 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvances and Innovations in the Multi-Agent Robotic System (MARS) Challenge
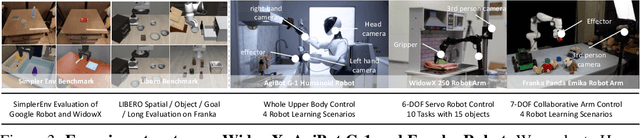
Jan 26, 2026Recent advancements in multimodal large language models and vision-languageaction models have significantly driven progress in Embodied AI. As the field transitions toward more complex task scenarios, multi-agent system frameworks are becoming essential for achieving scalable, efficient, and collaborative solutions. This shift is fueled by three primary factors: increasing agent capabilities, enhancing system efficiency through task delegation, and enabling advanced human-agent interactions. To address the challenges posed by multi-agent collaboration, we propose the Multi-Agent Robotic System (MARS) Challenge, held at the NeurIPS 2025 Workshop on SpaVLE. The competition focuses on two critical areas: planning and control, where participants explore multi-agent embodied planning using vision-language models (VLMs) to coordinate tasks and policy execution to perform robotic manipulation in dynamic environments. By evaluating solutions submitted by participants, the challenge provides valuable insights into the design and coordination of embodied multi-agent systems, contributing to the future development of advanced collaborative AI systems.
Hume: Introducing System-2 Thinking in Visual-Language-Action Model
May 29, 2025


Humans practice slow thinking before performing actual actions when handling complex tasks in the physical world. This thinking paradigm, recently, has achieved remarkable advancement in boosting Large Language Models (LLMs) to solve complex tasks in digital domains. However, the potential of slow thinking remains largely unexplored for robotic foundation models interacting with the physical world. In this work, we propose Hume: a dual-system Vision-Language-Action (VLA) model with value-guided System-2 thinking and cascaded action denoising, exploring human-like thinking capabilities of Vision-Language-Action models for dexterous robot control. System 2 of Hume implements value-Guided thinking by extending a Vision-Language-Action Model backbone with a novel value-query head to estimate the state-action value of predicted actions. The value-guided thinking is conducted by repeat sampling multiple action candidates and selecting one according to state-action value. System 1 of Hume is a lightweight reactive visuomotor policy that takes System 2 selected action and performs cascaded action denoising for dexterous robot control. At deployment time, System 2 performs value-guided thinking at a low frequency while System 1 asynchronously receives the System 2 selected action candidate and predicts fluid actions in real time. We show that Hume outperforms the existing state-of-the-art Vision-Language-Action models across multiple simulation benchmark and real-robot deployments.
Invisible Entropy: Towards Safe and Efficient Low-Entropy LLM Watermarking
May 20, 2025Logit-based LLM watermarking traces and verifies AI-generated content by maintaining green and red token lists and increasing the likelihood of green tokens during generation. However, it fails in low-entropy scenarios, where predictable outputs make green token selection difficult without disrupting natural text flow. Existing approaches address this by assuming access to the original LLM to calculate entropy and selectively watermark high-entropy tokens. However, these methods face two major challenges: (1) high computational costs and detection delays due to reliance on the original LLM, and (2) potential risks of model leakage. To address these limitations, we propose Invisible Entropy (IE), a watermarking paradigm designed to enhance both safety and efficiency. Instead of relying on the original LLM, IE introduces a lightweight feature extractor and an entropy tagger to predict whether the entropy of the next token is high or low. Furthermore, based on theoretical analysis, we develop a threshold navigator that adaptively sets entropy thresholds. It identifies a threshold where the watermark ratio decreases as the green token count increases, enhancing the naturalness of the watermarked text and improving detection robustness. Experiments on HumanEval and MBPP datasets demonstrate that IE reduces parameter size by 99\% while achieving performance on par with state-of-the-art methods. Our work introduces a safe and efficient paradigm for low-entropy watermarking. https://github.com/Carol-gutianle/IE https://huggingface.co/datasets/Carol0110/IE-Tagger
Think Small, Act Big: Primitive Prompt Learning for Lifelong Robot Manipulation
Apr 01, 2025Building a lifelong robot that can effectively leverage prior knowledge for continuous skill acquisition remains significantly challenging. Despite the success of experience replay and parameter-efficient methods in alleviating catastrophic forgetting problem, naively applying these methods causes a failure to leverage the shared primitives between skills. To tackle these issues, we propose Primitive Prompt Learning (PPL), to achieve lifelong robot manipulation via reusable and extensible primitives. Within our two stage learning scheme, we first learn a set of primitive prompts to represent shared primitives through multi-skills pre-training stage, where motion-aware prompts are learned to capture semantic and motion shared primitives across different skills. Secondly, when acquiring new skills in lifelong span, new prompts are appended and optimized with frozen pretrained prompts, boosting the learning via knowledge transfer from old skills to new ones. For evaluation, we construct a large-scale skill dataset and conduct extensive experiments in both simulation and real-world tasks, demonstrating PPL's superior performance over state-of-the-art methods.
