 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeformation-based In-Context Learning for Point Cloud Understanding
Apr 03, 2026Recent advances in point cloud In-Context Learning (ICL) have demonstrated strong multitask capabilities. Existing approaches typically adopt a Masked Point Modeling (MPM)-based paradigm for point cloud ICL. However, MPM-based methods directly predict the target point cloud from masked tokens without leveraging geometric priors, requiring the model to infer spatial structure and geometric details solely from token-level correlations via transformers. Additionally, these methods suffer from a training-inference objective mismatch, as the model learns to predict the target point cloud using target-side information that is unavailable at inference time. To address these challenges, we propose DeformPIC, a deformation-based framework for point cloud ICL. Unlike existing approaches that rely on masked reconstruction, DeformPIC learns to deform the query point cloud under task-specific guidance from prompts, enabling explicit geometric reasoning and consistent objectives. Extensive experiments demonstrate that DeformPIC consistently outperforms previous state-of-the-art methods, achieving reductions of 1.6, 1.8, and 4.7 points in average Chamfer Distance on reconstruction, denoising, and registration tasks, respectively. Furthermore, we introduce a new out-of-domain benchmark to evaluate generalization across unseen data distributions, where DeformPIC achieves state-of-the-art performance.
Dataset Color Quantization: A Training-Oriented Framework for Dataset-Level Compression
Feb 24, 2026Large-scale image datasets are fundamental to deep learning, but their high storage demands pose challenges for deployment in resource-constrained environments. While existing approaches reduce dataset size by discarding samples, they often ignore the significant redundancy within each image -- particularly in the color space. To address this, we propose Dataset Color Quantization (DCQ), a unified framework that compresses visual datasets by reducing color-space redundancy while preserving information crucial for model training. DCQ achieves this by enforcing consistent palette representations across similar images, selectively retaining semantically important colors guided by model perception, and maintaining structural details necessary for effective feature learning. Extensive experiments across CIFAR-10, CIFAR-100, Tiny-ImageNet, and ImageNet-1K show that DCQ significantly improves training performance under aggressive compression, offering a scalable and robust solution for dataset-level storage reduction. Code is available at \href{https://github.com/he-y/Dataset-Color-Quantization}{https://github.com/he-y/Dataset-Color-Quantization}.
Instance-Free Domain Adaptive Object Detection
Feb 06, 2026While Domain Adaptive Object Detection (DAOD) has made significant strides, most methods rely on unlabeled target data that is assumed to contain sufficient foreground instances. However, in many practical scenarios (e.g., wildlife monitoring, lesion detection), collecting target domain data with objects of interest is prohibitively costly, whereas background-only data is abundant. This common practical constraint introduces a significant technical challenge: the difficulty of achieving domain alignment when target instances are unavailable, forcing adaptation to rely solely on the target background information. We formulate this challenge as the novel problem of Instance-Free Domain Adaptive Object Detection. To tackle this, we propose the Relational and Structural Consistency Network (RSCN) which pioneers an alignment strategy based on background feature prototypes while simultaneously encouraging consistency in the relationship between the source foreground features and the background features within each domain, enabling robust adaptation even without target instances. To facilitate research, we further curate three specialized benchmarks, including simulative auto-driving detection, wildlife detection, and lung nodule detection. Extensive experiments show that RSCN significantly outperforms existing DAOD methods across all three benchmarks in the instance-free scenario. The code and benchmarks will be released soon.
