 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResCLIP: Residual Attention for Training-free Dense Vision-language Inference
Paper and Code



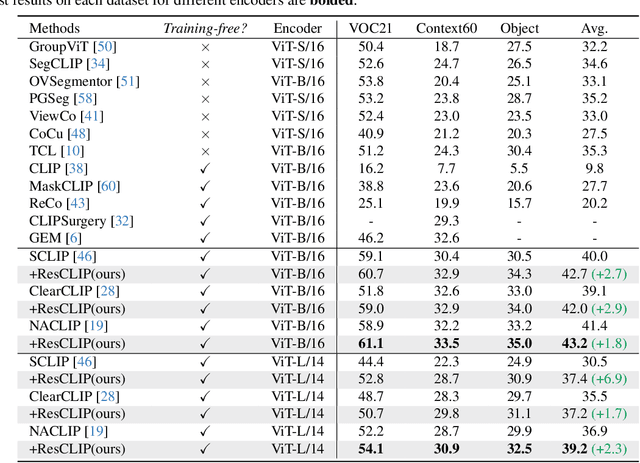
While vision-language models like CLIP have shown remarkable success in open-vocabulary tasks, their application is currently confined to image-level tasks, and they still struggle with dense predictions. Recent works often attribute such deficiency in dense predictions to the self-attention layers in the final block, and have achieved commendable results by modifying the original query-key attention to self-correlation attention, (e.g., query-query and key-key attention). However, these methods overlook the cross-correlation attention (query-key) properties, which capture the rich spatial correspondence. In this paper, we reveal that the cross-correlation of the self-attention in CLIP's non-final layers also exhibits localization properties. Therefore, we propose the Residual Cross-correlation Self-attention (RCS) module, which leverages the cross-correlation self-attention from intermediate layers to remold the attention in the final block. The RCS module effectively reorganizes spatial information, unleashing the localization potential within CLIP for dense vision-language inference. Furthermore, to enhance the focus on regions of the same categories and local consistency, we propose the Semantic Feedback Refinement (SFR) module, which utilizes semantic segmentation maps to further adjust the attention scores. By integrating these two strategies, our method, termed ResCLIP, can be easily incorporated into existing approaches as a plug-and-play module, significantly boosting their performance in dense vision-language inference. Extensive experiments across multiple standard benchmarks demonstrate that our method surpasses state-of-the-art training-free methods, validating the effectiveness of the proposed approach. Code is available at https://github.com/yvhangyang/ResCLIP.