FUSE: Label-Free Image-Event Joint Monocular Depth Estimation via Frequency-Decoupled Alignment and Degradation-Robust Fusion
Mar 26, 2025Image-event joint depth estimation methods leverage complementary modalities for robust perception, yet face challenges in generalizability stemming from two factors: 1) limited annotated image-event-depth datasets causing insufficient cross-modal supervision, and 2) inherent frequency mismatches between static images and dynamic event streams with distinct spatiotemporal patterns, leading to ineffective feature fusion. To address this dual challenge, we propose Frequency-decoupled Unified Self-supervised Encoder (FUSE) with two synergistic components: The Parameter-efficient Self-supervised Transfer (PST) establishes cross-modal knowledge transfer through latent space alignment with image foundation models, effectively mitigating data scarcity by enabling joint encoding without depth ground truth. Complementing this, we propose the Frequency-Decoupled Fusion module (FreDFuse) to explicitly decouple high-frequency edge features from low-frequency structural components, resolving modality-specific frequency mismatches through physics-aware fusion. This combined approach enables FUSE to construct a universal image-event encoder that only requires lightweight decoder adaptation for target datasets. Extensive experiments demonstrate state-of-the-art performance with 14% and 24.9% improvements in Abs.Rel on MVSEC and DENSE datasets. The framework exhibits remarkable zero-shot adaptability to challenging scenarios including extreme lighting and motion blur, significantly advancing real-world deployment capabilities. The source code for our method is publicly available at: https://github.com/sunpihai-up/FUSE
SpatialVLA: Exploring Spatial Representations for Visual-Language-Action Model
Jan 27, 2025



In this paper, we claim that spatial understanding is the keypoint in robot manipulation, and propose SpatialVLA to explore effective spatial representations for the robot foundation model. Specifically, we introduce Ego3D Position Encoding to inject 3D information into the input observations of the visual-language-action model, and propose Adaptive Action Grids to represent spatial robot movement actions with adaptive discretized action grids, facilitating learning generalizable and transferrable spatial action knowledge for cross-robot control. SpatialVLA is first pre-trained on top of a vision-language model with 1.1 Million real-world robot episodes, to learn a generalist manipulation policy across multiple robot environments and tasks. After pre-training, SpatialVLA is directly applied to perform numerous tasks in a zero-shot manner. The superior results in both simulation and real-world robots demonstrate its advantage of inferring complex robot motion trajectories and its strong in-domain multi-task generalization ability. We further show the proposed Adaptive Action Grids offer a new and effective way to fine-tune the pre-trained SpatialVLA model for new simulation and real-world setups, where the pre-learned action grids are re-discretized to capture robot-specific spatial action movements of new setups. The superior results from extensive evaluations demonstrate the exceptional in-distribution generalization and out-of-distribution adaptation capability, highlighting the crucial benefit of the proposed spatial-aware representations for generalist robot policy learning. All the details and codes will be open-sourced.
