 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocus-Scan-Refine: From Human Visual Perception to Efficient Visual Token Pruning
Feb 05, 2026Vision-language models (VLMs) often generate massive visual tokens that greatly increase inference latency and memory footprint; while training-free token pruning offers a practical remedy, existing methods still struggle to balance local evidence and global context under aggressive compression. We propose Focus-Scan-Refine (FSR), a human-inspired, plug-and-play pruning framework that mimics how humans answer visual questions: focus on key evidence, then scan globally if needed, and refine the scanned context by aggregating relevant details. FSR first focuses on key evidence by combining visual importance with instruction relevance, avoiding the bias toward visually salient but query-irrelevant regions. It then scans for complementary context conditioned on the focused set, selecting tokens that are most different from the focused evidence. Finally, FSR refines the scanned context by aggregating nearby informative tokens into the scan anchors via similarity-based assignment and score-weighted merging, without increasing the token budget. Extensive experiments across multiple VLM backbones and vision-language benchmarks show that FSR consistently improves the accuracy-efficiency trade-off over existing state-of-the-art pruning methods. The source codes can be found at https://github.com/ILOT-code/FSR
EchoReview: Learning Peer Review from the Echoes of Scientific Citations
Jan 31, 2026As the volume of scientific submissions continues to grow rapidly, traditional peer review systems are facing unprecedented scalability pressures, highlighting the urgent need for automated reviewing methods that are both scalable and reliable. Existing supervised fine-tuning approaches based on real review data are fundamentally constrained by single-source of data as well as the inherent subjectivity and inconsistency of human reviews, limiting their ability to support high-quality automated reviewers. To address these issues, we propose EchoReview, a citation-context-driven data synthesis framework that systematically mines implicit collective evaluative signals from academic citations and transforms scientific community's long-term judgments into structured review-style data. Based on this pipeline, we construct EchoReview-16K, the first large-scale, cross-conference, and cross-year citation-driven review dataset, and train an automated reviewer, EchoReviewer-7B. Experimental results demonstrate that EchoReviewer-7B can achieve significant and stable improvements on core review dimensions such as evidence support and review comprehensiveness, validating citation context as a robust and effective data paradigm for reliable automated peer review.
UDPNet: Unleashing Depth-based Priors for Robust Image Dehazing
Jan 11, 2026Image dehazing has witnessed significant advancements with the development of deep learning models. However, a few methods predominantly focus on single-modal RGB features, neglecting the inherent correlation between scene depth and haze distribution. Even those that jointly optimize depth estimation and image dehazing often suffer from suboptimal performance due to inadequate utilization of accurate depth information. In this paper, we present UDPNet, a general framework that leverages depth-based priors from large-scale pretrained depth estimation model DepthAnything V2 to boost existing image dehazing models. Specifically, our architecture comprises two typical components: the Depth-Guided Attention Module (DGAM) adaptively modulates features via lightweight depth-guided channel attention, and the Depth Prior Fusion Module (DPFM) enables hierarchical fusion of multi-scale depth map features by dual sliding-window multi-head cross-attention mechanism. These modules ensure both computational efficiency and effective integration of depth priors. Moreover, the intrinsic robustness of depth priors empowers the network to dynamically adapt to varying haze densities, illumination conditions, and domain gaps across synthetic and real-world data. Extensive experimental results demonstrate the effectiveness of our UDPNet, outperforming the state-of-the-art methods on popular dehazing datasets, such as 0.85 dB PSNR improvement on the SOTS dataset, 1.19 dB on the Haze4K dataset and 1.79 dB PSNR on the NHR dataset. Our proposed solution establishes a new benchmark for depth-aware dehazing across various scenarios. Pretrained models and codes will be released at our project https://github.com/Harbinzzy/UDPNet.
