 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOccTransformer: Improving BEVFormer for 3D camera-only occupancy prediction
Feb 28, 2024
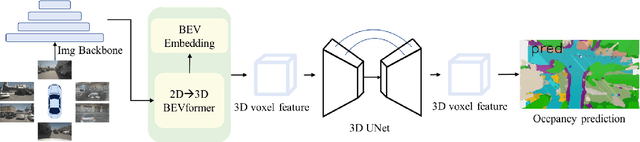

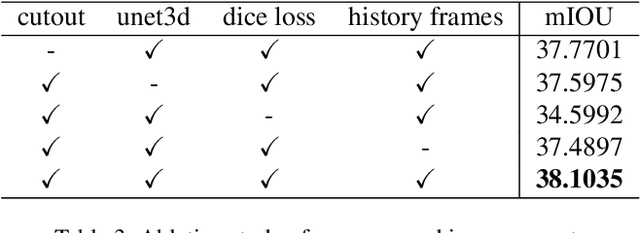
This technical report presents our solution, "occTransformer" for the 3D occupancy prediction track in the autonomous driving challenge at CVPR 2023. Our method builds upon the strong baseline BEVFormer and improves its performance through several simple yet effective techniques. Firstly, we employed data augmentation to increase the diversity of the training data and improve the model's generalization ability. Secondly, we used a strong image backbone to extract more informative features from the input data. Thirdly, we incorporated a 3D unet head to better capture the spatial information of the scene. Fourthly, we added more loss functions to better optimize the model. Additionally, we used an ensemble approach with the occ model BevDet and SurroundOcc to further improve the performance. Most importantly, we integrated 3D detection model StreamPETR to enhance the model's ability to detect objects in the scene. Using these methods, our solution achieved 49.23 miou on the 3D occupancy prediction track in the autonomous driving challenge.
Motion and Appearance Adaptation for Cross-Domain Motion Transfer
Oct 06, 2022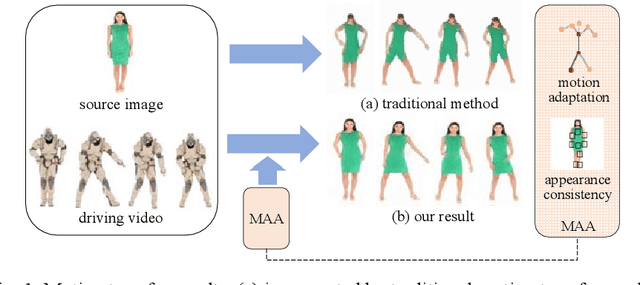
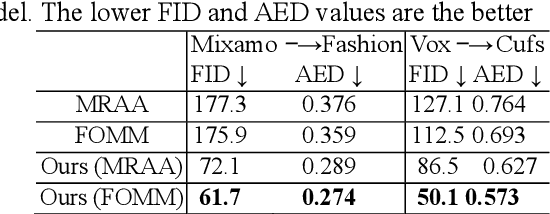
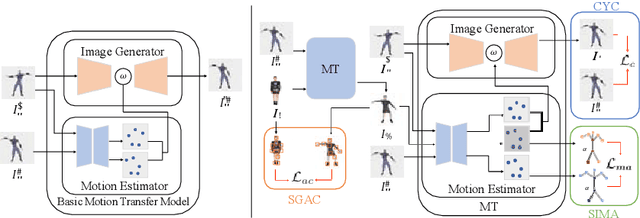
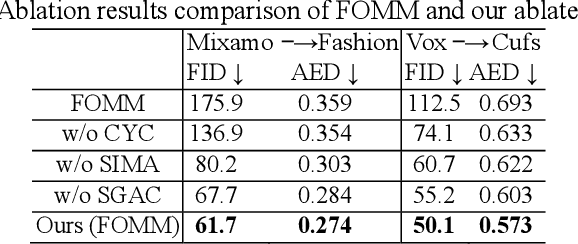
Motion transfer aims to transfer the motion of a driving video to a source image. When there are considerable differences between object in the driving video and that in the source image, traditional single domain motion transfer approaches often produce notable artifacts; for example, the synthesized image may fail to preserve the human shape of the source image (cf . Fig. 1 (a)). To address this issue, in this work, we propose a Motion and Appearance Adaptation (MAA) approach for cross-domain motion transfer, in which we regularize the object in the synthesized image to capture the motion of the object in the driving frame, while still preserving the shape and appearance of the object in the source image. On one hand, considering the object shapes of the synthesized image and the driving frame might be different, we design a shape-invariant motion adaptation module that enforces the consistency of the angles of object parts in two images to capture the motion information. On the other hand, we introduce a structure-guided appearance consistency module designed to regularize the similarity between the corresponding patches of the synthesized image and the source image without affecting the learned motion in the synthesized image. Our proposed MAA model can be trained in an end-to-end manner with a cyclic reconstruction loss, and ultimately produces a satisfactory motion transfer result (cf . Fig. 1 (b)). We conduct extensive experiments on human dancing dataset Mixamo-Video to Fashion-Video and human face dataset Vox-Celeb to Cufs; on both of these, our MAA model outperforms existing methods both quantitatively and qualitatively.
Structure-Aware Motion Transfer with Deformable Anchor Model
Apr 11, 2022
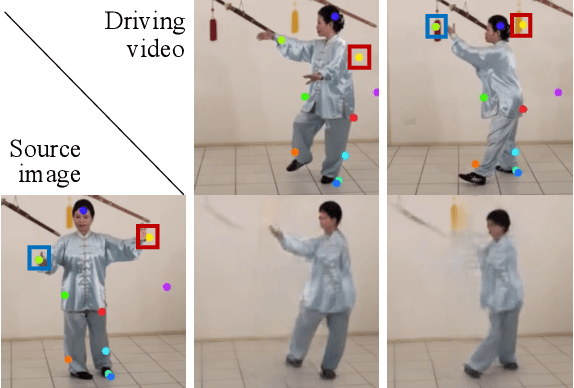

