 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAM-Aug: Leveraging SAM Priors for Few-Shot Parcel Segmentation in Satellite Time Series
Jan 14, 2026Few-shot semantic segmentation of time-series remote sensing images remains a critical challenge, particularly in regions where labeled data is scarce or costly to obtain. While state-of-the-art models perform well under full supervision, their performance degrades significantly under limited labeling, limiting their real-world applicability. In this work, we propose SAM-Aug, a new annotation-efficient framework that leverages the geometry-aware segmentation capability of the Segment Anything Model (SAM) to improve few-shot land cover mapping. Our approach constructs cloud-free composite images from temporal sequences and applies SAM in a fully unsupervised manner to generate geometry-aware mask priors. These priors are then integrated into training through a proposed loss function called RegionSmoothLoss, which enforces prediction consistency within each SAM-derived region across temporal frames, effectively regularizing the model to respect semantically coherent structures. Extensive experiments on the PASTIS-R benchmark under a 5 percent labeled setting demonstrate the effectiveness and robustness of SAM-Aug. Averaged over three random seeds (42, 2025, 4090), our method achieves a mean test mIoU of 36.21 percent, outperforming the state-of-the-art baseline by +2.33 percentage points, a relative improvement of 6.89 percent. Notably, on the most favorable split (seed=42), SAM-Aug reaches a test mIoU of 40.28 percent, representing an 11.2 percent relative gain with no additional labeled data. The consistent improvement across all seeds confirms the generalization power of leveraging foundation model priors under annotation scarcity. Our results highlight that vision models like SAM can serve as useful regularizers in few-shot remote sensing learning, offering a scalable and plug-and-play solution for land cover monitoring without requiring manual annotations or model fine-tuning.
AutoGEEval: A Multimodal and Automated Framework for Geospatial Code Generation on GEE with Large Language Models
May 19, 2025Geospatial code generation is emerging as a key direction in the integration of artificial intelligence and geoscientific analysis. However, there remains a lack of standardized tools for automatic evaluation in this domain. To address this gap, we propose AutoGEEval, the first multimodal, unit-level automated evaluation framework for geospatial code generation tasks on the Google Earth Engine (GEE) platform powered by large language models (LLMs). Built upon the GEE Python API, AutoGEEval establishes a benchmark suite (AutoGEEval-Bench) comprising 1325 test cases that span 26 GEE data types. The framework integrates both question generation and answer verification components to enable an end-to-end automated evaluation pipeline-from function invocation to execution validation. AutoGEEval supports multidimensional quantitative analysis of model outputs in terms of accuracy, resource consumption, execution efficiency, and error types. We evaluate 18 state-of-the-art LLMs-including general-purpose, reasoning-augmented, code-centric, and geoscience-specialized models-revealing their performance characteristics and potential optimization pathways in GEE code generation. This work provides a unified protocol and foundational resource for the development and assessment of geospatial code generation models, advancing the frontier of automated natural language to domain-specific code translation.
GEE-OPs: An Operator Knowledge Base for Geospatial Code Generation on the Google Earth Engine Platform Powered by Large Language Models
Dec 07, 2024As the scale and complexity of spatiotemporal data continue to grow rapidly, the use of geospatial modeling on the Google Earth Engine (GEE) platform presents dual challenges: improving the coding efficiency of domain experts and enhancing the coding capabilities of interdisciplinary users. To address these challenges and improve the performance of large language models (LLMs) in geospatial code generation tasks, we propose a framework for building a geospatial operator knowledge base tailored to the GEE JavaScript API. This framework consists of an operator syntax knowledge table, an operator relationship frequency table, an operator frequent pattern knowledge table, and an operator relationship chain knowledge table. By leveraging Abstract Syntax Tree (AST) techniques and frequent itemset mining, we systematically extract operator knowledge from 185,236 real GEE scripts and syntax documentation, forming a structured knowledge base. Experimental results demonstrate that the framework achieves over 90% accuracy, recall, and F1 score in operator knowledge extraction. When integrated with the Retrieval-Augmented Generation (RAG) strategy for LLM-based geospatial code generation tasks, the knowledge base improves performance by 20-30%. Ablation studies further quantify the necessity of each knowledge table in the knowledge base construction. This work provides robust support for the advancement and application of geospatial code modeling techniques, offering an innovative approach to constructing domain-specific knowledge bases that enhance the code generation capabilities of LLMs, and fostering the deeper integration of generative AI technologies within the field of geoinformatics.
