 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesCNS: A Unified Bayesian Approach to Address Cold Start and Non-Stationarity in Search Systems at Scale
Oct 03, 2024Information Retrieval (IR) systems used in search and recommendation platforms frequently employ Learning-to-Rank (LTR) models to rank items in response to user queries. These models heavily rely on features derived from user interactions, such as clicks and engagement data. This dependence introduces cold start issues for items lacking user engagement and poses challenges in adapting to non-stationary shifts in user behavior over time. We address both challenges holistically as an online learning problem and propose BayesCNS, a Bayesian approach designed to handle cold start and non-stationary distribution shifts in search systems at scale. BayesCNS achieves this by estimating prior distributions for user-item interactions, which are continuously updated with new user interactions gathered online. This online learning procedure is guided by a ranker model, enabling efficient exploration of relevant items using contextual information provided by the ranker. We successfully deployed BayesCNS in a large-scale search system and demonstrated its efficacy through comprehensive offline and online experiments. Notably, an online A/B experiment showed a 10.60% increase in new item interactions and a 1.05% improvement in overall success metrics over the existing production baseline.
VFDS: Variational Foresight Dynamic Selection in Bayesian Neural Networks for Efficient Human Activity Recognition
Mar 31, 2022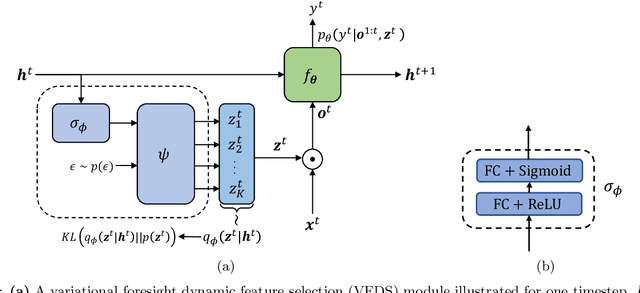
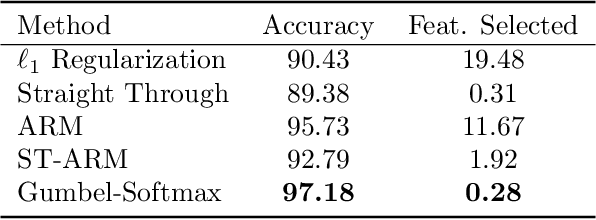
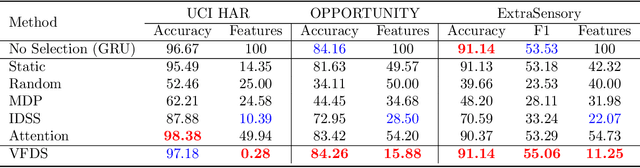
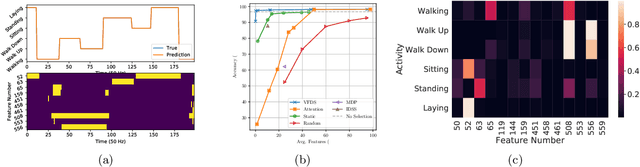
In many machine learning tasks, input features with varying degrees of predictive capability are acquired at varying costs. In order to optimize the performance-cost trade-off, one would select features to observe a priori. However, given the changing context with previous observations, the subset of predictive features to select may change dynamically. Therefore, we face the challenging new problem of foresight dynamic selection (FDS): finding a dynamic and light-weight policy to decide which features to observe next, before actually observing them, for overall performance-cost trade-offs. To tackle FDS, this paper proposes a Bayesian learning framework of Variational Foresight Dynamic Selection (VFDS). VFDS learns a policy that selects the next feature subset to observe, by optimizing a variational Bayesian objective that characterizes the trade-off between model performance and feature cost. At its core is an implicit variational distribution on binary gates that are dependent on previous observations, which will select the next subset of features to observe. We apply VFDS on the Human Activity Recognition (HAR) task where the performance-cost trade-off is critical in its practice. Extensive results demonstrate that VFDS selects different features under changing contexts, notably saving sensory costs while maintaining or improving the HAR accuracy. Moreover, the features that VFDS dynamically select are shown to be interpretable and associated with the different activity types. We will release the code.
