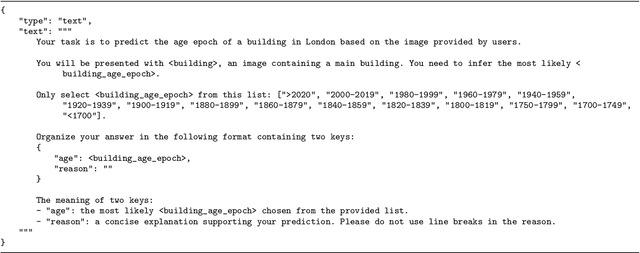

A building's age of construction is crucial for supporting many geospatial applications. Much current research focuses on estimating building age from facade images using deep learning. However, building an accurate deep learning model requires a considerable amount of labelled training data, and the trained models often have geographical constraints. Recently, large pre-trained vision language models (VLMs) such as GPT-4 Vision, which demonstrate significant generalisation capabilities, have emerged as potential training-free tools for dealing with specific vision tasks, but their applicability and reliability for building information remain unexplored. In this study, a zero-shot building age classifier for facade images is developed using prompts that include logical instructions. Taking London as a test case, we introduce a new dataset, FI-London, comprising facade images and building age epochs. Although the training-free classifier achieved a modest accuracy of 39.69%, the mean absolute error of 0.85 decades indicates that the model can predict building age epochs successfully albeit with a small bias. The ensuing discussion reveals that the classifier struggles to predict the age of very old buildings and is challenged by fine-grained predictions within 2 decades. Overall, the classifier utilising GPT-4 Vision is capable of predicting the rough age epoch of a building from a single facade image without any training.
Where Would I Go Next? Large Language Models as Human Mobility Predictors
Aug 29, 2023

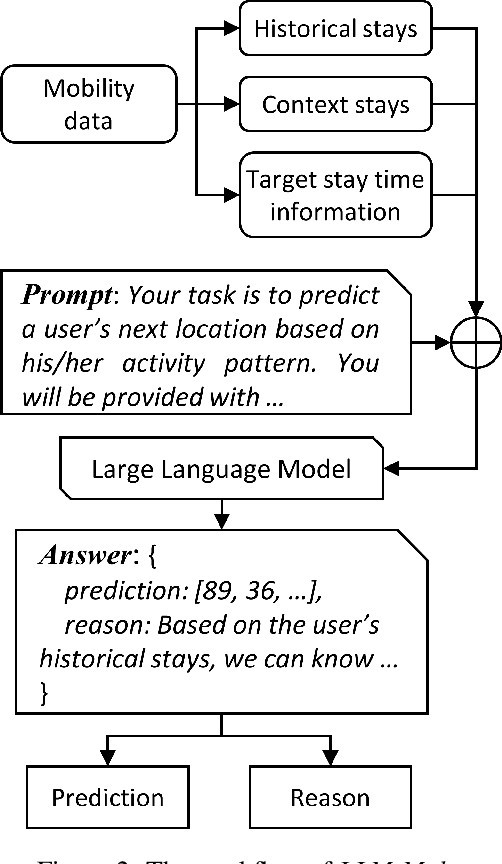

Accurate human mobility prediction underpins many important applications across a variety of domains, including epidemic modelling, transport planning, and emergency responses. Due to the sparsity of mobility data and the stochastic nature of people's daily activities, achieving precise predictions of people's locations remains a challenge. While recently developed large language models (LLMs) have demonstrated superior performance across numerous language-related tasks, their applicability to human mobility studies remains unexplored. Addressing this gap, this article delves into the potential of LLMs for human mobility prediction tasks. We introduce a novel method, LLM-Mob, which leverages the language understanding and reasoning capabilities of LLMs for analysing human mobility data. We present concepts of historical stays and context stays to capture both long-term and short-term dependencies in human movement and enable time-aware prediction by using time information of the prediction target. Additionally, we design context-inclusive prompts that enable LLMs to generate more accurate predictions. Comprehensive evaluations of our method reveal that LLM-Mob excels in providing accurate and interpretable predictions, highlighting the untapped potential of LLMs in advancing human mobility prediction techniques. We posit that our research marks a significant paradigm shift in human mobility modelling, transitioning from building complex domain-specific models to harnessing general-purpose LLMs that yield accurate predictions through language instructions. The code for this work is available at https://github.com/xlwang233/LLM-Mob.
Forecast Network-Wide Traffic States for Multiple Steps Ahead: A Deep Learning Approach Considering Dynamic Non-Local Spatial Correlation and Non-Stationary Temporal Dependency
Apr 06, 2020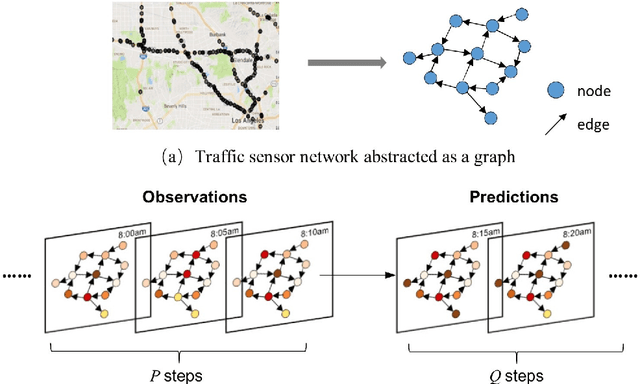