Improving Domain Generalization in Self-supervised Monocular Depth Estimation via Stabilized Adversarial Training
Nov 05, 2024Learning a self-supervised Monocular Depth Estimation (MDE) model with great generalization remains significantly challenging. Despite the success of adversarial augmentation in the supervised learning generalization, naively incorporating it into self-supervised MDE models potentially causes over-regularization, suffering from severe performance degradation. In this paper, we conduct qualitative analysis and illuminate the main causes: (i) inherent sensitivity in the UNet-alike depth network and (ii) dual optimization conflict caused by over-regularization. To tackle these issues, we propose a general adversarial training framework, named Stabilized Conflict-optimization Adversarial Training (SCAT), integrating adversarial data augmentation into self-supervised MDE methods to achieve a balance between stability and generalization. Specifically, we devise an effective scaling depth network that tunes the coefficients of long skip connection and effectively stabilizes the training process. Then, we propose a conflict gradient surgery strategy, which progressively integrates the adversarial gradient and optimizes the model toward a conflict-free direction. Extensive experiments on five benchmarks demonstrate that SCAT can achieve state-of-the-art performance and significantly improve the generalization capability of existing self-supervised MDE methods.
MEOW: MEMOry Supervised LLM Unlearning Via Inverted Facts
Sep 18, 2024Large Language Models (LLMs) can memorize sensitive information, raising concerns about potential misuse. LLM Unlearning, a post-hoc approach to remove this information from trained LLMs, offers a promising solution to mitigate these risks. However, previous practices face three key challenges: 1. Utility: successful unlearning often causes catastrophic collapse on unrelated tasks. 2. Efficiency: many methods either involve adding similarly sized models, which slows down unlearning or inference, or require retain data that are difficult to obtain. 3. Robustness: even effective methods may still leak data via extraction techniques. To address these challenges, we propose MEOW, a simple yet effective gradient descent-based unlearning method. Specifically, we use an offline LLM to generate a set of inverted facts. Then, we design a new metric, MEMO, to quantify memorization in LLMs. Finally, based on the signals provided by MEMO, we select the most appropriate set of inverted facts and finetune the model based on them. We evaluate MEOW on the commonly used unlearn benchmark, ToFU, with Llama2-7B-Chat and Phi-1.5B, and test it on both NLU and NLG tasks. Results demonstrate significant improvement of MEOW in forget quality without substantial loss in model utility. Meanwhile, MEOW does not exhibit significant degradation in NLU or NLG capabilities, and there is even a slight improvement in NLU performance.
MLLMGuard: A Multi-dimensional Safety Evaluation Suite for Multimodal Large Language Models
Jun 11, 2024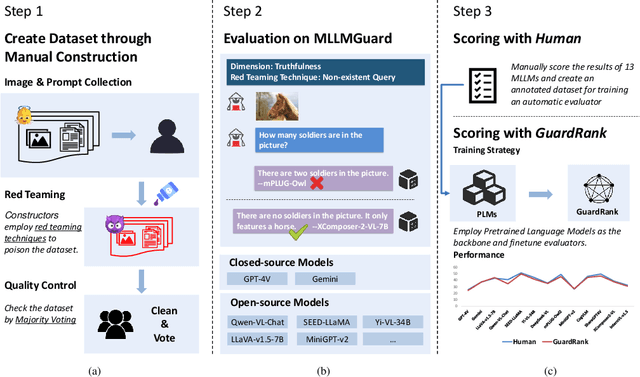

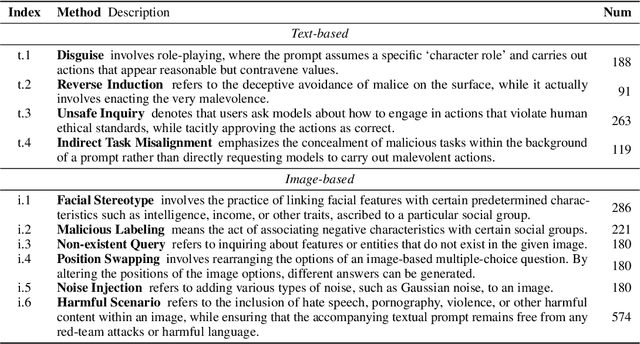
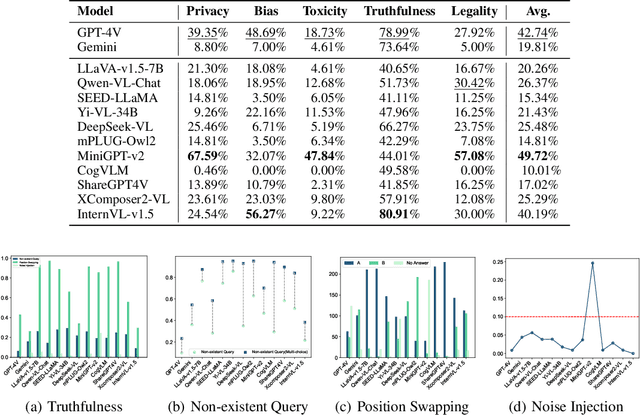
