 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Group-Aware Hashing for Fast Recommender Systems
Dec 23, 2025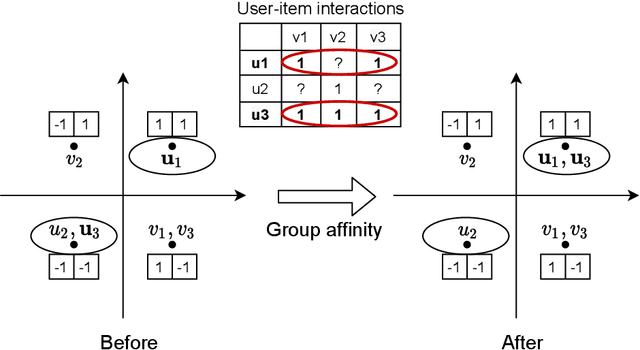

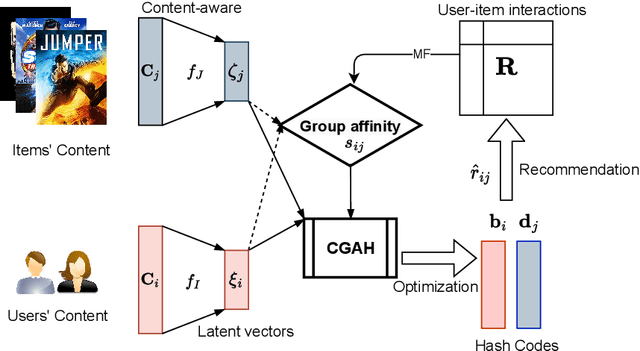
The fast online recommendation is critical for applications with large-scale databases; meanwhile, it is challenging to provide accurate recommendations in sparse scenarios. Hash technique has shown its superiority for speeding up the online recommendation by bit operations on Hamming distance computations. However, existing hashing-based recommendations suffer from low accuracy, especially with sparse settings, due to the limited representation capability of each bit and neglected inherent relations among users and items. To this end, this paper lodges a Collaborative Group-Aware Hashing (CGAH) method for both collaborative filtering (namely CGAH-CF) and content-aware recommendations (namely CGAH) by integrating the inherent group information to alleviate the sparse issue. Firstly, we extract inherent group affinities of users and items by classifying their latent vectors into different groups. Then, the preference is formulated as the inner product of the group affinity and the similarity of hash codes. By learning hash codes with the inherent group information, CGAH obtains more effective hash codes than other discrete methods with sparse interactive data. Extensive experiments on three public datasets show the superior performance of our proposed CGAH and CGAH-CF over the state-of-the-art discrete collaborative filtering methods and discrete content-aware recommendations under different sparse settings.
The Devil is in Attention Sharing: Improving Complex Non-rigid Image Editing Faithfulness via Attention Synergy
Dec 17, 2025Training-free image editing with large diffusion models has become practical, yet faithfully performing complex non-rigid edits (e.g., pose or shape changes) remains highly challenging. We identify a key underlying cause: attention collapse in existing attention sharing mechanisms, where either positional embeddings or semantic features dominate visual content retrieval, leading to over-editing or under-editing. To address this issue, we introduce SynPS, a method that Synergistically leverages Positional embeddings and Semantic information for faithful non-rigid image editing. We first propose an editing measurement that quantifies the required editing magnitude at each denoising step. Based on this measurement, we design an attention synergy pipeline that dynamically modulates the influence of positional embeddings, enabling SynPS to balance semantic modifications and fidelity preservation. By adaptively integrating positional and semantic cues, SynPS effectively avoids both over- and under-editing. Extensive experiments on public and newly curated benchmarks demonstrate the superior performance and faithfulness of our approach.
