 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory-Efficient Continual Learning with CLIP Models
May 05, 2026Contrastive Language-Image Pretraining (CLIP) models excel at understanding image-text relationships but struggle with adapting to new data without forgetting prior knowledge. To address this, models are typically fine-tuned using both new task data and a memory buffer of past tasks. However, CLIP's contrastive loss suffers when the memory buffer is small, leading to performance degradation on previous tasks. We propose a memory-efficient, distributionally robust method that dynamically reweights losses per class during training. Our approach, tested on class incremental settings (CIFAR-100, ImageNet1K) and a domain incremental setting (DomainNet) adapts CLIP models quickly while minimizing catastrophic forgetting, even with minimal memory usage.
Multimodal Pretraining of Medical Time Series and Notes
Dec 11, 2023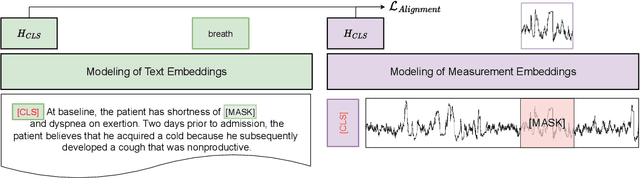



Within the intensive care unit (ICU), a wealth of patient data, including clinical measurements and clinical notes, is readily available. This data is a valuable resource for comprehending patient health and informing medical decisions, but it also contains many challenges in analysis. Deep learning models show promise in extracting meaningful patterns, but they require extensive labeled data, a challenge in critical care. To address this, we propose a novel approach employing self-supervised pretraining, focusing on the alignment of clinical measurements and notes. Our approach combines contrastive and masked token prediction tasks during pretraining. Semi-supervised experiments on the MIMIC-III dataset demonstrate the effectiveness of our self-supervised pretraining. In downstream tasks, including in-hospital mortality prediction and phenotyping, our pretrained model outperforms baselines in settings where only a fraction of the data is labeled, emphasizing its ability to enhance ICU data analysis. Notably, our method excels in situations where very few labels are available, as evidenced by an increase in the AUC-ROC for in-hospital mortality by 0.17 and in AUC-PR for phenotyping by 0.1 when only 1% of labels are accessible. This work advances self-supervised learning in the healthcare domain, optimizing clinical insights from abundant yet challenging ICU data.
DynImp: Dynamic Imputation for Wearable Sensing Data Through Sensory and Temporal Relatedness
Sep 26, 2022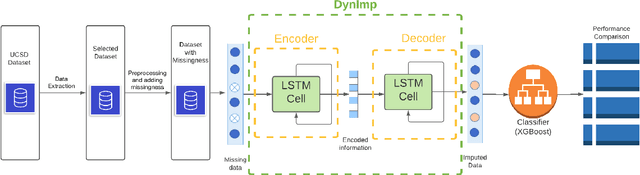

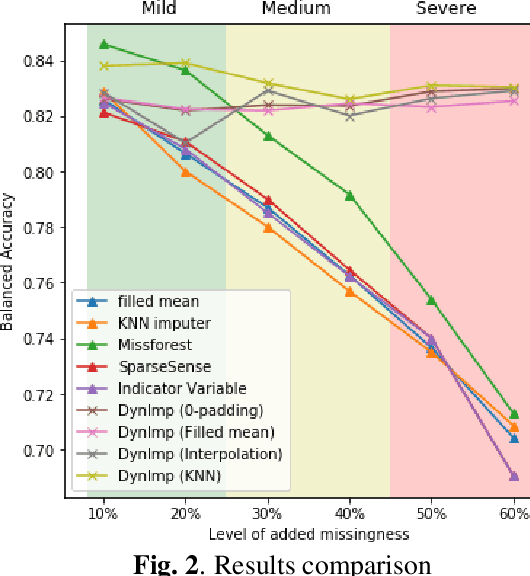
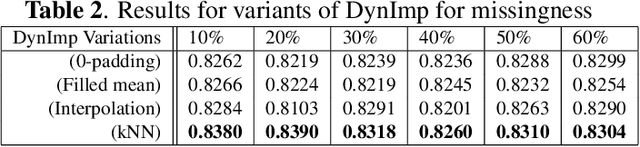
In wearable sensing applications, data is inevitable to be irregularly sampled or partially missing, which pose challenges for any downstream application. An unique aspect of wearable data is that it is time-series data and each channel can be correlated to another one, such as x, y, z axis of accelerometer. We argue that traditional methods have rarely made use of both times-series dynamics of the data as well as the relatedness of the features from different sensors. We propose a model, termed as DynImp, to handle different time point's missingness with nearest neighbors along feature axis and then feeding the data into a LSTM-based denoising autoencoder which can reconstruct missingness along the time axis. We experiment the model on the extreme missingness scenario ($>50\%$ missing rate) which has not been widely tested in wearable data. Our experiments on activity recognition show that the method can exploit the multi-modality features from related sensors and also learn from history time-series dynamics to reconstruct the data under extreme missingness.