Chain-of-Programming (CoP) : Empowering Large Language Models for Geospatial Code Generation
Nov 16, 2024



With the rapid growth of interdisciplinary demands for geospatial modeling and the rise of large language models (LLMs), geospatial code generation technology has seen significant advancements. However, existing LLMs often face challenges in the geospatial code generation process due to incomplete or unclear user requirements and insufficient knowledge of specific platform syntax rules, leading to the generation of non-executable code, a phenomenon known as "code hallucination." To address this issue, this paper proposes a Chain of Programming (CoP) framework, which decomposes the code generation process into five steps: requirement analysis, algorithm design, code implementation, code debugging, and code annotation. The framework incorporates a shared information pool, knowledge base retrieval, and user feedback mechanisms, forming an end-to-end code generation flow from requirements to code without the need for model fine-tuning. Based on a geospatial problem classification framework and evaluation benchmarks, the CoP strategy significantly improves the logical clarity, syntactical correctness, and executability of the generated code, with improvements ranging from 3.0% to 48.8%. Comparative and ablation experiments further validate the superiority of the CoP strategy over other optimization approaches and confirm the rationality and necessity of its key components. Through case studies on building data visualization and fire data analysis, this paper demonstrates the application and effectiveness of CoP in various geospatial scenarios. The CoP framework offers a systematic, step-by-step approach to LLM-based geospatial code generation tasks, significantly enhancing code generation performance in geospatial tasks and providing valuable insights for code generation in other vertical domains.
Geo-FuB: A Method for Constructing an Operator-Function Knowledge Base for Geospatial Code Generation Tasks Using Large Language Models
Oct 28, 2024



The rise of spatiotemporal data and the need for efficient geospatial modeling have spurred interest in automating these tasks with large language models (LLMs). However, general LLMs often generate errors in geospatial code due to a lack of domain-specific knowledge on functions and operators. To address this, a retrieval-augmented generation (RAG) approach, utilizing an external knowledge base of geospatial functions and operators, is proposed. This study introduces a framework to construct such a knowledge base, leveraging geospatial script semantics. The framework includes: Function Semantic Framework Construction (Geo-FuSE), Frequent Operator Combination Statistics (Geo-FuST), and Semantic Mapping (Geo-FuM). Techniques like Chain-of-Thought, TF-IDF, and the APRIORI algorithm are utilized to derive and align geospatial functions. An example knowledge base, Geo-FuB, built from 154,075 Google Earth Engine scripts, is available on GitHub. Evaluation metrics show a high accuracy, reaching 88.89% overall, with structural and semantic accuracies of 92.03% and 86.79% respectively. Geo-FuB's potential to optimize geospatial code generation through the RAG and fine-tuning paradigms is highlighted.