Towards Unsupervised Model Selection for Domain Adaptive Object Detection
Dec 23, 2024



Evaluating the performance of deep models in new scenarios has drawn increasing attention in recent years. However, while it is possible to collect data from new scenarios, the annotations are not always available. Existing DAOD methods often rely on validation or test sets on the target domain for model selection, which is impractical in real-world applications. In this paper, we propose a novel unsupervised model selection approach for domain adaptive object detection, which is able to select almost the optimal model for the target domain without using any target labels. Our approach is based on the flat minima principle, i,e., models located in the flat minima region in the parameter space usually exhibit excellent generalization ability. However, traditional methods require labeled data to evaluate how well a model is located in the flat minima region, which is unrealistic for the DAOD task. Therefore, we design a Detection Adaptation Score (DAS) approach to approximately measure the flat minima without using target labels. We show via a generalization bound that the flatness can be deemed as model variance, while the minima depend on the domain distribution distance for the DAOD task. Accordingly, we propose a Flatness Index Score (FIS) to assess the flatness by measuring the classification and localization fluctuation before and after perturbations of model parameters and a Prototypical Distance Ratio (PDR) score to seek the minima by measuring the transferability and discriminability of the models. In this way, the proposed DAS approach can effectively evaluate the model generalization ability on the target domain. We have conducted extensive experiments on various DAOD benchmarks and approaches, and the experimental results show that the proposed DAS correlates well with the performance of DAOD models and can be used as an effective tool for model selection after training.
ResCLIP: Residual Attention for Training-free Dense Vision-language Inference
Nov 24, 2024


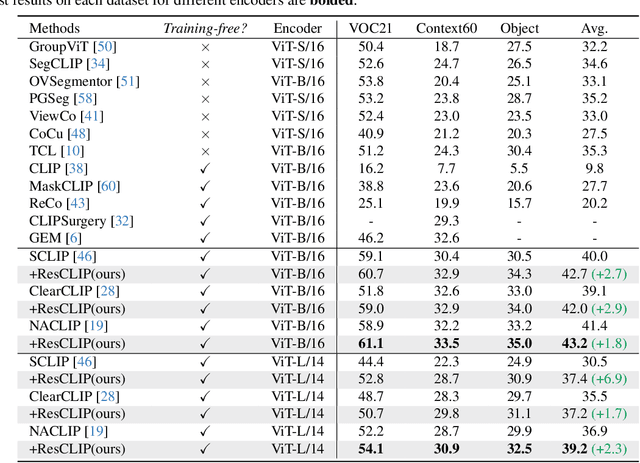
While vision-language models like CLIP have shown remarkable success in open-vocabulary tasks, their application is currently confined to image-level tasks, and they still struggle with dense predictions. Recent works often attribute such deficiency in dense predictions to the self-attention layers in the final block, and have achieved commendable results by modifying the original query-key attention to self-correlation attention, (e.g., query-query and key-key attention). However, these methods overlook the cross-correlation attention (query-key) properties, which capture the rich spatial correspondence. In this paper, we reveal that the cross-correlation of the self-attention in CLIP's non-final layers also exhibits localization properties. Therefore, we propose the Residual Cross-correlation Self-attention (RCS) module, which leverages the cross-correlation self-attention from intermediate layers to remold the attention in the final block. The RCS module effectively reorganizes spatial information, unleashing the localization potential within CLIP for dense vision-language inference. Furthermore, to enhance the focus on regions of the same categories and local consistency, we propose the Semantic Feedback Refinement (SFR) module, which utilizes semantic segmentation maps to further adjust the attention scores. By integrating these two strategies, our method, termed ResCLIP, can be easily incorporated into existing approaches as a plug-and-play module, significantly boosting their performance in dense vision-language inference. Extensive experiments across multiple standard benchmarks demonstrate that our method surpasses state-of-the-art training-free methods, validating the effectiveness of the proposed approach. Code is available at https://github.com/yvhangyang/ResCLIP.