Self-Supervised Learning of Echocardiogram Videos Enables Data-Efficient Clinical Diagnosis
Jul 23, 2022



Given the difficulty of obtaining high-quality labels for medical image recognition tasks, there is a need for deep learning techniques that can be adequately fine-tuned on small labeled data sets. Recent advances in self-supervised learning techniques have shown that such an in-domain representation learning approach can provide a strong initialization for supervised fine-tuning, proving much more data-efficient than standard transfer learning from a supervised pretraining task. However, these applications are not adapted to applications to medical diagnostics captured in a video format. With this progress in mind, we developed a self-supervised learning approach catered to echocardiogram videos with the goal of learning strong representations for downstream fine-tuning on the task of diagnosing aortic stenosis (AS), a common and dangerous disease of the aortic valve. When fine-tuned on 1% of the training data, our best self-supervised learning model achieves 0.818 AUC (95% CI: 0.794, 0.840), while the standard transfer learning approach reaches 0.644 AUC (95% CI: 0.610, 0.677). We also find that our self-supervised model attends more closely to the aortic valve when predicting severe AS as demonstrated by saliency map visualizations.
VFDS: Variational Foresight Dynamic Selection in Bayesian Neural Networks for Efficient Human Activity Recognition
Mar 31, 2022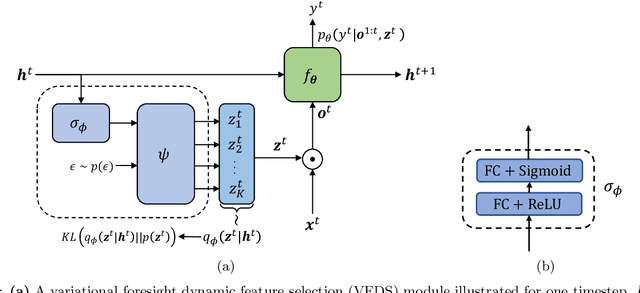
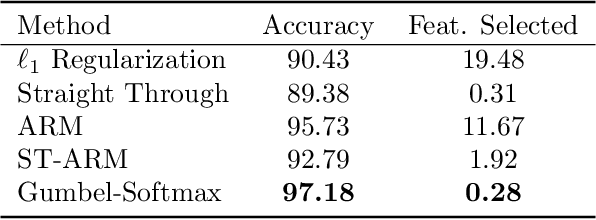
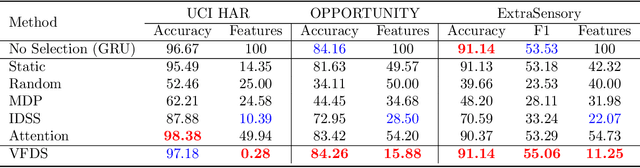
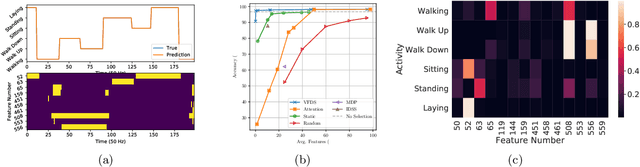
In many machine learning tasks, input features with varying degrees of predictive capability are acquired at varying costs. In order to optimize the performance-cost trade-off, one would select features to observe a priori. However, given the changing context with previous observations, the subset of predictive features to select may change dynamically. Therefore, we face the challenging new problem of foresight dynamic selection (FDS): finding a dynamic and light-weight policy to decide which features to observe next, before actually observing them, for overall performance-cost trade-offs. To tackle FDS, this paper proposes a Bayesian learning framework of Variational Foresight Dynamic Selection (VFDS). VFDS learns a policy that selects the next feature subset to observe, by optimizing a variational Bayesian objective that characterizes the trade-off between model performance and feature cost. At its core is an implicit variational distribution on binary gates that are dependent on previous observations, which will select the next subset of features to observe. We apply VFDS on the Human Activity Recognition (HAR) task where the performance-cost trade-off is critical in its practice. Extensive results demonstrate that VFDS selects different features under changing contexts, notably saving sensory costs while maintaining or improving the HAR accuracy. Moreover, the features that VFDS dynamically select are shown to be interpretable and associated with the different activity types. We will release the code.
