 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Damaging Contrastive Learning
Paper and Code
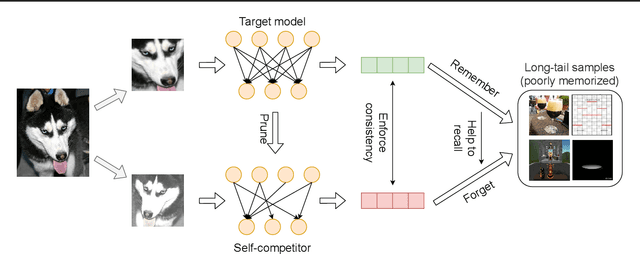

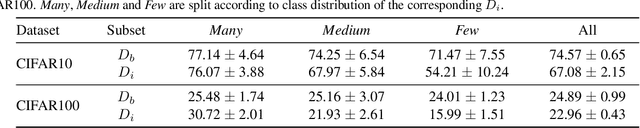
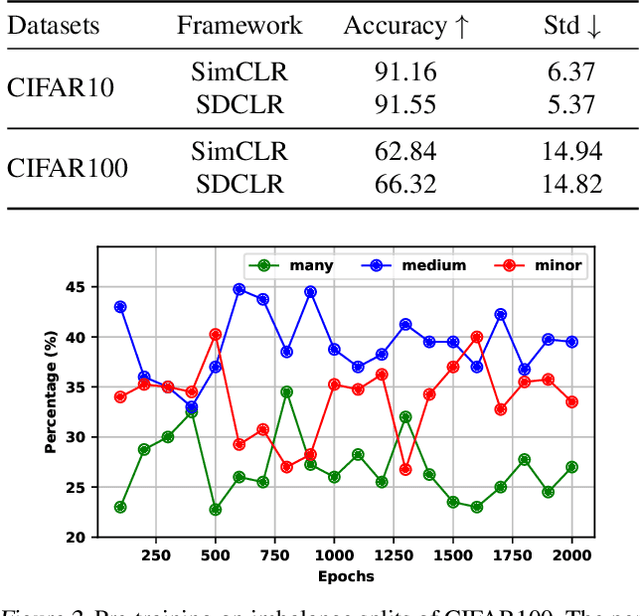
The recent breakthrough achieved by contrastive learning accelerates the pace for deploying unsupervised training on real-world data applications. However, unlabeled data in reality is commonly imbalanced and shows a long-tail distribution, and it is unclear how robustly the latest contrastive learning methods could perform in the practical scenario. This paper proposes to explicitly tackle this challenge, via a principled framework called Self-Damaging Contrastive Learning (SDCLR), to automatically balance the representation learning without knowing the classes. Our main inspiration is drawn from the recent finding that deep models have difficult-to-memorize samples, and those may be exposed through network pruning. It is further natural to hypothesize that long-tail samples are also tougher for the model to learn well due to insufficient examples. Hence, the key innovation in SDCLR is to create a dynamic self-competitor model to contrast with the target model, which is a pruned version of the latter. During training, contrasting the two models will lead to adaptive online mining of the most easily forgotten samples for the current target model, and implicitly emphasize them more in the contrastive loss. Extensive experiments across multiple datasets and imbalance settings show that SDCLR significantly improves not only overall accuracies but also balancedness, in terms of linear evaluation on the full-shot and few-shot settings. Our code is available at: https://github.com/VITA-Group/SDCLR.