 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGEE-OPs: An Operator Knowledge Base for Geospatial Code Generation on the Google Earth Engine Platform Powered by Large Language Models
Dec 07, 2024As the scale and complexity of spatiotemporal data continue to grow rapidly, the use of geospatial modeling on the Google Earth Engine (GEE) platform presents dual challenges: improving the coding efficiency of domain experts and enhancing the coding capabilities of interdisciplinary users. To address these challenges and improve the performance of large language models (LLMs) in geospatial code generation tasks, we propose a framework for building a geospatial operator knowledge base tailored to the GEE JavaScript API. This framework consists of an operator syntax knowledge table, an operator relationship frequency table, an operator frequent pattern knowledge table, and an operator relationship chain knowledge table. By leveraging Abstract Syntax Tree (AST) techniques and frequent itemset mining, we systematically extract operator knowledge from 185,236 real GEE scripts and syntax documentation, forming a structured knowledge base. Experimental results demonstrate that the framework achieves over 90% accuracy, recall, and F1 score in operator knowledge extraction. When integrated with the Retrieval-Augmented Generation (RAG) strategy for LLM-based geospatial code generation tasks, the knowledge base improves performance by 20-30%. Ablation studies further quantify the necessity of each knowledge table in the knowledge base construction. This work provides robust support for the advancement and application of geospatial code modeling techniques, offering an innovative approach to constructing domain-specific knowledge bases that enhance the code generation capabilities of LLMs, and fostering the deeper integration of generative AI technologies within the field of geoinformatics.
Chain-of-Programming (CoP) : Empowering Large Language Models for Geospatial Code Generation
Nov 16, 2024



With the rapid growth of interdisciplinary demands for geospatial modeling and the rise of large language models (LLMs), geospatial code generation technology has seen significant advancements. However, existing LLMs often face challenges in the geospatial code generation process due to incomplete or unclear user requirements and insufficient knowledge of specific platform syntax rules, leading to the generation of non-executable code, a phenomenon known as "code hallucination." To address this issue, this paper proposes a Chain of Programming (CoP) framework, which decomposes the code generation process into five steps: requirement analysis, algorithm design, code implementation, code debugging, and code annotation. The framework incorporates a shared information pool, knowledge base retrieval, and user feedback mechanisms, forming an end-to-end code generation flow from requirements to code without the need for model fine-tuning. Based on a geospatial problem classification framework and evaluation benchmarks, the CoP strategy significantly improves the logical clarity, syntactical correctness, and executability of the generated code, with improvements ranging from 3.0% to 48.8%. Comparative and ablation experiments further validate the superiority of the CoP strategy over other optimization approaches and confirm the rationality and necessity of its key components. Through case studies on building data visualization and fire data analysis, this paper demonstrates the application and effectiveness of CoP in various geospatial scenarios. The CoP framework offers a systematic, step-by-step approach to LLM-based geospatial code generation tasks, significantly enhancing code generation performance in geospatial tasks and providing valuable insights for code generation in other vertical domains.
Geo-FuB: A Method for Constructing an Operator-Function Knowledge Base for Geospatial Code Generation Tasks Using Large Language Models
Oct 28, 2024



The rise of spatiotemporal data and the need for efficient geospatial modeling have spurred interest in automating these tasks with large language models (LLMs). However, general LLMs often generate errors in geospatial code due to a lack of domain-specific knowledge on functions and operators. To address this, a retrieval-augmented generation (RAG) approach, utilizing an external knowledge base of geospatial functions and operators, is proposed. This study introduces a framework to construct such a knowledge base, leveraging geospatial script semantics. The framework includes: Function Semantic Framework Construction (Geo-FuSE), Frequent Operator Combination Statistics (Geo-FuST), and Semantic Mapping (Geo-FuM). Techniques like Chain-of-Thought, TF-IDF, and the APRIORI algorithm are utilized to derive and align geospatial functions. An example knowledge base, Geo-FuB, built from 154,075 Google Earth Engine scripts, is available on GitHub. Evaluation metrics show a high accuracy, reaching 88.89% overall, with structural and semantic accuracies of 92.03% and 86.79% respectively. Geo-FuB's potential to optimize geospatial code generation through the RAG and fine-tuning paradigms is highlighted.
GeoCode-GPT: A Large Language Model for Geospatial Code Generation Tasks
Oct 23, 2024