Growing Representation Learning
Oct 17, 2021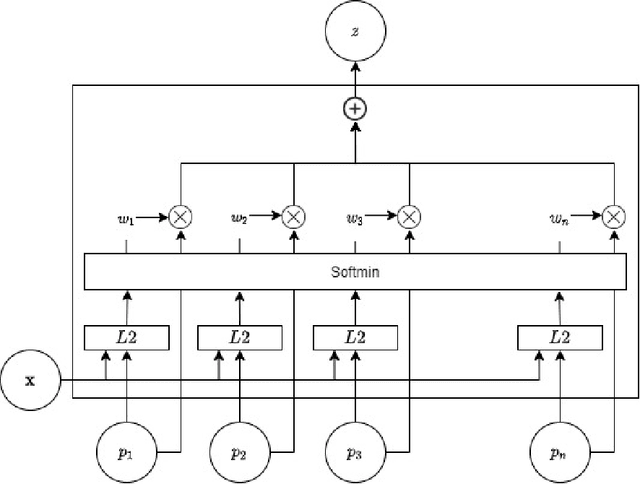

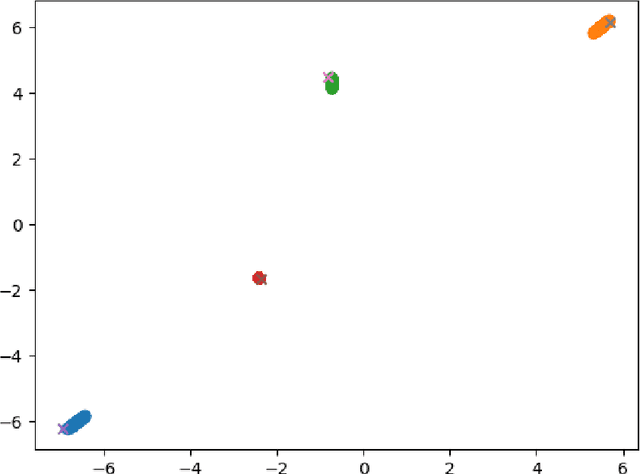
Machine learning continues to grow in popularity due to its ability to learn increasingly complex tasks. However, for many supervised models, the shift in a data distribution or the appearance of a new event can result in a severe decrease in model performance. Retraining a model from scratch with updated data can be resource intensive or impossible depending on the constraints placed on an organization or system. Continual learning methods attempt to adapt models to new classes instead of retraining. However, many of these methods do not have a detection method for new classes or make assumptions about the distribution of classes. In this paper, we develop an attention based Gaussian Mixture, called GMAT, that learns interpretable representations of data with or without labels. We incorporate this method with existing Neural Architecture Search techniques to develop an algorithm for detection new events for an optimal number of representations through an iterative process of training a growing. We show that our method is capable learning new representations of data without labels or assumptions about the distributions of labels. We additionally develop a method that allows our model to utilize labels to more accurately develop representations. Lastly, we show that our method can avoid catastrophic forgetting by replaying samples from learned representations.
