 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrozen LVLMs for Micro-Video Recommendation: A Systematic Study of Feature Extraction and Fusion
Dec 26, 2025Frozen Large Video Language Models (LVLMs) are increasingly employed in micro-video recommendation due to their strong multimodal understanding. However, their integration lacks systematic empirical evaluation: practitioners typically deploy LVLMs as fixed black-box feature extractors without systematically comparing alternative representation strategies. To address this gap, we present the first systematic empirical study along two key design dimensions: (i) integration strategies with ID embeddings, specifically replacement versus fusion, and (ii) feature extraction paradigms, comparing LVLM-generated captions with intermediate decoder hidden states. Extensive experiments on representative LVLMs reveal three key principles: (1) intermediate hidden states consistently outperform caption-based representations, as natural-language summarization inevitably discards fine-grained visual semantics crucial for recommendation; (2) ID embeddings capture irreplaceable collaborative signals, rendering fusion strictly superior to replacement; and (3) the effectiveness of intermediate decoder features varies significantly across layers. Guided by these insights, we propose the Dual Feature Fusion (DFF) Framework, a lightweight and plug-and-play approach that adaptively fuses multi-layer representations from frozen LVLMs with item ID embeddings. DFF achieves state-of-the-art performance on two real-world micro-video recommendation benchmarks, consistently outperforming strong baselines and providing a principled approach to integrating off-the-shelf large vision-language models into micro-video recommender systems.
Uncertainty-Aware Multi-View Visual Semantic Embedding
Sep 15, 2023
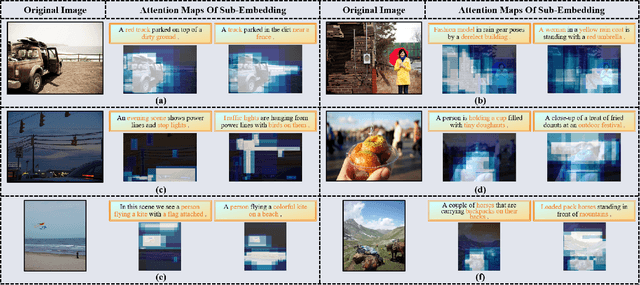
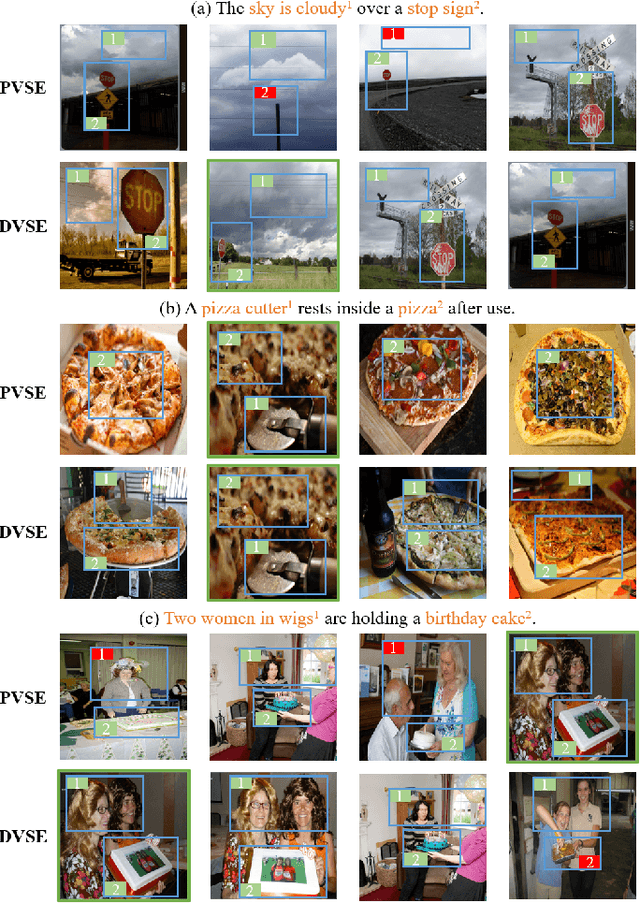
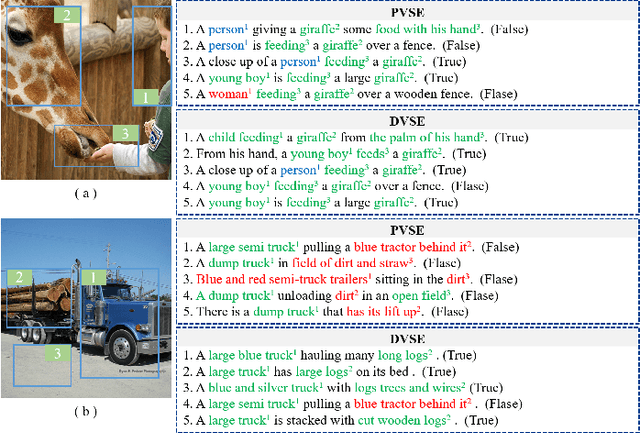
The key challenge in image-text retrieval is effectively leveraging semantic information to measure the similarity between vision and language data. However, using instance-level binary labels, where each image is paired with a single text, fails to capture multiple correspondences between different semantic units, leading to uncertainty in multi-modal semantic understanding. Although recent research has captured fine-grained information through more complex model structures or pre-training techniques, few studies have directly modeled uncertainty of correspondence to fully exploit binary labels. To address this issue, we propose an Uncertainty-Aware Multi-View Visual Semantic Embedding (UAMVSE)} framework that decomposes the overall image-text matching into multiple view-text matchings. Our framework introduce an uncertainty-aware loss function (UALoss) to compute the weighting of each view-text loss by adaptively modeling the uncertainty in each view-text correspondence. Different weightings guide the model to focus on different semantic information, enhancing the model's ability to comprehend the correspondence of images and texts. We also design an optimized image-text matching strategy by normalizing the similarity matrix to improve model performance. Experimental results on the Flicker30k and MS-COCO datasets demonstrate that UAMVSE outperforms state-of-the-art models.
LUT-GCE: Lookup Table Global Curve Estimation for Fast Low-light Image Enhancement
Jun 30, 2023



We present an effective and efficient approach for low-light image enhancement, named Lookup Table Global Curve Estimation (LUT-GCE). In contrast to existing curve-based methods with pixel-wise adjustment, we propose to estimate a global curve for the entire image that allows corrections for both under- and over-exposure. Specifically, we develop a novel cubic curve formulation for light enhancement, which enables an image-adaptive and pixel-independent curve for the range adjustment of an image. We then propose a global curve estimation network (GCENet), a very light network with only 25.4k parameters. To further speed up the inference speed, a lookup table method is employed for fast retrieval. In addition, a novel histogram smoothness loss is designed to enable zero-shot learning, which is able to improve the contrast of the image and recover clearer details. Quantitative and qualitative results demonstrate the effectiveness of the proposed approach. Furthermore, our approach outperforms the state of the art in terms of inference speed, especially on high-definition images (e.g., 1080p and 4k).