 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaplace-Mixture Dipole Inversion for Quantitative Susceptibility Mapping
Jun 08, 2026Purpose: To develop an automatic dipole inversion method for quantitative susceptibility mapping (QSM) that preserves fine anatomical structures without the need for manual regularization-parameter tuning. Theory: The original approximate message passing with parameter estimation (AMP-PE) framework models image gradients with a single Laplace prior, which does not fully capture the heavy-tailed gradient distribution of brain susceptibility maps. This prior mismatch can lead to over-regularization and blocky reconstructions. We address this limitation by modeling the gradients with a two-component Laplace mixture prior. Methods: We propose a Laplace-Mixture Dipole Inversion (LAMDI) method by incorporating a two-component Laplace mixture prior into the AMP-PE framework with automatic parameter estimation. LAMDI was evaluated on a public in vivo dataset. Its performance was compared with FANSI, MEDI, and AMP-PE with a single-Laplace prior (AMP-PE-L1) under both standard default and reference-tuned settings. Results: On a public multi-orientation QSM dataset, LAMDI achieved NRMSE and SSIM comparable to AMP-PE-L1 while substantially reducing HFEN, suggesting improved preservation of high-frequency anatomical detail. Under reference-based tuning, FANSI and MEDI achieved the best performance for some metrics, but LAMDI remained competitive without requiring reference maps or manual regularization tuning. Conclusion: LAMDI provides an effective and automatic parameter-estimation alternative for QSM dipole inversion by combining competitive reconstruction accuracy with improved preservation of fine anatomical detail.
A Role-Based LLM Framework for Structured Information Extraction from Healthy Food Policies
Apr 02, 2026Current Large Language Model (LLM) approaches for information extraction (IE) in the healthy food policy domain are often hindered by various factors, including misinformation, specifically hallucinations, misclassifications, and omissions that result from the structural diversity and inconsistency of policy documents. To address these limitations, this study proposes a role-based LLM framework that automates the IE from unstructured policy data by assigning specialized roles: an LLM policy analyst for metadata and mechanism classification, an LLM legal strategy specialist for identifying complex legal approaches, and an LLM food system expert for categorizing food system stages. This framework mimics expert analysis workflows by incorporating structured domain knowledge, including explicit definitions of legal mechanisms and classification criteria, into role-specific prompts. We evaluate the framework using 608 healthy food policies from the Healthy Food Policy Project (HFPP) database, comparing its performance against zero-shot, few-shot, and chain-of-thought (CoT) baselines using Llama-3.3-70B. Our proposed framework demonstrates superior performance in complex reasoning tasks, offering a reliable and transparent methodology for automating IE from health policies.
Causal Learning Should Embrace the Wisdom of the Crowd
Mar 04, 2026Learning causal structures typically represented by directed acyclic graphs (DAGs) from observational data is notoriously challenging due to the combinatorial explosion of possible graphs and inherent ambiguities in observations. This paper argues that causal learning is now ready for the emergence of a new paradigm supported by rapidly advancing technologies, fulfilling the long-standing vision of leveraging human causal knowledge. This paradigm integrates scalable crowdsourcing platforms for data collection, interactive knowledge elicitation for expert opinion modeling, robust aggregation techniques for expert reconciliation, and large language model (LLM)-based simulation for augmenting AI-driven information acquisition. In this paper, we focus on DAG learning for causal discovery and frame the problem as a distributed decision-making task, recognizing that each participant (human expert or LLM agent) possesses fragmented and imperfect knowledge about different subsets of the variables of interest in the causal graph. By proposing a systematic framework to synthesize these insights, we aim to enable the recovery of a global causal structure unachievable by any individual agent alone. We advocate for a new research frontier and outline a comprehensive framework for new research thrusts that range from eliciting, modeling, aggregating, and optimizing human causal knowledge contributions.