Self-Damaging Contrastive Learning
Jun 06, 2021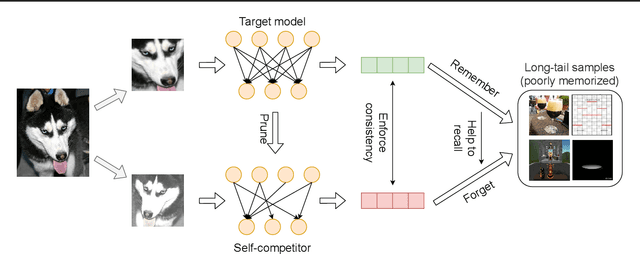

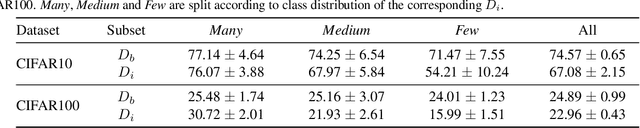
The recent breakthrough achieved by contrastive learning accelerates the pace for deploying unsupervised training on real-world data applications. However, unlabeled data in reality is commonly imbalanced and shows a long-tail distribution, and it is unclear how robustly the latest contrastive learning methods could perform in the practical scenario. This paper proposes to explicitly tackle this challenge, via a principled framework called Self-Damaging Contrastive Learning (SDCLR), to automatically balance the representation learning without knowing the classes. Our main inspiration is drawn from the recent finding that deep models have difficult-to-memorize samples, and those may be exposed through network pruning. It is further natural to hypothesize that long-tail samples are also tougher for the model to learn well due to insufficient examples. Hence, the key innovation in SDCLR is to create a dynamic self-competitor model to contrast with the target model, which is a pruned version of the latter. During training, contrasting the two models will lead to adaptive online mining of the most easily forgotten samples for the current target model, and implicitly emphasize them more in the contrastive loss. Extensive experiments across multiple datasets and imbalance settings show that SDCLR significantly improves not only overall accuracies but also balancedness, in terms of linear evaluation on the full-shot and few-shot settings. Our code is available at: https://github.com/VITA-Group/SDCLR.
Uncertainty Quantification for Deep Context-Aware Mobile Activity Recognition and Unknown Context Discovery
Mar 03, 2020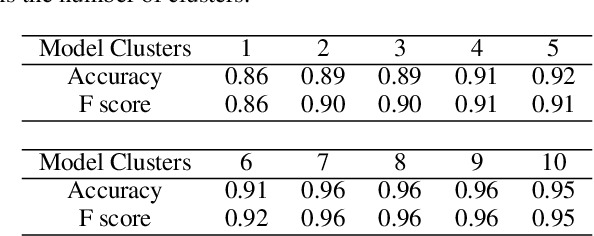
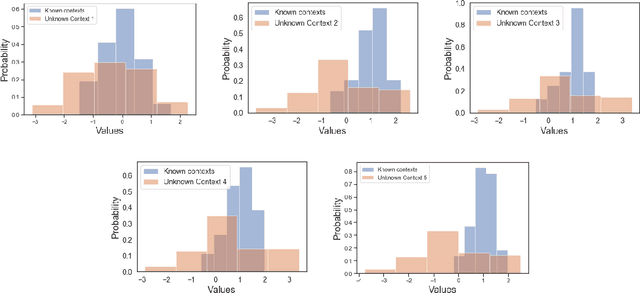
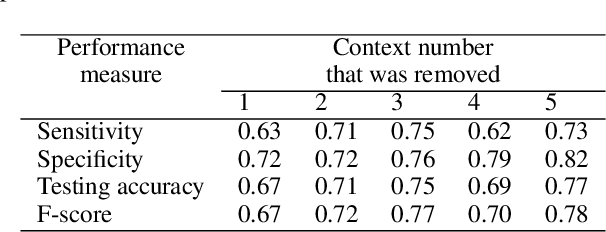
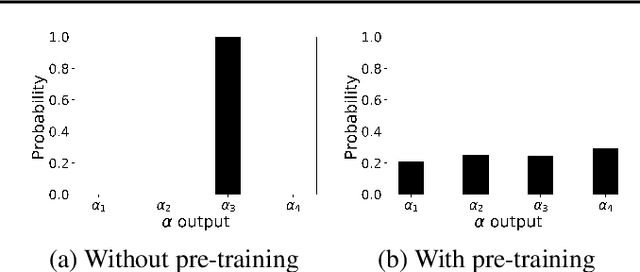
Activity recognition in wearable computing faces two key challenges: i) activity characteristics may be context-dependent and change under different contexts or situations; ii) unknown contexts and activities may occur from time to time, requiring flexibility and adaptability of the algorithm. We develop a context-aware mixture of deep models termed the {\alpha}-\b{eta} network coupled with uncertainty quantification (UQ) based upon maximum entropy to enhance human activity recognition performance. We improve accuracy and F score by 10% by identifying high-level contexts in a data-driven way to guide model development. In order to ensure training stability, we have used a clustering-based pre-training in both public and in-house datasets, demonstrating improved accuracy through unknown context discovery.
