 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDivide, Conquer and Unite: Hierarchical Style-Recalibrated Prototype Alignment for Federated Medical Image Segmentation
Nov 14, 2025Federated learning enables multiple medical institutions to train a global model without sharing data, yet feature heterogeneity from diverse scanners or protocols remains a major challenge. Many existing works attempt to address this issue by leveraging model representations (e.g., mean feature vectors) to correct local training; however, they often face two key limitations: 1) Incomplete Contextual Representation Learning: Current approaches primarily focus on final-layer features, overlooking critical multi-level cues and thus diluting essential context for accurate segmentation. 2) Layerwise Style Bias Accumulation: Although utilizing representations can partially align global features, these methods neglect domain-specific biases within intermediate layers, allowing style discrepancies to build up and reduce model robustness. To address these challenges, we propose FedBCS to bridge feature representation gaps via domain-invariant contextual prototypes alignment. Specifically, we introduce a frequency-domain adaptive style recalibration into prototype construction that not only decouples content-style representations but also learns optimal style parameters, enabling more robust domain-invariant prototypes. Furthermore, we design a context-aware dual-level prototype alignment method that extracts domain-invariant prototypes from different layers of both encoder and decoder and fuses them with contextual information for finer-grained representation alignment. Extensive experiments on two public datasets demonstrate that our method exhibits remarkable performance.
Enhancing Dialogue State Tracking Models through LLM-backed User-Agents Simulation
May 17, 2024Dialogue State Tracking (DST) is designed to monitor the evolving dialogue state in the conversations and plays a pivotal role in developing task-oriented dialogue systems. However, obtaining the annotated data for the DST task is usually a costly endeavor. In this paper, we focus on employing LLMs to generate dialogue data to reduce dialogue collection and annotation costs. Specifically, GPT-4 is used to simulate the user and agent interaction, generating thousands of dialogues annotated with DST labels. Then a two-stage fine-tuning on LLaMA 2 is performed on the generated data and the real data for the DST prediction. Experimental results on two public DST benchmarks show that with the generated dialogue data, our model performs better than the baseline trained solely on real data. In addition, our approach is also capable of adapting to the dynamic demands in real-world scenarios, generating dialogues in new domains swiftly. After replacing dialogue segments in any domain with the corresponding generated ones, the model achieves comparable performance to the model trained on real data.
Uncertainty-Aware Multi-View Visual Semantic Embedding
Sep 15, 2023