GeoCode-GPT: A Large Language Model for Geospatial Code Generation Tasks
Oct 23, 2024



The increasing demand for spatiotemporal data and modeling tasks in geosciences has made geospatial code generation technology a critical factor in enhancing productivity. Although large language models (LLMs) have demonstrated potential in code generation tasks, they often encounter issues such as refusal to code or hallucination in geospatial code generation due to a lack of domain-specific knowledge and code corpora. To address these challenges, this paper presents and open-sources the GeoCode-PT and GeoCode-SFT corpora, along with the GeoCode-Eval evaluation dataset. Additionally, by leveraging QLoRA and LoRA for pretraining and fine-tuning, we introduce GeoCode-GPT-7B, the first LLM focused on geospatial code generation, fine-tuned from Code Llama-7B. Furthermore, we establish a comprehensive geospatial code evaluation framework, incorporating option matching, expert validation, and prompt engineering scoring for LLMs, and systematically evaluate GeoCode-GPT-7B using the GeoCode-Eval dataset. Experimental results show that GeoCode-GPT outperforms other models in multiple-choice accuracy by 9.1% to 32.1%, in code summarization ability by 1.7% to 25.4%, and in code generation capability by 1.2% to 25.1%. This paper provides a solution and empirical validation for enhancing LLMs' performance in geospatial code generation, extends the boundaries of domain-specific model applications, and offers valuable insights into unlocking their potential in geospatial code generation.
Research on Foundation Model for Spatial Data Intelligence: China's 2024 White Paper on Strategic Development of Spatial Data Intelligence
May 30, 2024This report focuses on spatial data intelligent large models, delving into the principles, methods, and cutting-edge applications of these models. It provides an in-depth discussion on the definition, development history, current status, and trends of spatial data intelligent large models, as well as the challenges they face. The report systematically elucidates the key technologies of spatial data intelligent large models and their applications in urban environments, aerospace remote sensing, geography, transportation, and other scenarios. Additionally, it summarizes the latest application cases of spatial data intelligent large models in themes such as urban development, multimodal systems, remote sensing, smart transportation, and resource environments. Finally, the report concludes with an overview and outlook on the development prospects of spatial data intelligent large models.
Interpreting the Curse of Dimensionality from Distance Concentration and Manifold Effect
Jan 07, 2024The characteristics of data like distribution and heterogeneity, become more complex and counterintuitive as the dimensionality increases. This phenomenon is known as curse of dimensionality, where common patterns and relationships (e.g., internal and boundary pattern) that hold in low-dimensional space may be invalid in higher-dimensional space. It leads to a decreasing performance for the regression, classification or clustering models or algorithms. Curse of dimensionality can be attributed to many causes. In this paper, we first summarize five challenges associated with manipulating high-dimensional data, and explains the potential causes for the failure of regression, classification or clustering tasks. Subsequently, we delve into two major causes of the curse of dimensionality, distance concentration and manifold effect, by performing theoretical and empirical analyses. The results demonstrate that nearest neighbor search (NNS) using three typical distance measurements, Minkowski distance, Chebyshev distance, and cosine distance, becomes meaningless as the dimensionality increases. Meanwhile, the data incorporates more redundant features, and the variance contribution of principal component analysis (PCA) is skewed towards a few dimensions. By interpreting the causes of the curse of dimensionality, we can better understand the limitations of current models and algorithms, and drive to improve the performance of data analysis and machine learning tasks in high-dimensional space.
Scalable manifold learning by uniform landmark sampling and constrained locally linear embedding
Jan 05, 2024As a pivotal approach in machine learning and data science, manifold learning aims to uncover the intrinsic low-dimensional structure within complex nonlinear manifolds in high-dimensional space. By exploiting the manifold hypothesis, various techniques for nonlinear dimension reduction have been developed to facilitate visualization, classification, clustering, and gaining key insights. Although existing manifold learning methods have achieved remarkable successes, they still suffer from extensive distortions incurred in the global structure, which hinders the understanding of underlying patterns. Scalability issues also limit their applicability for handling large-scale data. Here, we propose a scalable manifold learning (scML) method that can manipulate large-scale and high-dimensional data in an efficient manner. It starts by seeking a set of landmarks to construct the low-dimensional skeleton of the entire data, and then incorporates the non-landmarks into the learned space based on the constrained locally linear embedding (CLLE). We empirically validated the effectiveness of scML on synthetic datasets and real-world benchmarks of different types, and applied it to analyze the single-cell transcriptomics and detect anomalies in electrocardiogram (ECG) signals. scML scales well with increasing data sizes and embedding dimensions, and exhibits promising performance in preserving the global structure. The experiments demonstrate notable robustness in embedding quality as the sample rate decreases.