FutureX: Enhance End-to-End Autonomous Driving via Latent Chain-of-Thought World Model
Dec 12, 2025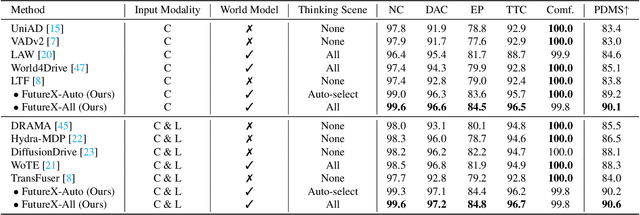
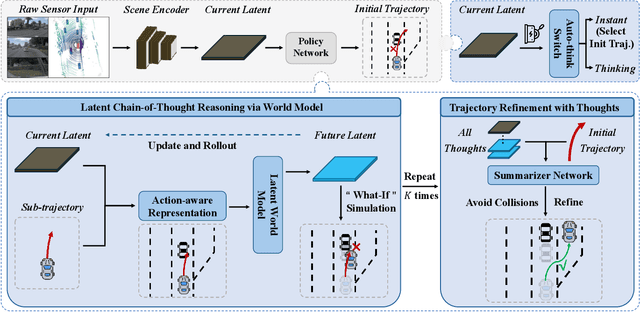

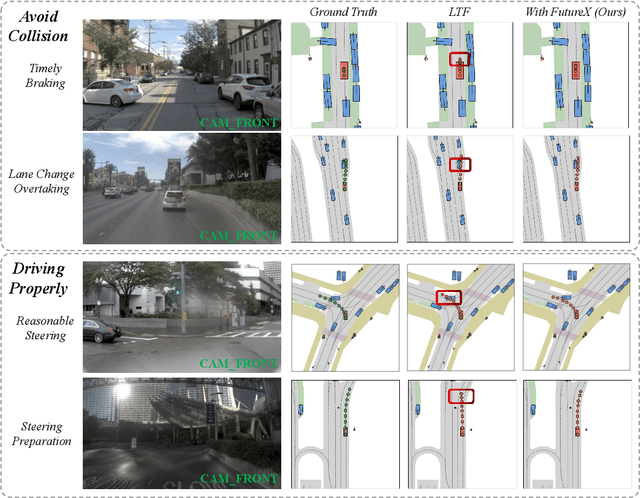
In autonomous driving, end-to-end planners learn scene representations from raw sensor data and utilize them to generate a motion plan or control actions. However, exclusive reliance on the current scene for motion planning may result in suboptimal responses in highly dynamic traffic environments where ego actions further alter the future scene. To model the evolution of future scenes, we leverage the World Model to represent how the ego vehicle and its environment interact and change over time, which entails complex reasoning. The Chain of Thought (CoT) offers a promising solution by forecasting a sequence of future thoughts that subsequently guide trajectory refinement. In this paper, we propose FutureX, a CoT-driven pipeline that enhances end-to-end planners to perform complex motion planning via future scene latent reasoning and trajectory refinement. Specifically, the Auto-think Switch examines the current scene and decides whether additional reasoning is required to yield a higher-quality motion plan. Once FutureX enters the Thinking mode, the Latent World Model conducts a CoT-guided rollout to predict future scene representation, enabling the Summarizer Module to further refine the motion plan. Otherwise, FutureX operates in an Instant mode to generate motion plans in a forward pass for relatively simple scenes. Extensive experiments demonstrate that FutureX enhances existing methods by producing more rational motion plans and fewer collisions without compromising efficiency, thereby achieving substantial overall performance gains, e.g., 6.2 PDMS improvement for TransFuser on NAVSIM. Code will be released.
Semantics and Content Matter: Towards Multi-Prior Hierarchical Mamba for Image Deraining
Nov 17, 2025Rain significantly degrades the performance of computer vision systems, particularly in applications like autonomous driving and video surveillance. While existing deraining methods have made considerable progress, they often struggle with fidelity of semantic and spatial details. To address these limitations, we propose the Multi-Prior Hierarchical Mamba (MPHM) network for image deraining. This novel architecture synergistically integrates macro-semantic textual priors (CLIP) for task-level semantic guidance and micro-structural visual priors (DINOv2) for scene-aware structural information. To alleviate potential conflicts between heterogeneous priors, we devise a progressive Priors Fusion Injection (PFI) that strategically injects complementary cues at different decoder levels. Meanwhile, we equip the backbone network with an elaborate Hierarchical Mamba Module (HMM) to facilitate robust feature representation, featuring a Fourier-enhanced dual-path design that concurrently addresses global context modeling and local detail recovery. Comprehensive experiments demonstrate MPHM's state-of-the-art performance, achieving a 0.57 dB PSNR gain on the Rain200H dataset while delivering superior generalization on real-world rainy scenarios.
