 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMove What Matters: Parameter-Efficient Domain Adaptation via Optimal Transport Flow for Collaborative Perception
Feb 12, 2026Fast domain adaptation remains a fundamental challenge for deploying multi-agent systems across diverse environments in Vehicle-to-Everything (V2X) collaborative perception. Despite the success of Parameter-Efficient Fine-Tuning (PEFT) in natural language processing and conventional vision tasks, directly applying PEFT to multi-agent settings leads to significant performance degradation and training instability. In this work, we conduct a detailed analysis and identify two key factors: (i) inter-frame redundancy in heterogeneous sensory streams, and (ii) erosion of fine-grained semantics in deep-layer representations under PEFT adaptation. To address these issues, we propose FlowAdapt, a parameter-efficient framework grounded in optimal transport theory, which minimizes information transport costs across both data distributions and network hierarchies. Specifically, we introduce a Wasserstein Greedy Sampling strategy to selectively filter redundant samples via a bounded covering radius. Furthermore, Progressive Knowledge Transfer module is designed to progressively inject compressed early-stage representations into later stages through learnable pathways, alleviating semantic degradation in late-stage adaptation. Extensive experiments on three benchmarks demonstrate that FlowAdapt achieves state-of-the-art performance with only 1% of trainable parameters, effectively bridging domain gaps with superior sample efficiency and generalization.
Modality Dominance-Aware Optimization for Embodied RGB-Infrared Perception
Jan 02, 2026RGB-Infrared (RGB-IR) multimodal perception is fundamental to embodied multimedia systems operating in complex physical environments. Although recent cross-modal fusion methods have advanced RGB-IR detection, the optimization dynamics caused by asymmetric modality characteristics remain underexplored. In practice, disparities in information density and feature quality introduce persistent optimization bias, leading training to overemphasize a dominant modality and hindering effective fusion. To quantify this phenomenon, we propose the Modality Dominance Index (MDI), which measures modality dominance by jointly modeling feature entropy and gradient contribution. Based on MDI, we develop a Modality Dominance-Aware Cross-modal Learning (MDACL) framework that regulates cross-modal optimization. MDACL incorporates Hierarchical Cross-modal Guidance (HCG) to enhance feature alignment and Adversarial Equilibrium Regularization (AER) to balance optimization dynamics during fusion. Extensive experiments on three RGB-IR benchmarks demonstrate that MDACL effectively mitigates optimization bias and achieves SOTA performance.
Think Small, Act Big: Primitive Prompt Learning for Lifelong Robot Manipulation
Apr 01, 2025Building a lifelong robot that can effectively leverage prior knowledge for continuous skill acquisition remains significantly challenging. Despite the success of experience replay and parameter-efficient methods in alleviating catastrophic forgetting problem, naively applying these methods causes a failure to leverage the shared primitives between skills. To tackle these issues, we propose Primitive Prompt Learning (PPL), to achieve lifelong robot manipulation via reusable and extensible primitives. Within our two stage learning scheme, we first learn a set of primitive prompts to represent shared primitives through multi-skills pre-training stage, where motion-aware prompts are learned to capture semantic and motion shared primitives across different skills. Secondly, when acquiring new skills in lifelong span, new prompts are appended and optimized with frozen pretrained prompts, boosting the learning via knowledge transfer from old skills to new ones. For evaluation, we construct a large-scale skill dataset and conduct extensive experiments in both simulation and real-world tasks, demonstrating PPL's superior performance over state-of-the-art methods.