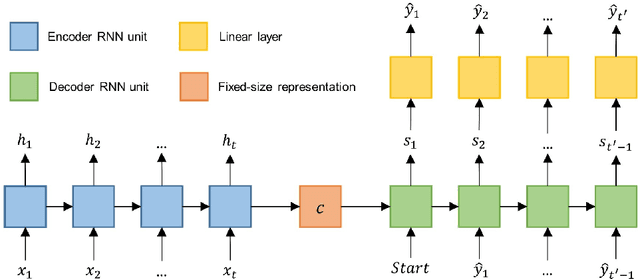
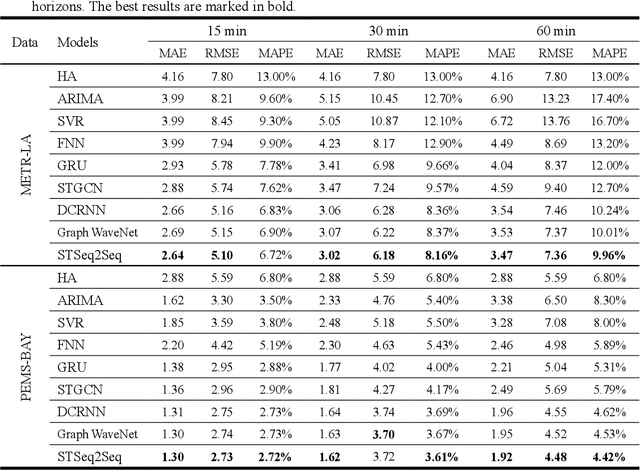
Obtaining accurate information about future traffic flows of all links in a traffic network is of great importance for traffic management and control applications. This research studies two particular problems in traffic forecasting: (1) capture the dynamic and non-local spatial correlation between traffic links and (2) model the dynamics of temporal dependency for accurate multiple steps ahead predictions. To address these issues, we propose a deep learning framework named Spatial-Temporal Sequence to Sequence model (STSeq2Seq). This model builds on sequence to sequence (seq2seq) architecture to capture temporal feature and relies on graph convolution for aggregating spatial information. Moreover, STSeq2Seq defines and constructs pattern-aware adjacency matrices (PAMs) based on pair-wise similarity of the recent traffic patterns on traffic links and integrate it into graph convolution operation. It also deploys a novel seq2sesq architecture which couples a convolutional encoder and a recurrent decoder with attention mechanism for dynamic modeling of long-range dependence between different time steps. We conduct extensive experiments using two publicly-available large-scale traffic datasets and compare STSeq2Seq with other baseline models. The numerical results demonstrate that the proposed model achieves state-of-the-art forecasting performance in terms of various error measures. The ablation study verifies the effectiveness of PAMs in capturing dynamic non-local spatial correlation and the superiority of proposed seq2seq architecture in modeling non-stationary temporal dependency for multiple steps ahead prediction. Furthermore, qualitative analysis is conducted on PAMs as well as the attention weights for model interpretation.
A Hybrid Traffic Speed Forecasting Approach Integrating Wavelet Transform and Motif-based Graph Convolutional Recurrent Neural Network
Apr 14, 2019
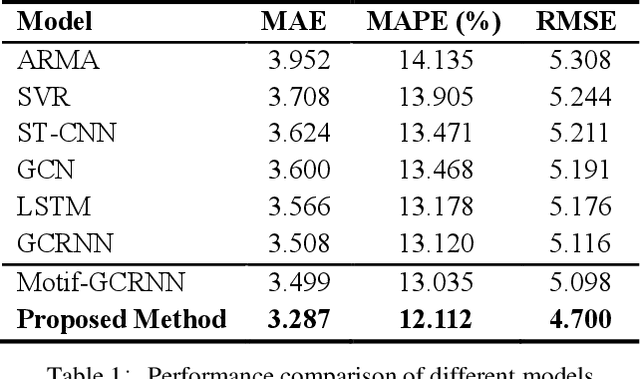
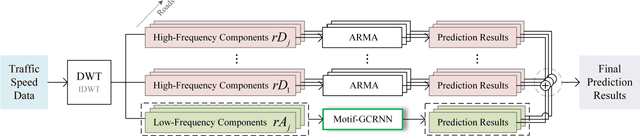
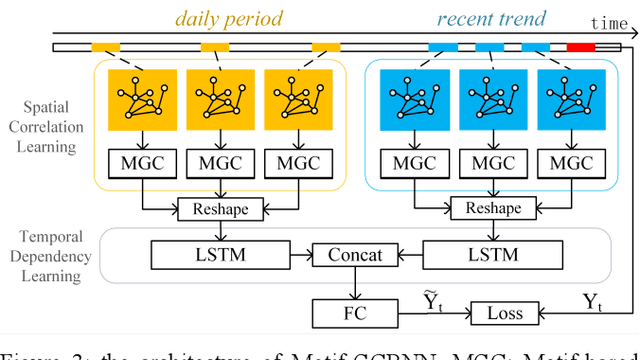
Traffic forecasting is crucial for urban traffic management and guidance. However, existing methods rarely exploit the time-frequency properties of traffic speed observations, and often neglect the propagation of traffic flows from upstream to downstream road segments. In this paper, we propose a hybrid approach that learns the spatio-temporal dependency in traffic flows and predicts short-term traffic speeds on a road network. Specifically, we employ wavelet transform to decompose raw traffic data into several components with different frequency sub-bands. A Motif-based Graph Convolutional Recurrent Neural Network (Motif-GCRNN) and Auto-Regressive Moving Average (ARMA) are used to train and predict low-frequency components and high-frequency components, respectively. In the Motif-GCRNN framework, we integrate Graph Convolutional Networks (GCNs) with local sub-graph structures - Motifs - to capture the spatial correlations among road segments, and apply Long Short-Term Memory (LSTM) to extract the short-term and periodic patterns in traffic speeds. Experiments on a traffic dataset collected in Chengdu, China, demonstrate that the proposed hybrid method outperforms six state-of-art prediction methods.