Adaptive Activity Monitoring with Uncertainty Quantification in Switching Gaussian Process Models
Jan 08, 2019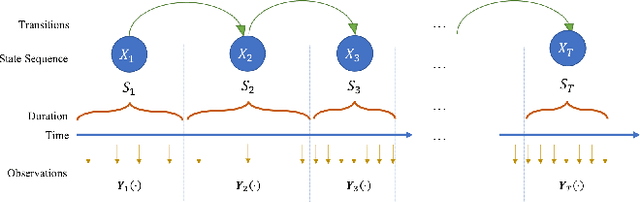

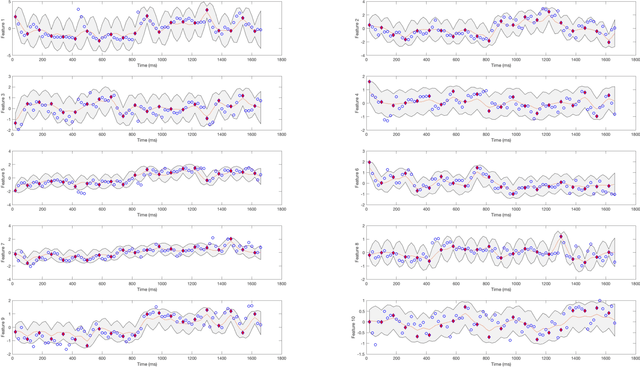
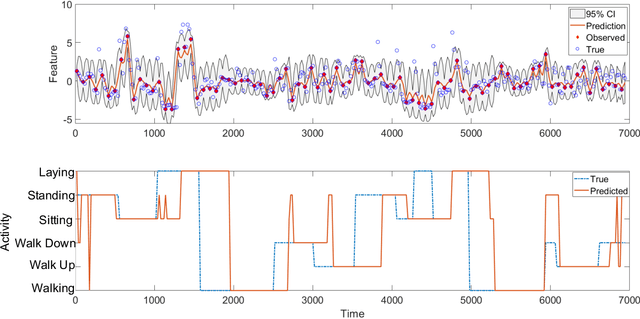
Emerging wearable sensors have enabled the unprecedented ability to continuously monitor human activities for healthcare purposes. However, with so many ambient sensors collecting different measurements, it becomes important not only to maintain good monitoring accuracy, but also low power consumption to ensure sustainable monitoring. This power-efficient sensing scheme can be achieved by deciding which group of sensors to use at a given time, requiring an accurate characterization of the trade-off between sensor energy usage and the uncertainty in ignoring certain sensor signals while monitoring. To address this challenge in the context of activity monitoring, we have designed an adaptive activity monitoring framework. We first propose a switching Gaussian process to model the observed sensor signals emitting from the underlying activity states. To efficiently compute the Gaussian process model likelihood and quantify the context prediction uncertainty, we propose a block circulant embedding technique and use Fast Fourier Transforms (FFT) for inference. By computing the Bayesian loss function tailored to switching Gaussian processes, an adaptive monitoring procedure is developed to select features from available sensors that optimize the trade-off between sensor power consumption and the prediction performance quantified by state prediction entropy. We demonstrate the effectiveness of our framework on the popular benchmark of UCI Human Activity Recognition using Smartphones.