 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable manifold learning by uniform landmark sampling and constrained locally linear embedding
Jan 05, 2024As a pivotal approach in machine learning and data science, manifold learning aims to uncover the intrinsic low-dimensional structure within complex nonlinear manifolds in high-dimensional space. By exploiting the manifold hypothesis, various techniques for nonlinear dimension reduction have been developed to facilitate visualization, classification, clustering, and gaining key insights. Although existing manifold learning methods have achieved remarkable successes, they still suffer from extensive distortions incurred in the global structure, which hinders the understanding of underlying patterns. Scalability issues also limit their applicability for handling large-scale data. Here, we propose a scalable manifold learning (scML) method that can manipulate large-scale and high-dimensional data in an efficient manner. It starts by seeking a set of landmarks to construct the low-dimensional skeleton of the entire data, and then incorporates the non-landmarks into the learned space based on the constrained locally linear embedding (CLLE). We empirically validated the effectiveness of scML on synthetic datasets and real-world benchmarks of different types, and applied it to analyze the single-cell transcriptomics and detect anomalies in electrocardiogram (ECG) signals. scML scales well with increasing data sizes and embedding dimensions, and exhibits promising performance in preserving the global structure. The experiments demonstrate notable robustness in embedding quality as the sample rate decreases.
Uncertainty-Aware Multi-View Visual Semantic Embedding
Sep 15, 2023
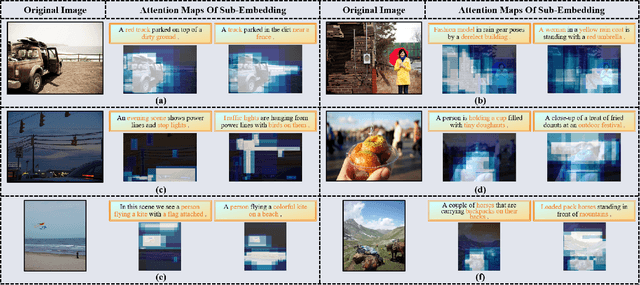
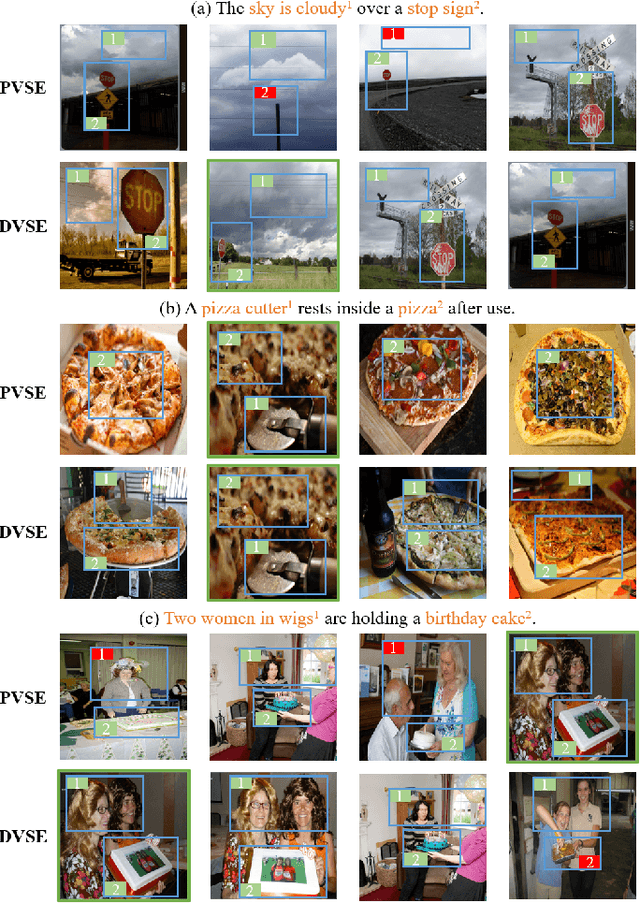
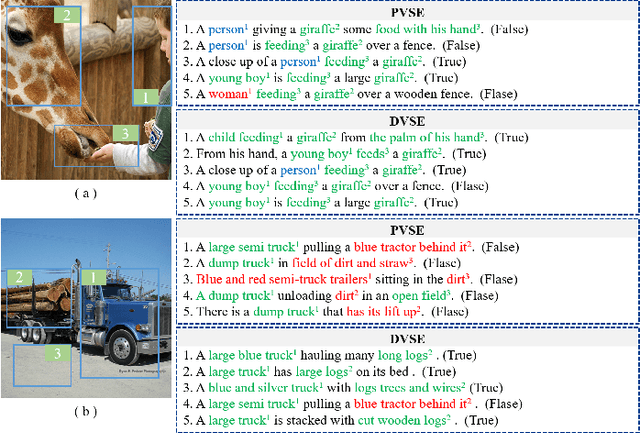
The key challenge in image-text retrieval is effectively leveraging semantic information to measure the similarity between vision and language data. However, using instance-level binary labels, where each image is paired with a single text, fails to capture multiple correspondences between different semantic units, leading to uncertainty in multi-modal semantic understanding. Although recent research has captured fine-grained information through more complex model structures or pre-training techniques, few studies have directly modeled uncertainty of correspondence to fully exploit binary labels. To address this issue, we propose an Uncertainty-Aware Multi-View Visual Semantic Embedding (UAMVSE)} framework that decomposes the overall image-text matching into multiple view-text matchings. Our framework introduce an uncertainty-aware loss function (UALoss) to compute the weighting of each view-text loss by adaptively modeling the uncertainty in each view-text correspondence. Different weightings guide the model to focus on different semantic information, enhancing the model's ability to comprehend the correspondence of images and texts. We also design an optimized image-text matching strategy by normalizing the similarity matrix to improve model performance. Experimental results on the Flicker30k and MS-COCO datasets demonstrate that UAMVSE outperforms state-of-the-art models.