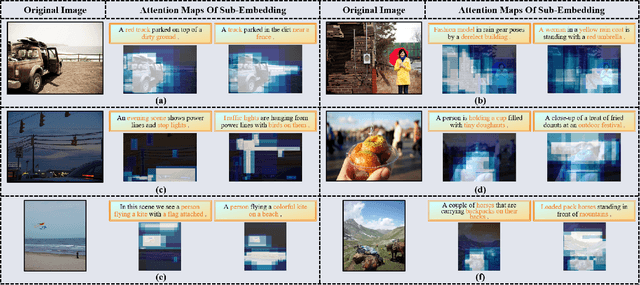
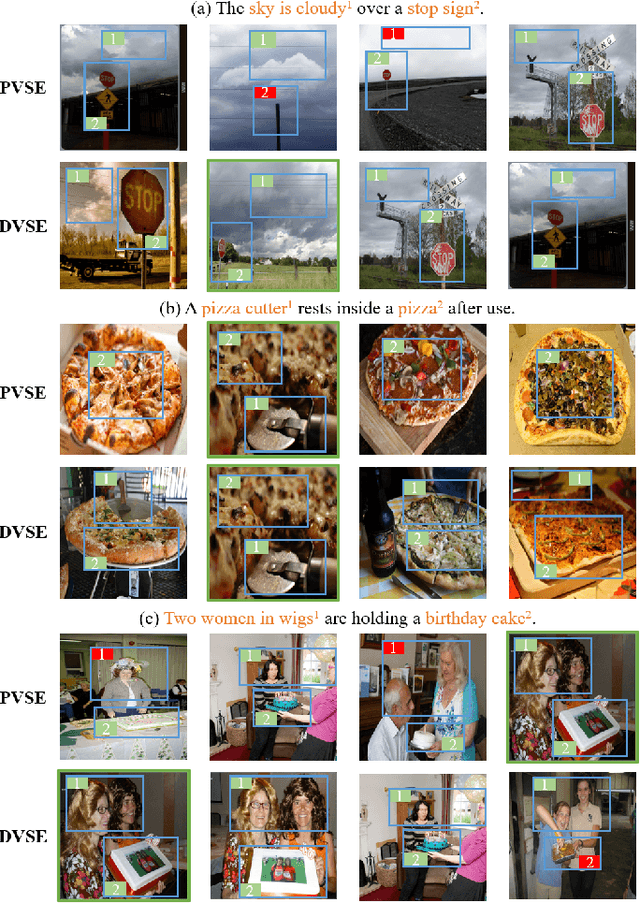
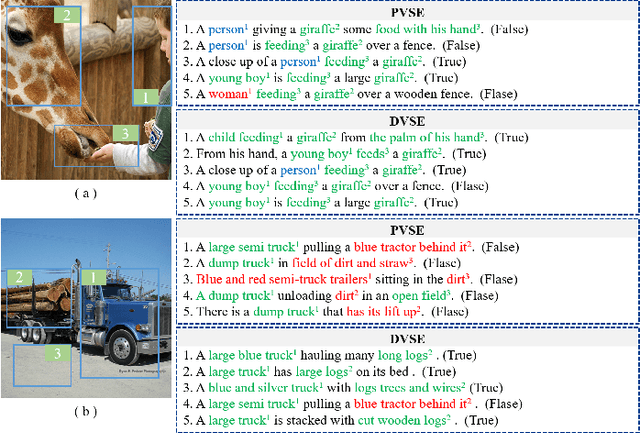
The key challenge in image-text retrieval is effectively leveraging semantic information to measure the similarity between vision and language data. However, using instance-level binary labels, where each image is paired with a single text, fails to capture multiple correspondences between different semantic units, leading to uncertainty in multi-modal semantic understanding. Although recent research has captured fine-grained information through more complex model structures or pre-training techniques, few studies have directly modeled uncertainty of correspondence to fully exploit binary labels. To address this issue, we propose an Uncertainty-Aware Multi-View Visual Semantic Embedding (UAMVSE)} framework that decomposes the overall image-text matching into multiple view-text matchings. Our framework introduce an uncertainty-aware loss function (UALoss) to compute the weighting of each view-text loss by adaptively modeling the uncertainty in each view-text correspondence. Different weightings guide the model to focus on different semantic information, enhancing the model's ability to comprehend the correspondence of images and texts. We also design an optimized image-text matching strategy by normalizing the similarity matrix to improve model performance. Experimental results on the Flicker30k and MS-COCO datasets demonstrate that UAMVSE outperforms state-of-the-art models.
Asymmetric Co-Training with Explainable Cell Graph Ensembling for Histopathological Image Classification
Aug 24, 2023



Convolutional neural networks excel in histopathological image classification, yet their pixel-level focus hampers explainability. Conversely, emerging graph convolutional networks spotlight cell-level features and medical implications. However, limited by their shallowness and suboptimal use of high-dimensional pixel data, GCNs underperform in multi-class histopathological image classification. To make full use of pixel-level and cell-level features dynamically, we propose an asymmetric co-training framework combining a deep graph convolutional network and a convolutional neural network for multi-class histopathological image classification. To improve the explainability of the entire framework by embedding morphological and topological distribution of cells, we build a 14-layer deep graph convolutional network to handle cell graph data. For the further utilization and dynamic interactions between pixel-level and cell-level information, we also design a co-training strategy to integrate the two asymmetric branches. Notably, we collect a private clinically acquired dataset termed LUAD7C, including seven subtypes of lung adenocarcinoma, which is rare and more challenging. We evaluated our approach on the private LUAD7C and public colorectal cancer datasets, showcasing its superior performance, explainability, and generalizability in multi-class histopathological image classification.