The increasing demand for spatiotemporal data and modeling tasks in geosciences has made geospatial code generation technology a critical factor in enhancing productivity. Although large language models (LLMs) have demonstrated potential in code generation tasks, they often encounter issues such as refusal to code or hallucination in geospatial code generation due to a lack of domain-specific knowledge and code corpora. To address these challenges, this paper presents and open-sources the GeoCode-PT and GeoCode-SFT corpora, along with the GeoCode-Eval evaluation dataset. Additionally, by leveraging QLoRA and LoRA for pretraining and fine-tuning, we introduce GeoCode-GPT-7B, the first LLM focused on geospatial code generation, fine-tuned from Code Llama-7B. Furthermore, we establish a comprehensive geospatial code evaluation framework, incorporating option matching, expert validation, and prompt engineering scoring for LLMs, and systematically evaluate GeoCode-GPT-7B using the GeoCode-Eval dataset. Experimental results show that GeoCode-GPT outperforms other models in multiple-choice accuracy by 9.1% to 32.1%, in code summarization ability by 1.7% to 25.4%, and in code generation capability by 1.2% to 25.1%. This paper provides a solution and empirical validation for enhancing LLMs' performance in geospatial code generation, extends the boundaries of domain-specific model applications, and offers valuable insights into unlocking their potential in geospatial code generation.
Uncertainty-Aware Multi-View Visual Semantic Embedding
Sep 15, 2023
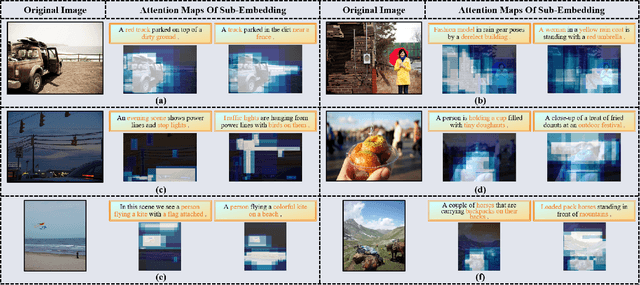
The key challenge in image-text retrieval is effectively leveraging semantic information to measure the similarity between vision and language data. However, using instance-level binary labels, where each image is paired with a single text, fails to capture multiple correspondences between different semantic units, leading to uncertainty in multi-modal semantic understanding. Although recent research has captured fine-grained information through more complex model structures or pre-training techniques, few studies have directly modeled uncertainty of correspondence to fully exploit binary labels. To address this issue, we propose an Uncertainty-Aware Multi-View Visual Semantic Embedding (UAMVSE)} framework that decomposes the overall image-text matching into multiple view-text matchings. Our framework introduce an uncertainty-aware loss function (UALoss) to compute the weighting of each view-text loss by adaptively modeling the uncertainty in each view-text correspondence. Different weightings guide the model to focus on different semantic information, enhancing the model's ability to comprehend the correspondence of images and texts. We also design an optimized image-text matching strategy by normalizing the similarity matrix to improve model performance. Experimental results on the Flicker30k and MS-COCO datasets demonstrate that UAMVSE outperforms state-of-the-art models.
Minimizing Maximum Model Discrepancy for Transferable Black-box Targeted Attacks
Dec 18, 2022



In this work, we study the black-box targeted attack problem from the model discrepancy perspective. On the theoretical side, we present a generalization error bound for black-box targeted attacks, which gives a rigorous theoretical analysis for guaranteeing the success of the attack. We reveal that the attack error on a target model mainly depends on empirical attack error on the substitute model and the maximum model discrepancy among substitute models. On the algorithmic side, we derive a new algorithm for black-box targeted attacks based on our theoretical analysis, in which we additionally minimize the maximum model discrepancy(M3D) of the substitute models when training the generator to generate adversarial examples. In this way, our model is capable of crafting highly transferable adversarial examples that are robust to the model variation, thus improving the success rate for attacking the black-box model. We conduct extensive experiments on the ImageNet dataset with different classification models, and our proposed approach outperforms existing state-of-the-art methods by a significant margin. Our codes will be released.
Neyman-Pearson Classification under High-Dimensional Settings
Aug 15, 2015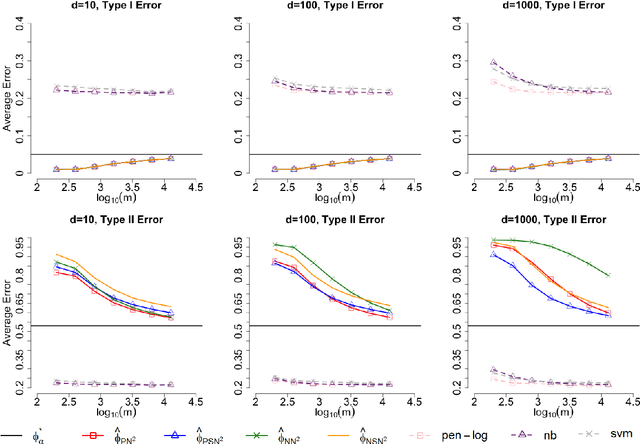



Most existing binary classification methods target on the optimization of the overall classification risk and may fail to serve some real-world applications such as cancer diagnosis, where users are more concerned with the risk of misclassifying one specific class than the other. Neyman-Pearson (NP) paradigm was introduced in this context as a novel statistical framework for handling asymmetric type I/II error priorities. It seeks classifiers with a minimal type II error and a constrained type I error under a user specified level. This article is the first attempt to construct classifiers with guaranteed theoretical performance under the NP paradigm in high-dimensional settings. Based on the fundamental Neyman-Pearson Lemma, we used a plug-in approach to construct NP-type classifiers for Naive Bayes models. The proposed classifiers satisfy the NP oracle inequalities, which are natural NP paradigm counterparts of the oracle inequalities in classical binary classification. Besides their desirable theoretical properties, we also demonstrated their numerical advantages in prioritized error control via both simulation and real data studies.