Improving Domain Generalization in Self-supervised Monocular Depth Estimation via Stabilized Adversarial Training
Nov 05, 2024Learning a self-supervised Monocular Depth Estimation (MDE) model with great generalization remains significantly challenging. Despite the success of adversarial augmentation in the supervised learning generalization, naively incorporating it into self-supervised MDE models potentially causes over-regularization, suffering from severe performance degradation. In this paper, we conduct qualitative analysis and illuminate the main causes: (i) inherent sensitivity in the UNet-alike depth network and (ii) dual optimization conflict caused by over-regularization. To tackle these issues, we propose a general adversarial training framework, named Stabilized Conflict-optimization Adversarial Training (SCAT), integrating adversarial data augmentation into self-supervised MDE methods to achieve a balance between stability and generalization. Specifically, we devise an effective scaling depth network that tunes the coefficients of long skip connection and effectively stabilizes the training process. Then, we propose a conflict gradient surgery strategy, which progressively integrates the adversarial gradient and optimizes the model toward a conflict-free direction. Extensive experiments on five benchmarks demonstrate that SCAT can achieve state-of-the-art performance and significantly improve the generalization capability of existing self-supervised MDE methods.
De-confounded Data-free Knowledge Distillation for Handling Distribution Shifts
Mar 28, 2024



Data-Free Knowledge Distillation (DFKD) is a promising task to train high-performance small models to enhance actual deployment without relying on the original training data. Existing methods commonly avoid relying on private data by utilizing synthetic or sampled data. However, a long-overlooked issue is that the severe distribution shifts between their substitution and original data, which manifests as huge differences in the quality of images and class proportions. The harmful shifts are essentially the confounder that significantly causes performance bottlenecks. To tackle the issue, this paper proposes a novel perspective with causal inference to disentangle the student models from the impact of such shifts. By designing a customized causal graph, we first reveal the causalities among the variables in the DFKD task. Subsequently, we propose a Knowledge Distillation Causal Intervention (KDCI) framework based on the backdoor adjustment to de-confound the confounder. KDCI can be flexibly combined with most existing state-of-the-art baselines. Experiments in combination with six representative DFKD methods demonstrate the effectiveness of our KDCI, which can obviously help existing methods under almost all settings, \textit{e.g.}, improving the baseline by up to 15.54\% accuracy on the CIFAR-100 dataset.
Improving Generalization in Visual Reinforcement Learning via Conflict-aware Gradient Agreement Augmentation
Aug 02, 2023



Learning a policy with great generalization to unseen environments remains challenging but critical in visual reinforcement learning. Despite the success of augmentation combination in the supervised learning generalization, naively applying it to visual RL algorithms may damage the training efficiency, suffering from serve performance degradation. In this paper, we first conduct qualitative analysis and illuminate the main causes: (i) high-variance gradient magnitudes and (ii) gradient conflicts existed in various augmentation methods. To alleviate these issues, we propose a general policy gradient optimization framework, named Conflict-aware Gradient Agreement Augmentation (CG2A), and better integrate augmentation combination into visual RL algorithms to address the generalization bias. In particular, CG2A develops a Gradient Agreement Solver to adaptively balance the varying gradient magnitudes, and introduces a Soft Gradient Surgery strategy to alleviate the gradient conflicts. Extensive experiments demonstrate that CG2A significantly improves the generalization performance and sample efficiency of visual RL algorithms.
Sampling to Distill: Knowledge Transfer from Open-World Data
Jul 31, 2023Data-Free Knowledge Distillation (DFKD) is a novel task that aims to train high-performance student models using only the teacher network without original training data. Despite encouraging results, existing DFKD methods rely heavily on generation modules with high computational costs. Meanwhile, they ignore the fact that the generated and original data exist domain shifts due to the lack of supervision information. Moreover, knowledge is transferred through each example, ignoring the implicit relationship among multiple examples. To this end, we propose a novel Open-world Data Sampling Distillation (ODSD) method without a redundant generation process. First, we try to sample open-world data close to the original data's distribution by an adaptive sampling module. Then, we introduce a low-noise representation to alleviate the domain shifts and build a structured relationship of multiple data examples to exploit data knowledge. Extensive experiments on CIFAR-10, CIFAR-100, NYUv2, and ImageNet show that our ODSD method achieves state-of-the-art performance. Especially, we improve 1.50\%-9.59\% accuracy on the ImageNet dataset compared with the existing results.
