 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-domain Detection Transformer based on Spatial-aware and Semantic-aware Token Alignment
Paper and Code
Jun 01, 2022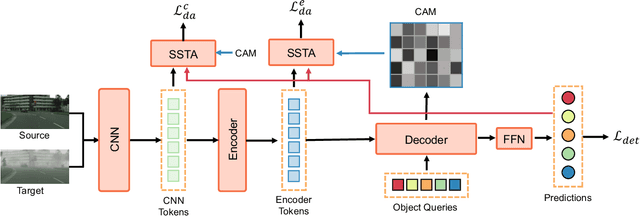
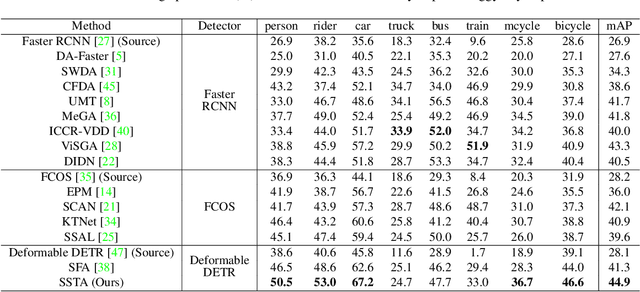
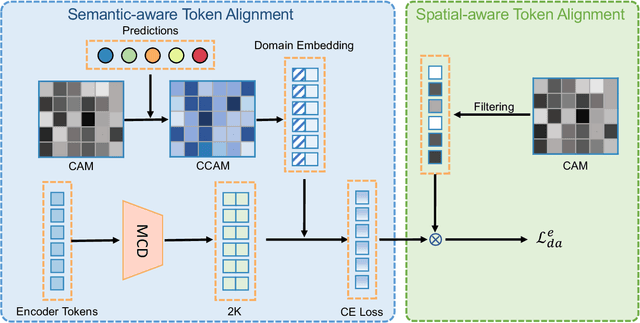
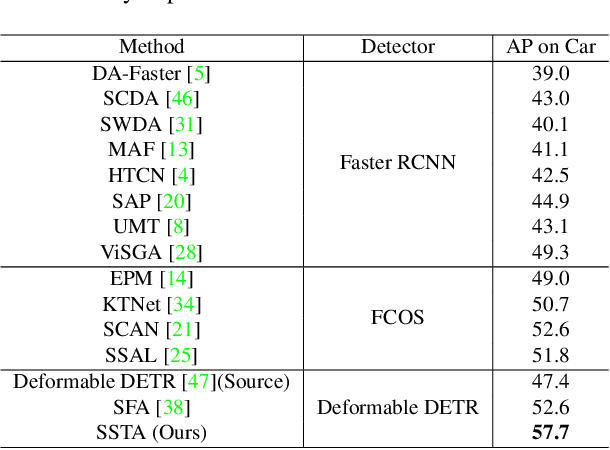
Detection transformers like DETR have recently shown promising performance on many object detection tasks, but the generalization ability of those methods is still quite challenging for cross-domain adaptation scenarios. To address the cross-domain issue, a straightforward way is to perform token alignment with adversarial training in transformers. However, its performance is often unsatisfactory as the tokens in detection transformers are quite diverse and represent different spatial and semantic information. In this paper, we propose a new method called Spatial-aware and Semantic-aware Token Alignment (SSTA) for cross-domain detection transformers. In particular, we take advantage of the characteristics of cross-attention as used in detection transformer and propose the spatial-aware token alignment (SpaTA) and the semantic-aware token alignment (SemTA) strategies to guide the token alignment across domains. For spatial-aware token alignment, we can extract the information from the cross-attention map (CAM) to align the distribution of tokens according to their attention to object queries. For semantic-aware token alignment, we inject the category information into the cross-attention map and construct domain embedding to guide the learning of a multi-class discriminator so as to model the category relationship and achieve category-level token alignment during the entire adaptation process. We conduct extensive experiments on several widely-used benchmarks, and the results clearly show the effectiveness of our proposed method over existing state-of-the-art baselines.