Domain Adaptive Detection of MAVs: A Benchmark and Noise Suppression Network
Mar 25, 2024



Visual detection of Micro Air Vehicles (MAVs) has attracted increasing attention in recent years due to its important application in various tasks. The existing methods for MAV detection assume that the training set and testing set have the same distribution. As a result, when deployed in new domains, the detectors would have a significant performance degradation due to domain discrepancy. In this paper, we study the problem of cross-domain MAV detection. The contributions of this paper are threefold. 1) We propose a Multi-MAV-Multi-Domain (M3D) dataset consisting of both simulation and realistic images. Compared to other existing datasets, the proposed one is more comprehensive in the sense that it covers rich scenes, diverse MAV types, and various viewing angles. A new benchmark for cross-domain MAV detection is proposed based on the proposed dataset. 2) We propose a Noise Suppression Network (NSN) based on the framework of pseudo-labeling and a large-to-small training procedure. To reduce the challenging pseudo-label noises, two novel modules are designed in this network. The first is a prior-based curriculum learning module for allocating adaptive thresholds for pseudo labels with different difficulties. The second is a masked copy-paste augmentation module for pasting truly-labeled MAVs on unlabeled target images and thus decreasing pseudo-label noises. 3) Extensive experimental results verify the superior performance of the proposed method compared to the state-of-the-art ones. In particular, it achieves mAP of 46.9%(+5.8%), 50.5%(+3.7%), and 61.5%(+11.3%) on the tasks of simulation-to-real adaptation, cross-scene adaptation, and cross-camera adaptation, respectively.
* 17 pages, 11 figures. Accepted by IEEE Transactions on Automation Science and Engineering
Motion and Appearance Adaptation for Cross-Domain Motion Transfer
Oct 06, 2022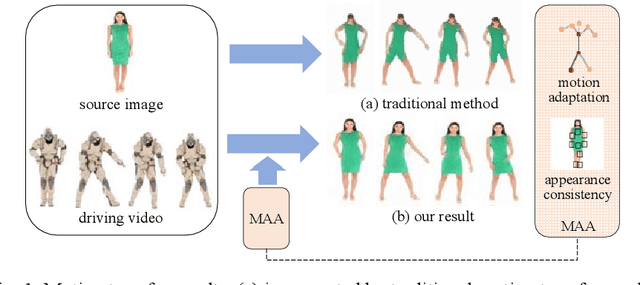
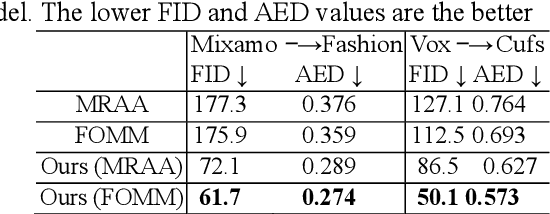
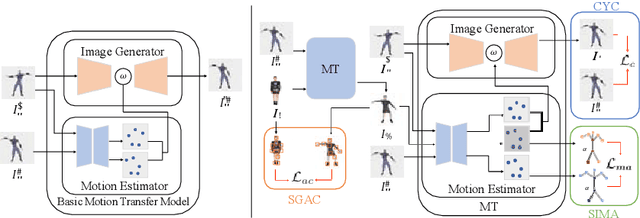
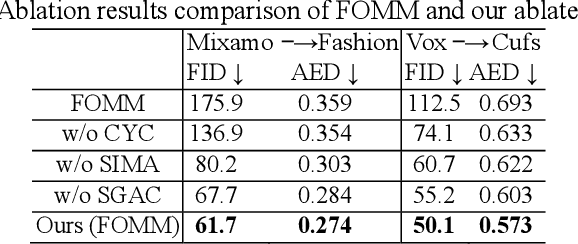
Motion transfer aims to transfer the motion of a driving video to a source image. When there are considerable differences between object in the driving video and that in the source image, traditional single domain motion transfer approaches often produce notable artifacts; for example, the synthesized image may fail to preserve the human shape of the source image (cf . Fig. 1 (a)). To address this issue, in this work, we propose a Motion and Appearance Adaptation (MAA) approach for cross-domain motion transfer, in which we regularize the object in the synthesized image to capture the motion of the object in the driving frame, while still preserving the shape and appearance of the object in the source image. On one hand, considering the object shapes of the synthesized image and the driving frame might be different, we design a shape-invariant motion adaptation module that enforces the consistency of the angles of object parts in two images to capture the motion information. On the other hand, we introduce a structure-guided appearance consistency module designed to regularize the similarity between the corresponding patches of the synthesized image and the source image without affecting the learned motion in the synthesized image. Our proposed MAA model can be trained in an end-to-end manner with a cyclic reconstruction loss, and ultimately produces a satisfactory motion transfer result (cf . Fig. 1 (b)). We conduct extensive experiments on human dancing dataset Mixamo-Video to Fashion-Video and human face dataset Vox-Celeb to Cufs; on both of these, our MAA model outperforms existing methods both quantitatively and qualitatively.