Context De-confounded Emotion Recognition
Mar 26, 2023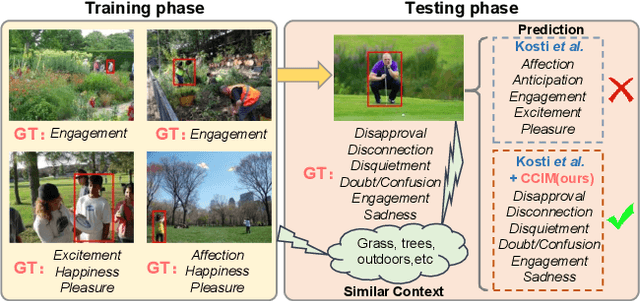
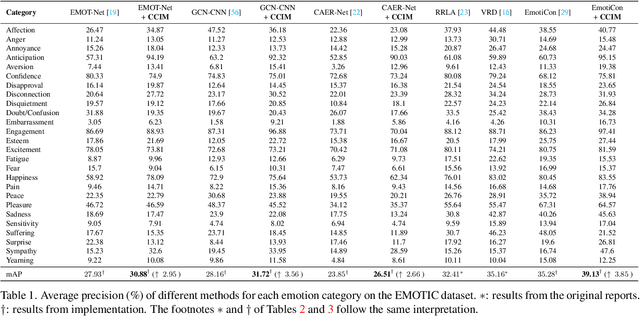
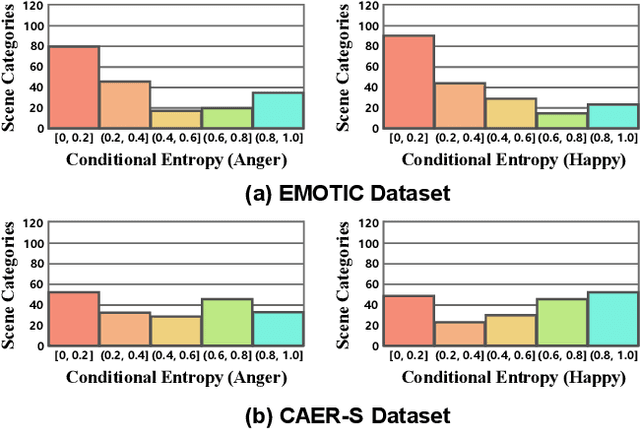

Context-Aware Emotion Recognition (CAER) is a crucial and challenging task that aims to perceive the emotional states of the target person with contextual information. Recent approaches invariably focus on designing sophisticated architectures or mechanisms to extract seemingly meaningful representations from subjects and contexts. However, a long-overlooked issue is that a context bias in existing datasets leads to a significantly unbalanced distribution of emotional states among different context scenarios. Concretely, the harmful bias is a confounder that misleads existing models to learn spurious correlations based on conventional likelihood estimation, significantly limiting the models' performance. To tackle the issue, this paper provides a causality-based perspective to disentangle the models from the impact of such bias, and formulate the causalities among variables in the CAER task via a tailored causal graph. Then, we propose a Contextual Causal Intervention Module (CCIM) based on the backdoor adjustment to de-confound the confounder and exploit the true causal effect for model training. CCIM is plug-in and model-agnostic, which improves diverse state-of-the-art approaches by considerable margins. Extensive experiments on three benchmark datasets demonstrate the effectiveness of our CCIM and the significance of causal insight.
Adversarial Contrastive Distillation with Adaptive Denoising
Feb 23, 2023


Adversarial Robustness Distillation (ARD) is a novel method to boost the robustness of small models. Unlike general adversarial training, its robust knowledge transfer can be less easily restricted by the model capacity. However, the teacher model that provides the robustness of knowledge does not always make correct predictions, interfering with the student's robust performances. Besides, in the previous ARD methods, the robustness comes entirely from one-to-one imitation, ignoring the relationship between examples. To this end, we propose a novel structured ARD method called Contrastive Relationship DeNoise Distillation (CRDND). We design an adaptive compensation module to model the instability of the teacher. Moreover, we utilize the contrastive relationship to explore implicit robustness knowledge among multiple examples. Experimental results on multiple attack benchmarks show CRDND can transfer robust knowledge efficiently and achieves state-of-the-art performances.