Variation-Bounded Loss for Noise-Tolerant Learning
Nov 15, 2025Mitigating the negative impact of noisy labels has been aperennial issue in supervised learning. Robust loss functions have emerged as a prevalent solution to this problem. In this work, we introduce the Variation Ratio as a novel property related to the robustness of loss functions, and propose a new family of robust loss functions, termed Variation-Bounded Loss (VBL), which is characterized by a bounded variation ratio. We provide theoretical analyses of the variation ratio, proving that a smaller variation ratio would lead to better robustness. Furthermore, we reveal that the variation ratio provides a feasible method to relax the symmetric condition and offers a more concise path to achieve the asymmetric condition. Based on the variation ratio, we reformulate several commonly used loss functions into a variation-bounded form for practical applications. Positive experiments on various datasets exhibit the effectiveness and flexibility of our approach.
Rethinking Autoregressive Models for Lossless Image Compression via Hierarchical Parallelism and Progressive Adaptation
Nov 14, 2025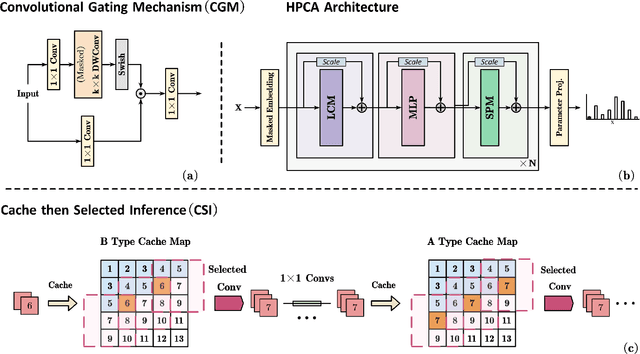
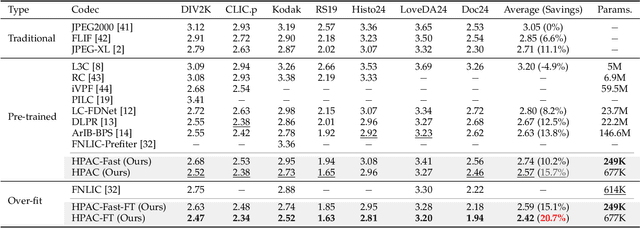
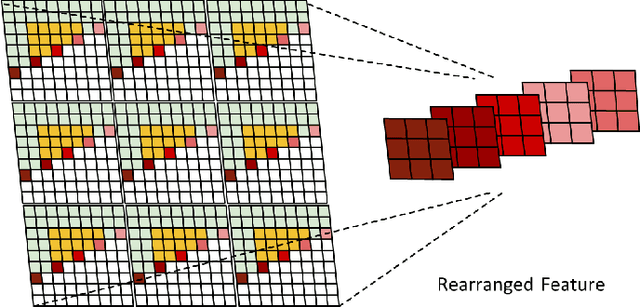
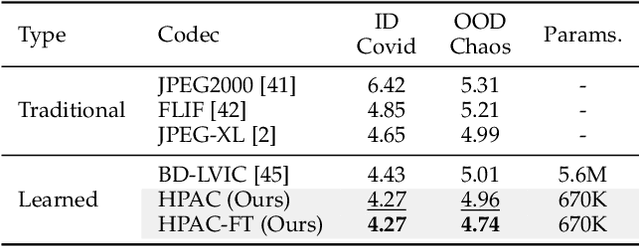
Autoregressive (AR) models, the theoretical performance benchmark for learned lossless image compression, are often dismissed as impractical due to prohibitive computational cost. This work re-thinks this paradigm, introducing a framework built on hierarchical parallelism and progressive adaptation that re-establishes pure autoregression as a top-performing and practical solution. Our approach is embodied in the Hierarchical Parallel Autoregressive ConvNet (HPAC), an ultra-lightweight pre-trained model using a hierarchical factorized structure and content-aware convolutional gating to efficiently capture spatial dependencies. We introduce two key optimizations for practicality: Cache-then-Select Inference (CSI), which accelerates coding by eliminating redundant computations, and Adaptive Focus Coding (AFC), which efficiently extends the framework to high bit-depth images. Building on this efficient foundation, our progressive adaptation strategy is realized by Spatially-Aware Rate-Guided Progressive Fine-tuning (SARP-FT). This instance-level strategy fine-tunes the model for each test image by optimizing low-rank adapters on progressively larger, spatially-continuous regions selected via estimated information density. Experiments on diverse datasets (natural, satellite, medical) validate that our method achieves new state-of-the-art compression. Notably, our approach sets a new benchmark in learned lossless compression, showing a carefully designed AR framework can offer significant gains over existing methods with a small parameter count and competitive coding speeds.
