 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet Samples Speak: Mitigating Spurious Correlation by Exploiting the Clusterness of Samples
Dec 28, 2025Deep learning models are known to often learn features that spuriously correlate with the class label during training but are irrelevant to the prediction task. Existing methods typically address this issue by annotating potential spurious attributes, or filtering spurious features based on some empirical assumptions (e.g., simplicity of bias). However, these methods may yield unsatisfactory performance due to the intricate and elusive nature of spurious correlations in real-world data. In this paper, we propose a data-oriented approach to mitigate the spurious correlation in deep learning models. We observe that samples that are influenced by spurious features tend to exhibit a dispersed distribution in the learned feature space. This allows us to identify the presence of spurious features. Subsequently, we obtain a bias-invariant representation by neutralizing the spurious features based on a simple grouping strategy. Then, we learn a feature transformation to eliminate the spurious features by aligning with this bias-invariant representation. Finally, we update the classifier by incorporating the learned feature transformation and obtain an unbiased model. By integrating the aforementioned identifying, neutralizing, eliminating and updating procedures, we build an effective pipeline for mitigating spurious correlation. Experiments on image and NLP debiasing benchmarks show an improvement in worst group accuracy of more than 20% compared to standard empirical risk minimization (ERM). Codes and checkpoints are available at https://github.com/davelee-uestc/nsf_debiasing .
Balanced Sharpness-Aware Minimization for Imbalanced Regression
Aug 23, 2025Regression is fundamental in computer vision and is widely used in various tasks including age estimation, depth estimation, target localization, \etc However, real-world data often exhibits imbalanced distribution, making regression models perform poorly especially for target values with rare observations~(known as the imbalanced regression problem). In this paper, we reframe imbalanced regression as an imbalanced generalization problem. To tackle that, we look into the loss sharpness property for measuring the generalization ability of regression models in the observation space. Namely, given a certain perturbation on the model parameters, we check how model performance changes according to the loss values of different target observations. We propose a simple yet effective approach called Balanced Sharpness-Aware Minimization~(BSAM) to enforce the uniform generalization ability of regression models for the entire observation space. In particular, we start from the traditional sharpness-aware minimization and then introduce a novel targeted reweighting strategy to homogenize the generalization ability across the observation space, which guarantees a theoretical generalization bound. Extensive experiments on multiple vision regression tasks, including age and depth estimation, demonstrate that our BSAM method consistently outperforms existing approaches. The code is available \href{https://github.com/manmanjun/BSAM_for_Imbalanced_Regression}{here}.
Minimizing Maximum Model Discrepancy for Transferable Black-box Targeted Attacks
Dec 18, 2022



In this work, we study the black-box targeted attack problem from the model discrepancy perspective. On the theoretical side, we present a generalization error bound for black-box targeted attacks, which gives a rigorous theoretical analysis for guaranteeing the success of the attack. We reveal that the attack error on a target model mainly depends on empirical attack error on the substitute model and the maximum model discrepancy among substitute models. On the algorithmic side, we derive a new algorithm for black-box targeted attacks based on our theoretical analysis, in which we additionally minimize the maximum model discrepancy(M3D) of the substitute models when training the generator to generate adversarial examples. In this way, our model is capable of crafting highly transferable adversarial examples that are robust to the model variation, thus improving the success rate for attacking the black-box model. We conduct extensive experiments on the ImageNet dataset with different classification models, and our proposed approach outperforms existing state-of-the-art methods by a significant margin. Our codes will be released.
Undoing the Damage of Label Shift for Cross-domain Semantic Segmentation
Apr 12, 2022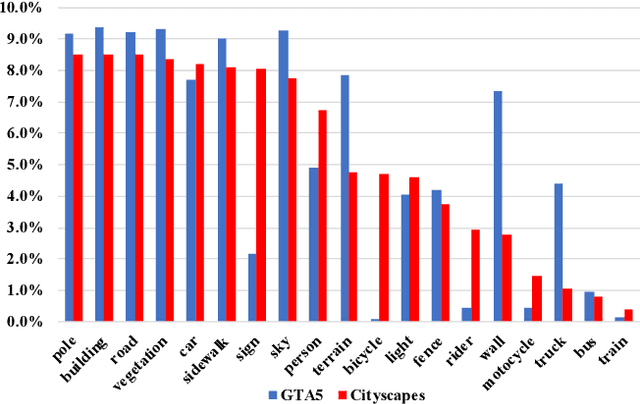
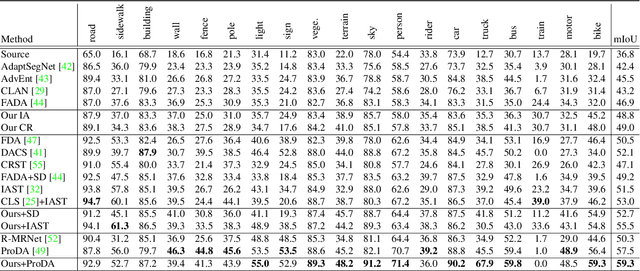
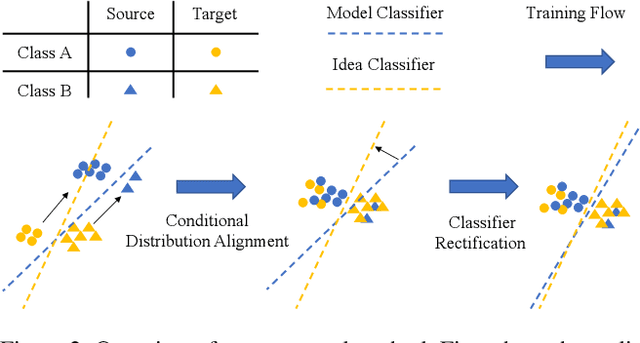
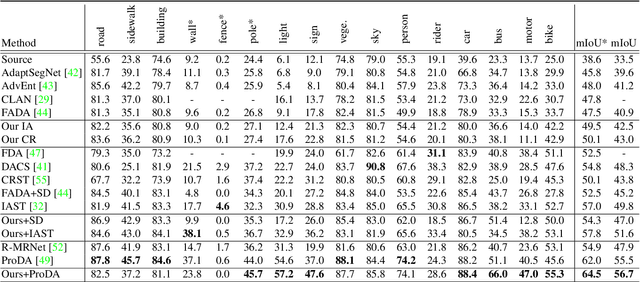
Existing works typically treat cross-domain semantic segmentation (CDSS) as a data distribution mismatch problem and focus on aligning the marginal distribution or conditional distribution. However, the label shift issue is unfortunately overlooked, which actually commonly exists in the CDSS task, and often causes a classifier bias in the learnt model. In this paper, we give an in-depth analysis and show that the damage of label shift can be overcome by aligning the data conditional distribution and correcting the posterior probability. To this end, we propose a novel approach to undo the damage of the label shift problem in CDSS. In implementation, we adopt class-level feature alignment for conditional distribution alignment, as well as two simple yet effective methods to rectify the classifier bias from source to target by remolding the classifier predictions. We conduct extensive experiments on the benchmark datasets of urban scenes, including GTA5 to Cityscapes and SYNTHIA to Cityscapes, where our proposed approach outperforms previous methods by a large margin. For instance, our model equipped with a self-training strategy reaches 59.3% mIoU on GTA5 to Cityscapes, pushing to a new state-of-the-art. The code will be available at https://github.com/manmanjun/Undoing UDA.