Efficient universal shuffle attack for visual object tracking
Mar 14, 2022
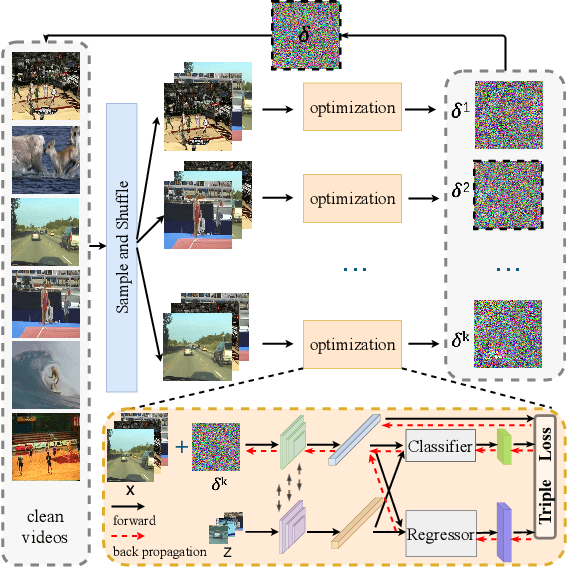
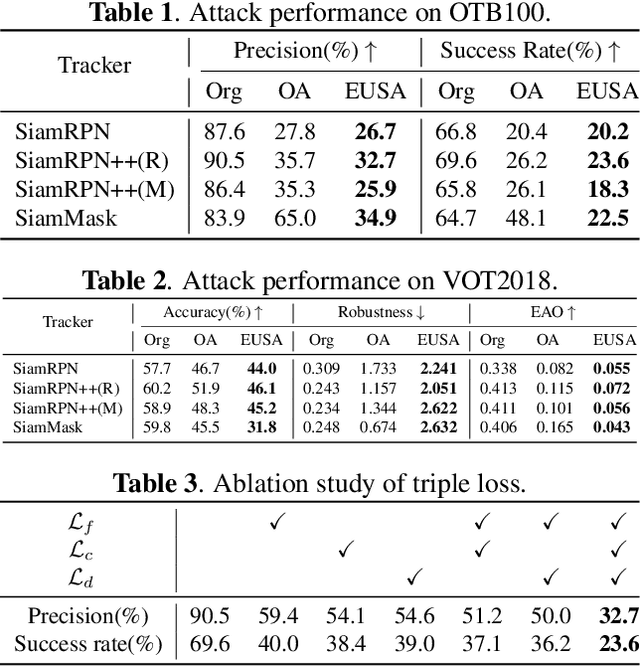
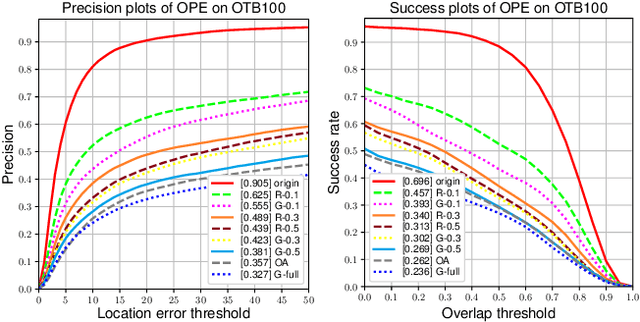
Recently, adversarial attacks have been applied in visual object tracking to deceive deep trackers by injecting imperceptible perturbations into video frames. However, previous work only generates the video-specific perturbations, which restricts its application scenarios. In addition, existing attacks are difficult to implement in reality due to the real-time of tracking and the re-initialization mechanism. To address these issues, we propose an offline universal adversarial attack called Efficient Universal Shuffle Attack. It takes only one perturbation to cause the tracker malfunction on all videos. To improve the computational efficiency and attack performance, we propose a greedy gradient strategy and a triple loss to efficiently capture and attack model-specific feature representations through the gradients. Experimental results show that EUSA can significantly reduce the performance of state-of-the-art trackers on OTB2015 and VOT2018.