LifeBench: A Benchmark for Long-Horizon Multi-Source Memory
Mar 04, 2026Long-term memory is fundamental for personalized agents capable of accumulating knowledge, reasoning over user experiences, and adapting across time. However, existing memory benchmarks primarily target declarative memory, specifically semantic and episodic types, where all information is explicitly presented in dialogues. In contrast, real-world actions are also governed by non-declarative memory, including habitual and procedural types, and need to be inferred from diverse digital traces. To bridge this gap, we introduce Lifebench, which features densely connected, long-horizon event simulation. It pushes AI agents beyond simple recall, requiring the integration of declarative and non-declarative memory reasoning across diverse and temporally extended contexts. Building such a benchmark presents two key challenges: ensuring data quality and scalability. We maintain data quality by employing real-world priors, including anonymized social surveys, map APIs, and holiday-integrated calendars, thus enforcing fidelity, diversity and behavioral rationality within the dataset. Towards scalability, we draw inspiration from cognitive science and structure events according to their partonomic hierarchy; enabling efficient parallel generation while maintaining global coherence. Performance results show that top-tier, state-of-the-art memory systems reach just 55.2\% accuracy, highlighting the inherent difficulty of long-horizon retrieval and multi-source integration within our proposed benchmark. The dataset and data synthesis code are available at https://github.com/1754955896/LifeBench.
Team, Then Trim: An Assembly-Line LLM Framework for High-Quality Tabular Data Generation
Feb 04, 2026While tabular data is fundamental to many real-world machine learning (ML) applications, acquiring high-quality tabular data is usually labor-intensive and expensive. Limited by the scarcity of observations, tabular datasets often exhibit critical deficiencies, such as class imbalance, selection bias, and low fidelity. To address these challenges, building on recent advances in Large Language Models (LLMs), this paper introduces Team-then-Trim (T$^2$), a framework that synthesizes high-quality tabular data through a collaborative team of LLMs, followed by a rigorous three-stage plug-in data quality control (QC) pipeline. In T$^2$, tabular data generation is conceptualized as a manufacturing process: specialized LLMs, guided by domain knowledge, are tasked with generating different data components sequentially, and the resulting products, i.e., the synthetic data, are systematically evaluated across multiple dimensions of QC. Empirical results on both simulated and real-world datasets demonstrate that T$^2$ outperforms state-of-the-art methods in producing high-quality tabular data, highlighting its potential to support downstream models when direct data collection is practically infeasible.
Lagged backward-compatible physics-informed neural networks for unsaturated soil consolidation analysis
Feb 03, 2026This study develops a Lagged Backward-Compatible Physics-Informed Neural Network (LBC-PINN) for simulating and inverting one-dimensional unsaturated soil consolidation under long-term loading. To address the challenges of coupled air and water pressure dissipation across multi-scale time domains, the framework integrates logarithmic time segmentation, lagged compatibility loss enforcement, and segment-wise transfer learning. In forward analysis, the LBC-PINN with recommended segmentation schemes accurately predicts pore air and pore water pressure evolution. Model predictions are validated against finite element method (FEM) results, with mean absolute errors below 1e-2 for time durations up to 1e10 seconds. A simplified segmentation strategy based on the characteristic air-phase dissipation time improves computational efficiency while preserving predictive accuracy. Sensitivity analyses confirm the robustness of the framework across air-to-water permeability ratios ranging from 1e-3 to 1e3.
CASP: Few-Shot Class-Incremental Learning with CLS Token Attention Steering Prompts
Jan 23, 2026Few-shot class-incremental learning (FSCIL) presents a core challenge in continual learning, requiring models to rapidly adapt to new classes with very limited samples while mitigating catastrophic forgetting. Recent prompt-based methods, which integrate pretrained backbones with task-specific prompts, have made notable progress. However, under extreme few-shot incremental settings, the model's ability to transfer and generalize becomes critical, and it is thus essential to leverage pretrained knowledge to learn feature representations that can be shared across future categories during the base session. Inspired by the mechanism of the CLS token, which is similar to human attention and progressively filters out task-irrelevant information, we propose the CLS Token Attention Steering Prompts (CASP). This approach introduces class-shared trainable bias parameters into the query, key, and value projections of the CLS token to explicitly modulate the self-attention weights. To further enhance generalization, we also design an attention perturbation strategy and perform Manifold Token Mixup in the shallow feature space, synthesizing potential new class features to improve generalization and reserve the representation capacity for upcoming tasks. Experiments on the CUB200, CIFAR100, and ImageNet-R datasets demonstrate that CASP outperforms state-of-the-art methods in both standard and fine-grained FSCIL settings without requiring fine-tuning during incremental phases and while significantly reducing the parameter overhead.