Revisiting AP Loss for Dense Object Detection: Adaptive Ranking Pair Selection
Jul 25, 2022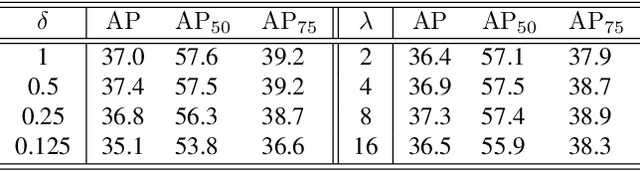
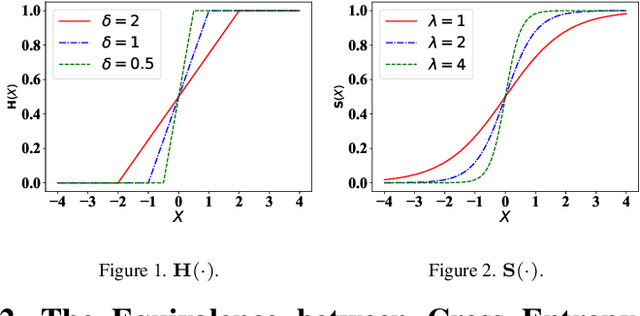
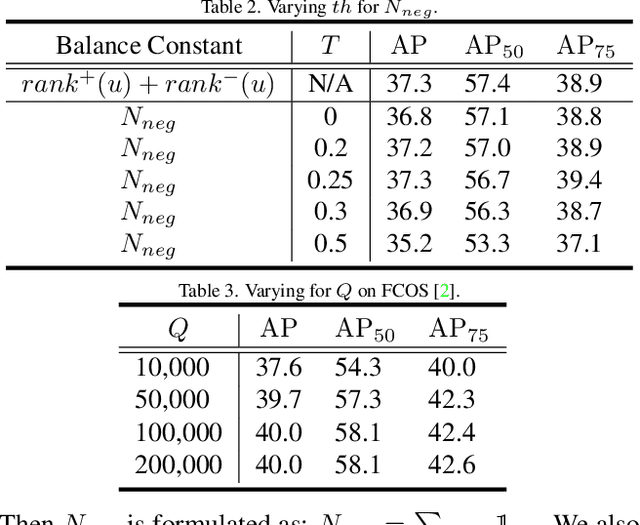
Average precision (AP) loss has recently shown promising performance on the dense object detection task. However,a deep understanding of how AP loss affects the detector from a pairwise ranking perspective has not yet been developed.In this work, we revisit the average precision (AP)loss and reveal that the crucial element is that of selecting the ranking pairs between positive and negative samples.Based on this observation, we propose two strategies to improve the AP loss. The first of these is a novel Adaptive Pairwise Error (APE) loss that focusing on ranking pairs in both positive and negative samples. Moreover,we select more accurate ranking pairs by exploiting the normalized ranking scores and localization scores with a clustering algorithm. Experiments conducted on the MSCOCO dataset support our analysis and demonstrate the superiority of our proposed method compared with current classification and ranking loss. The code is available at https://github.com/Xudangliatiger/APE-Loss.