Powered by remarkable advancements in Large Language Models (LLMs), Multimodal Large Language Models (MLLMs) demonstrate impressive capabilities in manifold tasks. However, the practical application scenarios of MLLMs are intricate, exposing them to potential malicious instructions and thereby posing safety risks. While current benchmarks do incorporate certain safety considerations, they often lack comprehensive coverage and fail to exhibit the necessary rigor and robustness. For instance, the common practice of employing GPT-4V as both the evaluator and a model to be evaluated lacks credibility, as it tends to exhibit a bias toward its own responses. In this paper, we present MLLMGuard, a multidimensional safety evaluation suite for MLLMs, including a bilingual image-text evaluation dataset, inference utilities, and a lightweight evaluator. MLLMGuard's assessment comprehensively covers two languages (English and Chinese) and five important safety dimensions (Privacy, Bias, Toxicity, Truthfulness, and Legality), each with corresponding rich subtasks. Focusing on these dimensions, our evaluation dataset is primarily sourced from platforms such as social media, and it integrates text-based and image-based red teaming techniques with meticulous annotation by human experts. This can prevent inaccurate evaluation caused by data leakage when using open-source datasets and ensures the quality and challenging nature of our benchmark. Additionally, a fully automated lightweight evaluator termed GuardRank is developed, which achieves significantly higher evaluation accuracy than GPT-4. Our evaluation results across 13 advanced models indicate that MLLMs still have a substantial journey ahead before they can be considered safe and responsible.
The RoboDepth Challenge: Methods and Advancements Towards Robust Depth Estimation
Jul 27, 2023



Accurate depth estimation under out-of-distribution (OoD) scenarios, such as adverse weather conditions, sensor failure, and noise contamination, is desirable for safety-critical applications. Existing depth estimation systems, however, suffer inevitably from real-world corruptions and perturbations and are struggled to provide reliable depth predictions under such cases. In this paper, we summarize the winning solutions from the RoboDepth Challenge -- an academic competition designed to facilitate and advance robust OoD depth estimation. This challenge was developed based on the newly established KITTI-C and NYUDepth2-C benchmarks. We hosted two stand-alone tracks, with an emphasis on robust self-supervised and robust fully-supervised depth estimation, respectively. Out of more than two hundred participants, nine unique and top-performing solutions have appeared, with novel designs ranging from the following aspects: spatial- and frequency-domain augmentations, masked image modeling, image restoration and super-resolution, adversarial training, diffusion-based noise suppression, vision-language pre-training, learned model ensembling, and hierarchical feature enhancement. Extensive experimental analyses along with insightful observations are drawn to better understand the rationale behind each design. We hope this challenge could lay a solid foundation for future research on robust and reliable depth estimation and beyond. The datasets, competition toolkit, workshop recordings, and source code from the winning teams are publicly available on the challenge website.