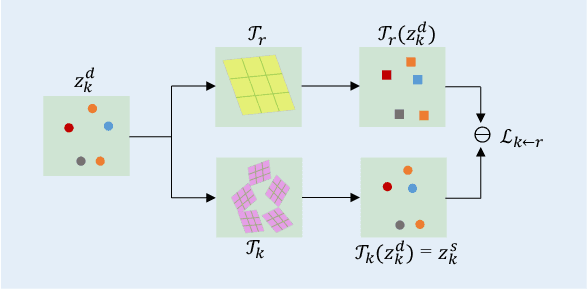
Given a source image and a driving video depicting the same object type, the motion transfer task aims to generate a video by learning the motion from the driving video while preserving the appearance from the source image. In this paper, we propose a novel structure-aware motion modeling approach, the deformable anchor model (DAM), which can automatically discover the motion structure of arbitrary objects without leveraging their prior structure information. Specifically, inspired by the known deformable part model (DPM), our DAM introduces two types of anchors or keypoints: i) a number of motion anchors that capture both appearance and motion information from the source image and driving video; ii) a latent root anchor, which is linked to the motion anchors to facilitate better learning of the representations of the object structure information. Moreover, DAM can be further extended to a hierarchical version through the introduction of additional latent anchors to model more complicated structures. By regularizing motion anchors with latent anchor(s), DAM enforces the correspondences between them to ensure the structural information is well captured and preserved. Moreover, DAM can be learned effectively in an unsupervised manner. We validate our proposed DAM for motion transfer on different benchmark datasets. Extensive experiments clearly demonstrate that DAM achieves superior performance relative to existing state-of-the-art methods.
Move As You Like: Image Animation in E-Commerce Scenario
Dec 19, 2021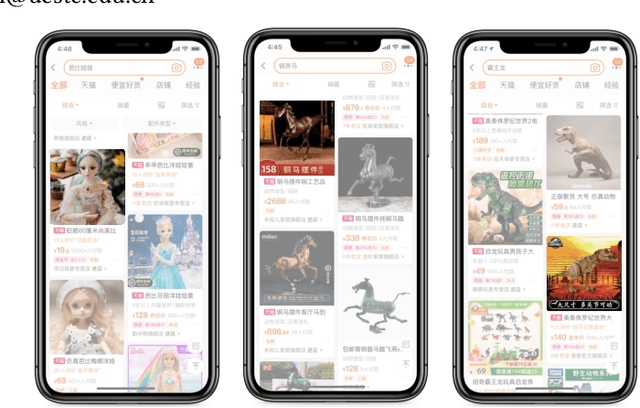
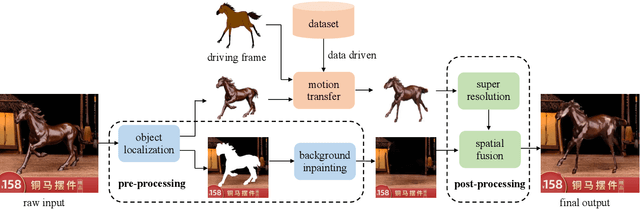

Creative image animations are attractive in e-commerce applications, where motion transfer is one of the import ways to generate animations from static images. However, existing methods rarely transfer motion to objects other than human body or human face, and even fewer apply motion transfer in practical scenarios. In this work, we apply motion transfer on the Taobao product images in real e-commerce scenario to generate creative animations, which are more attractive than static images and they will bring more benefits. We animate the Taobao products of dolls, copper running horses and toy dinosaurs based on motion transfer method for demonstration.
* 3 pages, 3 figures, ACM MM 2021 demo session