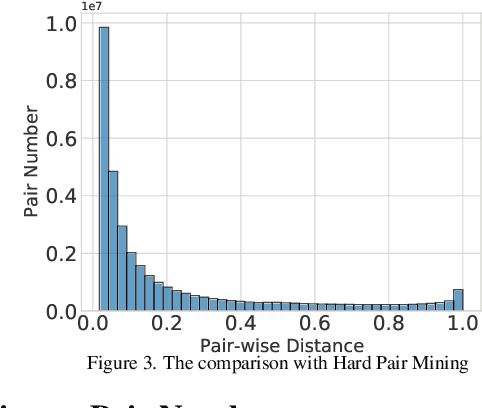
Cross-domain Detection Transformer based on Spatial-aware and Semantic-aware Token Alignment
Jun 01, 2022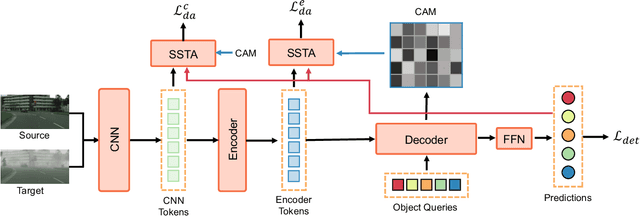
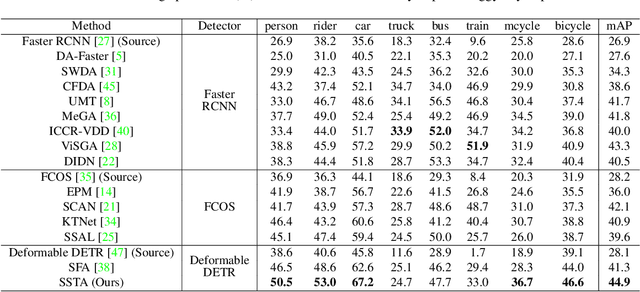
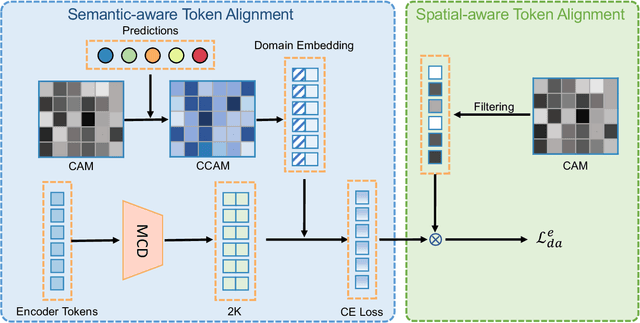
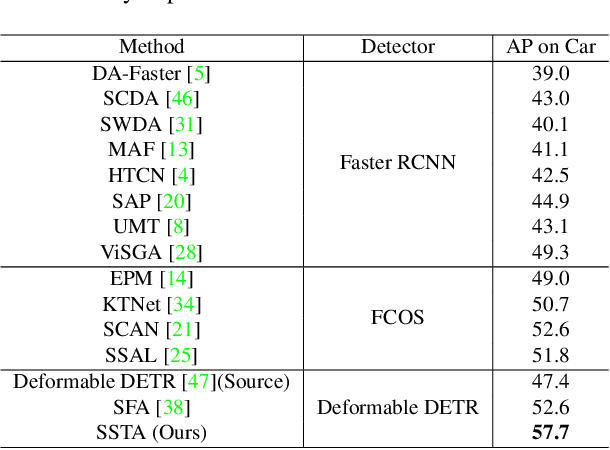
Detection transformers like DETR have recently shown promising performance on many object detection tasks, but the generalization ability of those methods is still quite challenging for cross-domain adaptation scenarios. To address the cross-domain issue, a straightforward way is to perform token alignment with adversarial training in transformers. However, its performance is often unsatisfactory as the tokens in detection transformers are quite diverse and represent different spatial and semantic information. In this paper, we propose a new method called Spatial-aware and Semantic-aware Token Alignment (SSTA) for cross-domain detection transformers. In particular, we take advantage of the characteristics of cross-attention as used in detection transformer and propose the spatial-aware token alignment (SpaTA) and the semantic-aware token alignment (SemTA) strategies to guide the token alignment across domains. For spatial-aware token alignment, we can extract the information from the cross-attention map (CAM) to align the distribution of tokens according to their attention to object queries. For semantic-aware token alignment, we inject the category information into the cross-attention map and construct domain embedding to guide the learning of a multi-class discriminator so as to model the category relationship and achieve category-level token alignment during the entire adaptation process. We conduct extensive experiments on several widely-used benchmarks, and the results clearly show the effectiveness of our proposed method over existing state-of-the-art baselines.