HUMANLLM: Benchmarking and Reinforcing LLM Anthropomorphism via Human Cognitive Patterns
Jan 15, 2026Large Language Models (LLMs) have demonstrated remarkable capabilities in reasoning and generation, serving as the foundation for advanced persona simulation and Role-Playing Language Agents (RPLAs). However, achieving authentic alignment with human cognitive and behavioral patterns remains a critical challenge for these agents. We present HUMANLLM, a framework treating psychological patterns as interacting causal forces. We construct 244 patterns from ~12,000 academic papers and synthesize 11,359 scenarios where 2-5 patterns reinforce, conflict, or modulate each other, with multi-turn conversations expressing inner thoughts, actions, and dialogue. Our dual-level checklists evaluate both individual pattern fidelity and emergent multi-pattern dynamics, achieving strong human alignment (r=0.91) while revealing that holistic metrics conflate simulation accuracy with social desirability. HUMANLLM-8B outperforms Qwen3-32B on multi-pattern dynamics despite 4x fewer parameters, demonstrating that authentic anthropomorphism requires cognitive modeling--simulating not just what humans do, but the psychological processes generating those behaviors.
SmartHome-Bench: A Comprehensive Benchmark for Video Anomaly Detection in Smart Homes Using Multi-Modal Large Language Models
Jun 15, 2025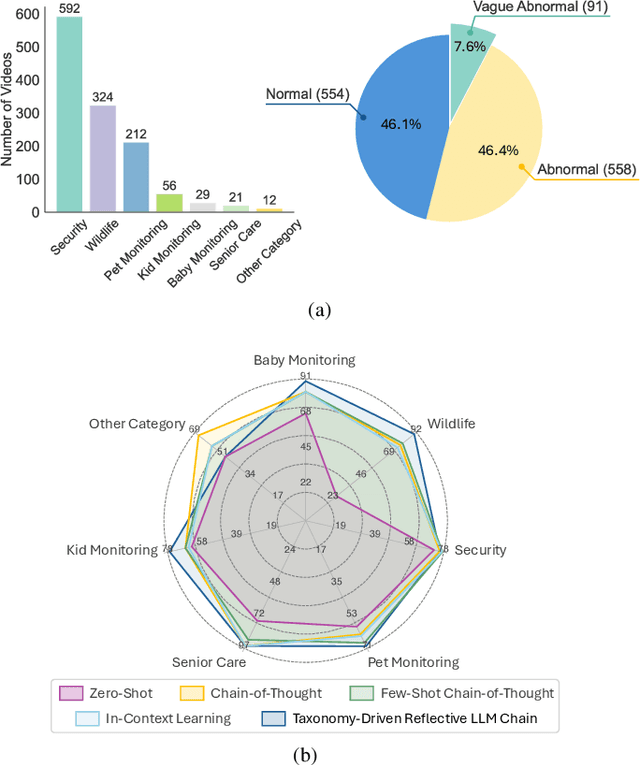
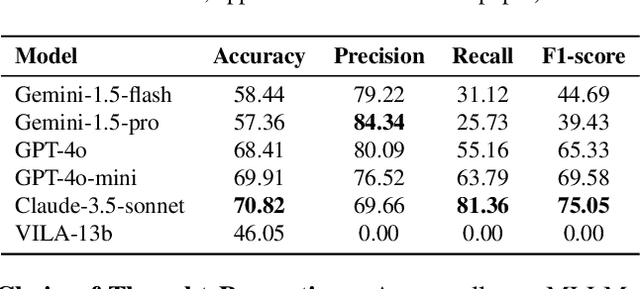

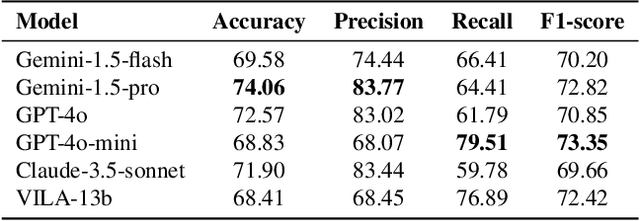
Video anomaly detection (VAD) is essential for enhancing safety and security by identifying unusual events across different environments. Existing VAD benchmarks, however, are primarily designed for general-purpose scenarios, neglecting the specific characteristics of smart home applications. To bridge this gap, we introduce SmartHome-Bench, the first comprehensive benchmark specially designed for evaluating VAD in smart home scenarios, focusing on the capabilities of multi-modal