Balanced Sharpness-Aware Minimization for Imbalanced Regression
Aug 23, 2025Regression is fundamental in computer vision and is widely used in various tasks including age estimation, depth estimation, target localization, \etc However, real-world data often exhibits imbalanced distribution, making regression models perform poorly especially for target values with rare observations~(known as the imbalanced regression problem). In this paper, we reframe imbalanced regression as an imbalanced generalization problem. To tackle that, we look into the loss sharpness property for measuring the generalization ability of regression models in the observation space. Namely, given a certain perturbation on the model parameters, we check how model performance changes according to the loss values of different target observations. We propose a simple yet effective approach called Balanced Sharpness-Aware Minimization~(BSAM) to enforce the uniform generalization ability of regression models for the entire observation space. In particular, we start from the traditional sharpness-aware minimization and then introduce a novel targeted reweighting strategy to homogenize the generalization ability across the observation space, which guarantees a theoretical generalization bound. Extensive experiments on multiple vision regression tasks, including age and depth estimation, demonstrate that our BSAM method consistently outperforms existing approaches. The code is available \href{https://github.com/manmanjun/BSAM_for_Imbalanced_Regression}{here}.
Discrete Scale-invariant Metric Learning for Efficient Collaborative Filtering
Jun 11, 2025Metric learning has attracted extensive interest for its ability to provide personalized recommendations based on the importance of observed user-item interactions. Current metric learning methods aim to push negative items away from the corresponding users and positive items by an absolute geometrical distance margin. However, items may come from imbalanced categories with different intra-class variations. Thus, the absolute distance margin may not be ideal for estimating the difference between user preferences over imbalanced items. To this end, we propose a new method, named discrete scale-invariant metric learning (DSIML), by adding binary constraints to users and items, which maps users and items into binary codes of a shared Hamming subspace to speed up the online recommendation. Specifically, we firstly propose a scale-invariant margin based on angles at the negative item points in the shared Hamming subspace. Then, we derive a scale-invariant triple hinge loss based on the margin. To capture more preference difference information, we integrate a pairwise ranking loss into the scale-invariant loss in the proposed model. Due to the difficulty of directly optimizing the mixed integer optimization problem formulated with \textit{log-sum-exp} functions, we seek to optimize its variational quadratic upper bound and learn hash codes with an alternating optimization strategy. Experiments on benchmark datasets clearly show that our proposed method is superior to competitive metric learning and hashing-based baselines for recommender systems. The implementation code is available at https://github.com/AnonyFeb/dsml.
Semantic segmentation with reward
May 23, 2025In real-world scenarios, pixel-level labeling is not always available. Sometimes, we need a semantic segmentation network, and even a visual encoder can have a high compatibility, and can be trained using various types of feedback beyond traditional labels, such as feedback that indicates the quality of the parsing results. To tackle this issue, we proposed RSS (Reward in Semantic Segmentation), the first practical application of reward-based reinforcement learning on pure semantic segmentation offered in two granular levels (pixel-level and image-level). RSS incorporates various novel technologies, such as progressive scale rewards (PSR) and pair-wise spatial difference (PSD), to ensure that the reward facilitates the convergence of the semantic segmentation network, especially under image-level rewards. Experiments and visualizations on benchmark datasets demonstrate that the proposed RSS can successfully ensure the convergence of the semantic segmentation network on two levels of rewards. Additionally, the RSS, which utilizes an image-level reward, outperforms existing weakly supervised methods that also rely solely on image-level signals during training.