Joint Asymmetric Loss for Learning with Noisy Labels
Jul 23, 2025Learning with noisy labels is a crucial task for training accurate deep neural networks. To mitigate label noise, prior studies have proposed various robust loss functions, particularly symmetric losses. Nevertheless, symmetric losses usually suffer from the underfitting issue due to the overly strict constraint. To address this problem, the Active Passive Loss (APL) jointly optimizes an active and a passive loss to mutually enhance the overall fitting ability. Within APL, symmetric losses have been successfully extended, yielding advanced robust loss functions. Despite these advancements, emerging theoretical analyses indicate that asymmetric losses, a new class of robust loss functions, possess superior properties compared to symmetric losses. However, existing asymmetric losses are not compatible with advanced optimization frameworks such as APL, limiting their potential and applicability. Motivated by this theoretical gap and the prospect of asymmetric losses, we extend the asymmetric loss to the more complex passive loss scenario and propose the Asymetric Mean Square Error (AMSE), a novel asymmetric loss. We rigorously establish the necessary and sufficient condition under which AMSE satisfies the asymmetric condition. By substituting the traditional symmetric passive loss in APL with our proposed AMSE, we introduce a novel robust loss framework termed Joint Asymmetric Loss (JAL). Extensive experiments demonstrate the effectiveness of our method in mitigating label noise. Code available at: https://github.com/cswjl/joint-asymmetric-loss
Boosting All-in-One Image Restoration via Self-Improved Privilege Learning
May 30, 2025Unified image restoration models for diverse and mixed degradations often suffer from unstable optimization dynamics and inter-task conflicts. This paper introduces Self-Improved Privilege Learning (SIPL), a novel paradigm that overcomes these limitations by innovatively extending the utility of privileged information (PI) beyond training into the inference stage. Unlike conventional Privilege Learning, where ground-truth-derived guidance is typically discarded after training, SIPL empowers the model to leverage its own preliminary outputs as pseudo-privileged signals for iterative self-refinement at test time. Central to SIPL is Proxy Fusion, a lightweight module incorporating a learnable Privileged Dictionary. During training, this dictionary distills essential high-frequency and structural priors from privileged feature representations. Critically, at inference, the same learned dictionary then interacts with features derived from the model's initial restoration, facilitating a self-correction loop. SIPL can be seamlessly integrated into various backbone architectures, offering substantial performance improvements with minimal computational overhead. Extensive experiments demonstrate that SIPL significantly advances the state-of-the-art on diverse all-in-one image restoration benchmarks. For instance, when integrated with the PromptIR model, SIPL achieves remarkable PSNR improvements of +4.58 dB on composite degradation tasks and +1.28 dB on diverse five-task benchmarks, underscoring its effectiveness and broad applicability. Codes are available at our project page https://github.com/Aitical/SIPL.
The Fourth Monocular Depth Estimation Challenge
Apr 24, 2025


This paper presents the results of the fourth edition of the Monocular Depth Estimation Challenge (MDEC), which focuses on zero-shot generalization to the SYNS-Patches benchmark, a dataset featuring challenging environments in both natural and indoor settings. In this edition, we revised the evaluation protocol to use least-squares alignment with two degrees of freedom to support disparity and affine-invariant predictions. We also revised the baselines and included popular off-the-shelf methods: Depth Anything v2 and Marigold. The challenge received a total of 24 submissions that outperformed the baselines on the test set; 10 of these included a report describing their approach, with most leading methods relying on affine-invariant predictions. The challenge winners improved the 3D F-Score over the previous edition's best result, raising it from 22.58% to 23.05%.