Undoing the Damage of Label Shift for Cross-domain Semantic Segmentation
Apr 12, 2022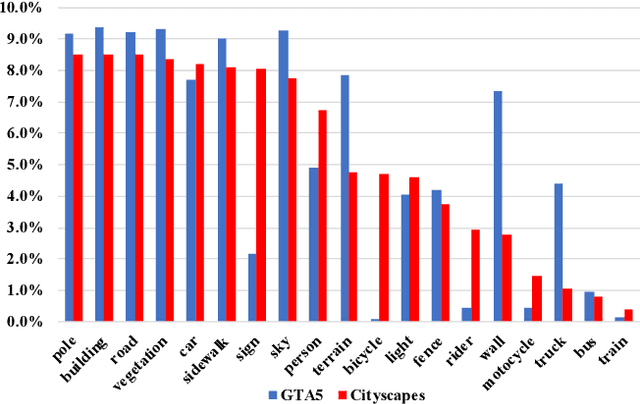
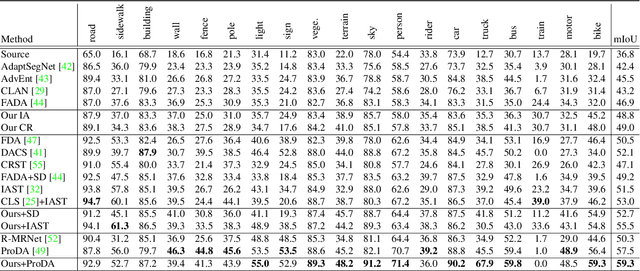
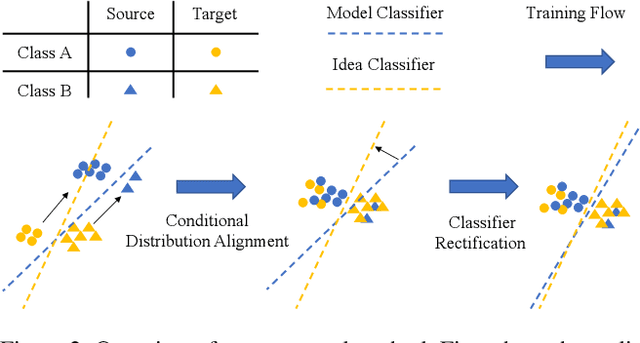
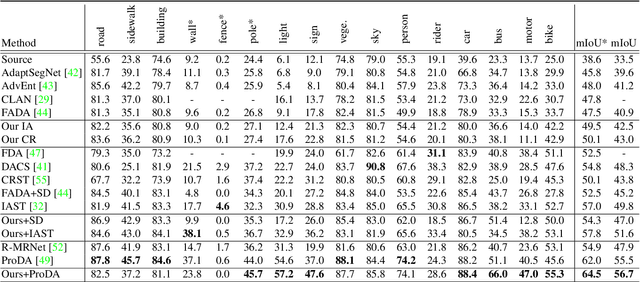
Existing works typically treat cross-domain semantic segmentation (CDSS) as a data distribution mismatch problem and focus on aligning the marginal distribution or conditional distribution. However, the label shift issue is unfortunately overlooked, which actually commonly exists in the CDSS task, and often causes a classifier bias in the learnt model. In this paper, we give an in-depth analysis and show that the damage of label shift can be overcome by aligning the data conditional distribution and correcting the posterior probability. To this end, we propose a novel approach to undo the damage of the label shift problem in CDSS. In implementation, we adopt class-level feature alignment for conditional distribution alignment, as well as two simple yet effective methods to rectify the classifier bias from source to target by remolding the classifier predictions. We conduct extensive experiments on the benchmark datasets of urban scenes, including GTA5 to Cityscapes and SYNTHIA to Cityscapes, where our proposed approach outperforms previous methods by a large margin. For instance, our model equipped with a self-training strategy reaches 59.3% mIoU on GTA5 to Cityscapes, pushing to a new state-of-the-art. The code will be available at https://github.com/manmanjun/Undoing UDA.