 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDPL: Depth-only Perceptive Humanoid Locomotion via Realistic Depth Synthesis and Cross-Attention Terrain Reconstruction
Oct 08, 2025Recent advancements in legged robot perceptive locomotion have shown promising progress. However, terrain-aware humanoid locomotion remains largely constrained to two paradigms: depth image-based end-to-end learning and elevation map-based methods. The former suffers from limited training efficiency and a significant sim-to-real gap in depth perception, while the latter depends heavily on multiple vision sensors and localization systems, resulting in latency and reduced robustness. To overcome these challenges, we propose a novel framework that tightly integrates three key components: (1) Terrain-Aware Locomotion Policy with a Blind Backbone, which leverages pre-trained elevation map-based perception to guide reinforcement learning with minimal visual input; (2) Multi-Modality Cross-Attention Transformer, which reconstructs structured terrain representations from noisy depth images; (3) Realistic Depth Images Synthetic Method, which employs self-occlusion-aware ray casting and noise-aware modeling to synthesize realistic depth observations, achieving over 30\% reduction in terrain reconstruction error. This combination enables efficient policy training with limited data and hardware resources, while preserving critical terrain features essential for generalization. We validate our framework on a full-sized humanoid robot, demonstrating agile and adaptive locomotion across diverse and challenging terrains.
Humanoid Occupancy: Enabling A Generalized Multimodal Occupancy Perception System on Humanoid Robots
Jul 27, 2025Humanoid robot technology is advancing rapidly, with manufacturers introducing diverse heterogeneous visual perception modules tailored to specific scenarios. Among various perception paradigms, occupancy-based representation has become widely recognized as particularly suitable for humanoid robots, as it provides both rich semantic and 3D geometric information essential for comprehensive environmental understanding. In this work, we present Humanoid Occupancy, a generalized multimodal occupancy perception system that integrates hardware and software components, data acquisition devices, and a dedicated annotation pipeline. Our framework employs advanced multi-modal fusion techniques to generate grid-based occupancy outputs encoding both occupancy status and semantic labels, thereby enabling holistic environmental understanding for downstream tasks such as task planning and navigation. To address the unique challenges of humanoid robots, we overcome issues such as kinematic interference and occlusion, and establish an effective sensor layout strategy. Furthermore, we have developed the first panoramic occupancy dataset specifically for humanoid robots, offering a valuable benchmark and resource for future research and development in this domain. The network architecture incorporates multi-modal feature fusion and temporal information integration to ensure robust perception. Overall, Humanoid Occupancy delivers effective environmental perception for humanoid robots and establishes a technical foundation for standardizing universal visual modules, paving the way for the widespread deployment of humanoid robots in complex real-world scenarios.
FUSE: Label-Free Image-Event Joint Monocular Depth Estimation via Frequency-Decoupled Alignment and Degradation-Robust Fusion
Mar 26, 2025Image-event joint depth estimation methods leverage complementary modalities for robust perception, yet face challenges in generalizability stemming from two factors: 1) limited annotated image-event-depth datasets causing insufficient cross-modal supervision, and 2) inherent frequency mismatches between static images and dynamic event streams with distinct spatiotemporal patterns, leading to ineffective feature fusion. To address this dual challenge, we propose Frequency-decoupled Unified Self-supervised Encoder (FUSE) with two synergistic components: The Parameter-efficient Self-supervised Transfer (PST) establishes cross-modal knowledge transfer through latent space alignment with image foundation models, effectively mitigating data scarcity by enabling joint encoding without depth ground truth. Complementing this, we propose the Frequency-Decoupled Fusion module (FreDFuse) to explicitly decouple high-frequency edge features from low-frequency structural components, resolving modality-specific frequency mismatches through physics-aware fusion. This combined approach enables FUSE to construct a universal image-event encoder that only requires lightweight decoder adaptation for target datasets. Extensive experiments demonstrate state-of-the-art performance with 14% and 24.9% improvements in Abs.Rel on MVSEC and DENSE datasets. The framework exhibits remarkable zero-shot adaptability to challenging scenarios including extreme lighting and motion blur, significantly advancing real-world deployment capabilities. The source code for our method is publicly available at: https://github.com/sunpihai-up/FUSE
The Third Monocular Depth Estimation Challenge
Apr 27, 2024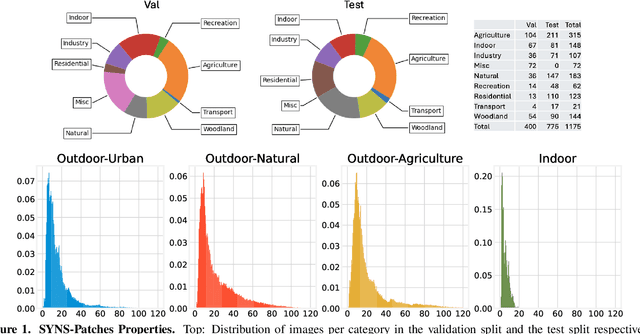

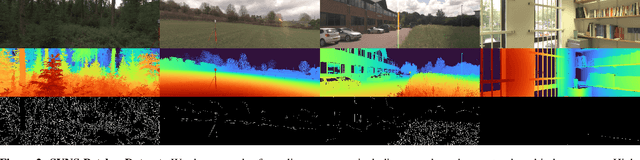
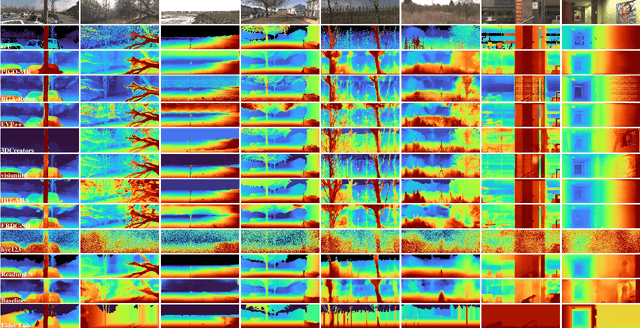
This paper discusses the results of the third edition of the Monocular Depth Estimation Challenge (MDEC). The challenge focuses on zero-shot generalization to the challenging SYNS-Patches dataset, featuring complex scenes in natural and indoor settings. As with the previous edition, methods can use any form of supervision, i.e. supervised or self-supervised. The challenge received a total of 19 submissions outperforming the baseline on the test set: 10 among them submitted a report describing their approach, highlighting a diffused use of foundational models such as Depth Anything at the core of their method. The challenge winners drastically improved 3D F-Score performance, from 17.51% to 23.72%.