MeanCut: A Greedy-Optimized Graph Clustering via Path-based Similarity and Degree Descent Criterion
Dec 07, 2023
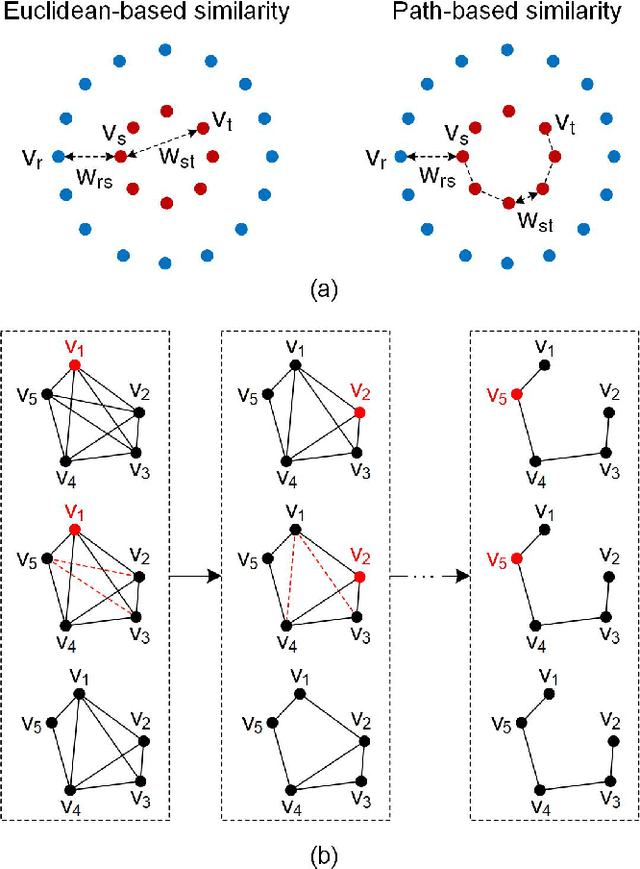
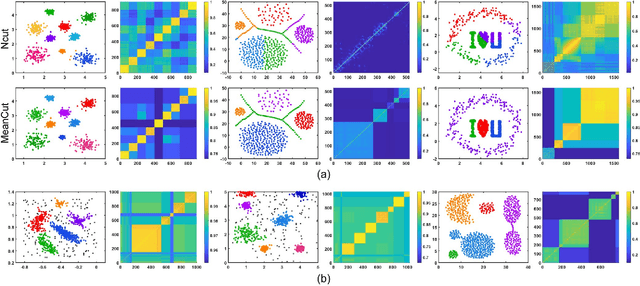
As the most typical graph clustering method, spectral clustering is popular and attractive due to the remarkable performance, easy implementation, and strong adaptability. Classical spectral clustering measures the edge weights of graph using pairwise Euclidean-based metric, and solves the optimal graph partition by relaxing the constraints of indicator matrix and performing Laplacian decomposition. However, Euclidean-based similarity might cause skew graph cuts when handling non-spherical data distributions, and the relaxation strategy introduces information loss. Meanwhile, spectral clustering requires specifying the number of clusters, which is hard to determine without enough prior knowledge. In this work, we leverage the path-based similarity to enhance intra-cluster associations, and propose MeanCut as the objective function and greedily optimize it in degree descending order for a nondestructive graph partition. This algorithm enables the identification of arbitrary shaped clusters and is robust to noise. To reduce the computational complexity of similarity calculation, we transform optimal path search into generating the maximum spanning tree (MST), and develop a fast MST (FastMST) algorithm to further improve its time-efficiency. Moreover, we define a density gradient factor (DGF) for separating the weakly connected clusters. The validity of our algorithm is demonstrated by testifying on real-world benchmarks and application of face recognition. The source code of MeanCut is available at https://github.com/ZPGuiGroupWhu/MeanCut-Clustering.