VPNeXt -- Rethinking Dense Decoding for Plain Vision Transformer
Feb 25, 2025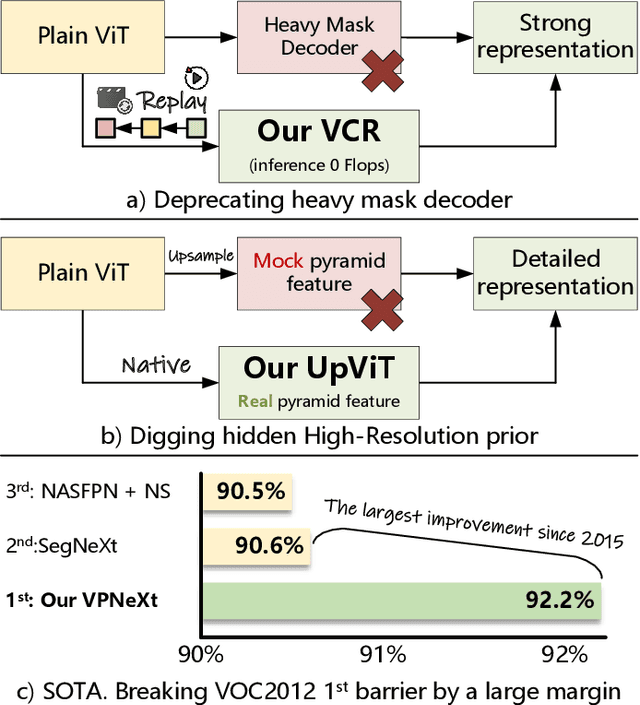



We present VPNeXt, a new and simple model for the Plain Vision Transformer (ViT). Unlike the many related studies that share the same homogeneous paradigms, VPNeXt offers a fresh perspective on dense representation based on ViT. In more detail, the proposed VPNeXt addressed two concerns about the existing paradigm: (1) Is it necessary to use a complex Transformer Mask Decoder architecture to obtain good representations? (2) Does the Plain ViT really need to depend on the mock pyramid feature for upsampling? For (1), we investigated the potential underlying reasons that contributed to the effectiveness of the Transformer Decoder and introduced the Visual Context Replay (VCR) to achieve similar effects efficiently. For (2), we introduced the ViTUp module. This module fully utilizes the previously overlooked ViT real pyramid feature to achieve better upsampling results compared to the earlier mock pyramid feature. This represents the first instance of such functionality in the field of semantic segmentation for Plain ViT. We performed ablation studies on related modules to verify their effectiveness gradually. We conducted relevant comparative experiments and visualizations to show that VPNeXt achieved state-of-the-art performance with a simple and effective design. Moreover, the proposed VPNeXt significantly exceeded the long-established mIoU wall/barrier of the VOC2012 dataset, setting a new state-of-the-art by a large margin, which also stands as the largest improvement since 2015.
The Devil is in the Spurious Correlation: Boosting Moment Retrieval via Temporal Dynamic Learning
Jan 13, 2025



Given a textual query along with a corresponding video, the objective of moment retrieval aims to localize the moments relevant to the query within the video. While commendable results have been demonstrated by existing transformer-based approaches, predicting the accurate temporal span of the target moment is currently still a major challenge. In this paper, we reveal that a crucial reason stems from the spurious correlation between the text queries and the moment context. Namely, the model may associate the textual query with the background frames rather than the target moment. To address this issue, we propose a temporal dynamic learning approach for moment retrieval, where two strategies are designed to mitigate the spurious correlation. First, we introduce a novel video synthesis approach to construct a dynamic context for the relevant moment. With separate yet similar videos mixed up, the synthesis approach empowers our model to attend to the target moment of the corresponding query under various dynamic contexts. Second, we enhance the representation by learning temporal dynamics. Besides the visual representation, text queries are aligned with temporal dynamic representations, which enables our model to establish a non-spurious correlation between the query-related moment and context. With the aforementioned proposed method, the spurious correlation issue in moment retrieval can be largely alleviated. Our method establishes a new state-of-the-art performance on two popular benchmarks of moment retrieval, \ie, QVHighlights and Charades-STA. In addition, the detailed ablation analyses demonstrate the effectiveness of the proposed strategies. Our code will be publicly available.
Towards Unsupervised Model Selection for Domain Adaptive Object Detection
Dec 23, 2024



Evaluating the performance of deep models in new scenarios has drawn increasing attention in recent years. However, while it is possible to collect data from new scenarios, the annotations are not always available. Existing DAOD methods often rely on validation or test sets on the target domain for model selection, which is impractical in real-world applications. In this paper, we propose a novel unsupervised model selection approach for domain adaptive object detection, which is able to select almost the optimal model for the target domain without using any target labels. Our approach is based on the flat minima principle, i,e., models located in the flat minima region in the parameter space usually exhibit excellent generalization ability. However, traditional methods require labeled data to evaluate how well a model is located in the flat minima region, which is unrealistic for the DAOD task. Therefore, we design a Detection Adaptation Score (DAS) approach to approximately measure the flat minima without using target labels. We show via a generalization bound that the flatness can be deemed as model variance, while the minima depend on the domain distribution distance for the DAOD task. Accordingly, we propose a Flatness Index Score (FIS) to assess the flatness by measuring the classification and localization fluctuation before and after perturbations of model parameters and a Prototypical Distance Ratio (PDR) score to seek the minima by measuring the transferability and discriminability of the models. In this way, the proposed DAS approach can effectively evaluate the model generalization ability on the target domain. We have conducted extensive experiments on various DAOD benchmarks and approaches, and the experimental results show that the proposed DAS correlates well with the performance of DAOD models and can be used as an effective tool for model selection after training.