large language models (MLLMs). Our newly proposed benchmark consists of 1,203 videos recorded by smart home cameras, organized according to a novel anomaly taxonomy that includes seven categories, such as Wildlife, Senior Care, and Baby Monitoring. Each video is meticulously annotated with anomaly tags, detailed descriptions, and reasoning. We further investigate adaptation methods for MLLMs in VAD, assessing state-of-the-art closed-source and open-source models with various prompting techniques. Results reveal significant limitations in the current models' ability to detect video anomalies accurately. To address these limitations, we introduce the Taxonomy-Driven Reflective LLM Chain (TRLC), a new LLM chaining framework that achieves a notable 11.62% improvement in detection accuracy. The benchmark dataset and code are publicly available at https://github.com/Xinyi-0724/SmartHome-Bench-LLM.
Improving the Test-retest Reliability of Quantitative Susceptibility Mapping
Nov 15, 2024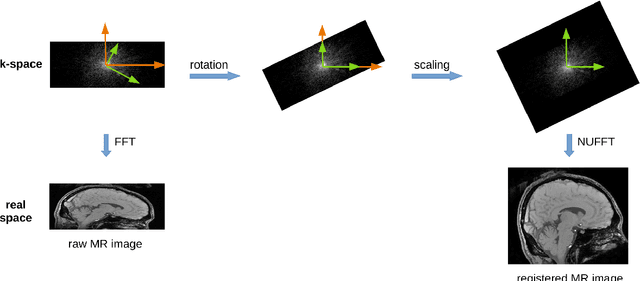
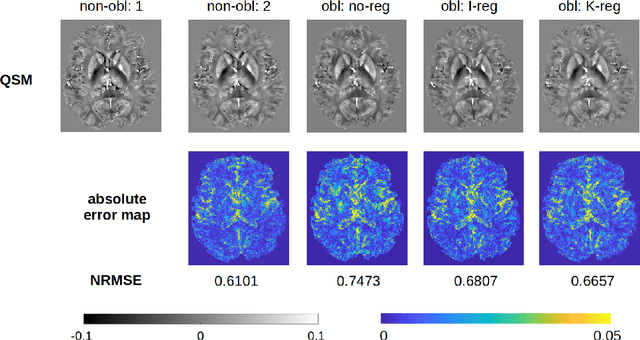
Motivation - The test-retest reliability of quantitative susceptibility mapping (QSM) is affected by parameters of the acquisition protocol such as the angulation of acquisition plane with respect to the B0 field direction and spatial resolution. Goal - We aim to reduce the protocol-dependent biases/errors that might overshadow subtle changes of the susceptibility values due to pathology in the brain. Approach - The magnitude and phase images used for QSM are registered according to a standard reference protocol in the k-space through nonuniform fast Fourier transform (NUFFT). Results - With the help of our proposed approach, the test-retest reliability of scans acquired from different protocols is notably improved. Impact - The improved test-retest reliability of QSM makes it easier to detect subtle susceptibility changes in the early stages of neurodegeneration such as Alzheimer's disease and Parkinson's disease.