S-INF: Towards Realistic Indoor Scene Synthesis via Scene Implicit Neural Field
Dec 23, 2024Learning-based methods have become increasingly popular in 3D indoor scene synthesis (ISS), showing superior performance over traditional optimization-based approaches. These learning-based methods typically model distributions on simple yet explicit scene representations using generative models. However, due to the oversimplified explicit representations that overlook detailed information and the lack of guidance from multimodal relationships within the scene, most learning-based methods struggle to generate indoor scenes with realistic object arrangements and styles. In this paper, we introduce a new method, Scene Implicit Neural Field (S-INF), for indoor scene synthesis, aiming to learn meaningful representations of multimodal relationships, to enhance the realism of indoor scene synthesis. S-INF assumes that the scene layout is often related to the object-detailed information. It disentangles the multimodal relationships into scene layout relationships and detailed object relationships, fusing them later through implicit neural fields (INFs). By learning specialized scene layout relationships and projecting them into S-INF, we achieve a realistic generation of scene layout. Additionally, S-INF captures dense and detailed object relationships through differentiable rendering, ensuring stylistic consistency across objects. Through extensive experiments on the benchmark 3D-FRONT dataset, we demonstrate that our method consistently achieves state-of-the-art performance under different types of ISS.
ResCLIP: Residual Attention for Training-free Dense Vision-language Inference
Nov 24, 2024


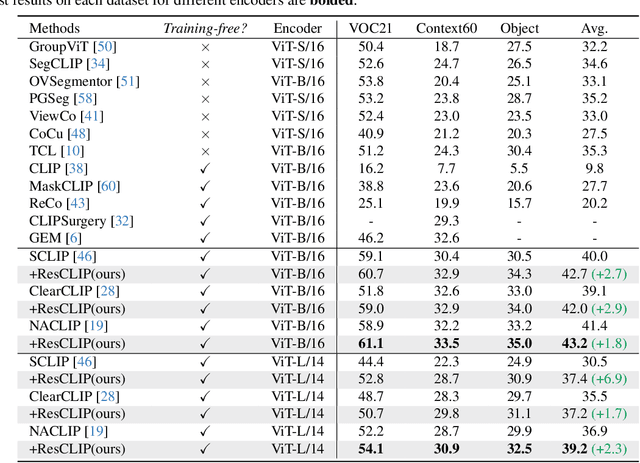
While vision-language models like CLIP have shown remarkable success in open-vocabulary tasks, their application is currently confined to image-level tasks, and they still struggle with dense predictions. Recent works often attribute such deficiency in dense predictions to the self-attention layers in the final block, and have achieved commendable results by modifying the original query-key attention to self-correlation attention, (e.g., query-query and key-key attention). However, these methods overlook the cross-correlation attention (query-key) properties, which capture the rich spatial correspondence. In this paper, we reveal that the cross-correlation of the self-attention in CLIP's non-final layers also exhibits localization properties. Therefore, we propose the Residual Cross-correlation Self-attention (RCS) module, which leverages the cross-correlation self-attention from intermediate layers to remold the attention in the final block. The RCS module effectively reorganizes spatial information, unleashing the localization potential within CLIP for dense vision-language inference. Furthermore, to enhance the focus on regions of the same categories and local consistency, we propose the Semantic Feedback Refinement (SFR) module, which utilizes semantic segmentation maps to further adjust the attention scores. By integrating these two strategies, our method, termed ResCLIP, can be easily incorporated into existing approaches as a plug-and-play module, significantly boosting their performance in dense vision-language inference. Extensive experiments across multiple standard benchmarks demonstrate that our method surpasses state-of-the-art training-free methods, validating the effectiveness of the proposed approach. Code is available at https://github.com/yvhangyang/ResCLIP.