NADS: Neural Architecture Distribution Search for Uncertainty Awareness
Jun 11, 2020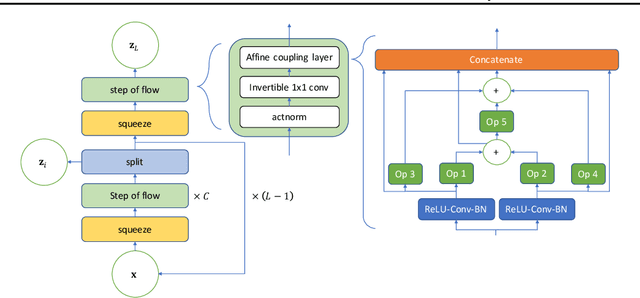

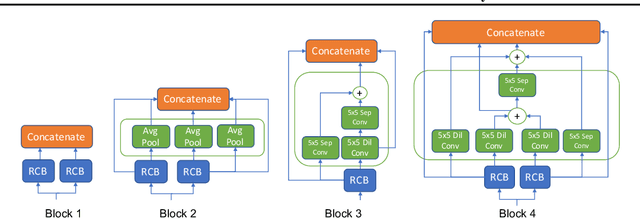
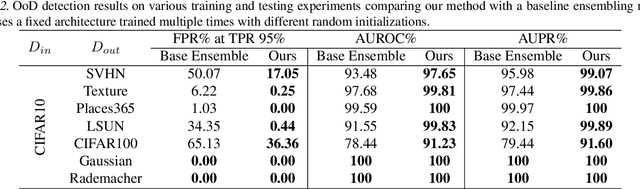
Machine learning (ML) systems often encounter Out-of-Distribution (OoD) errors when dealing with testing data coming from a distribution different from training data. It becomes important for ML systems in critical applications to accurately quantify its predictive uncertainty and screen out these anomalous inputs. However, existing OoD detection approaches are prone to errors and even sometimes assign higher likelihoods to OoD samples. Unlike standard learning tasks, there is currently no well established guiding principle for designing OoD detection architectures that can accurately quantify uncertainty. To address these problems, we first seek to identify guiding principles for designing uncertainty-aware architectures, by proposing Neural Architecture Distribution Search (NADS). NADS searches for a distribution of architectures that perform well on a given task, allowing us to identify common building blocks among all uncertainty-aware architectures. With this formulation, we are able to optimize a stochastic OoD detection objective and construct an ensemble of models to perform OoD detection. We perform multiple OoD detection experiments and observe that our NADS performs favorably, with up to 57% improvement in accuracy compared to state-of-the-art methods among 15 different testing configurations.
Learnable Bernoulli Dropout for Bayesian Deep Learning
Feb 12, 2020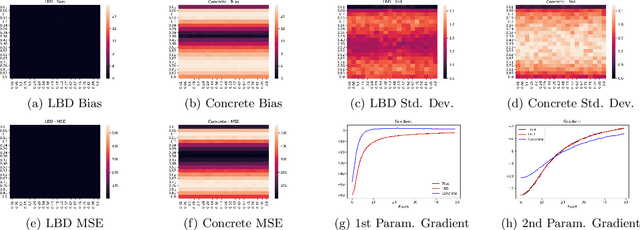
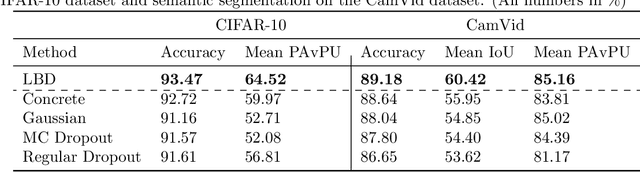
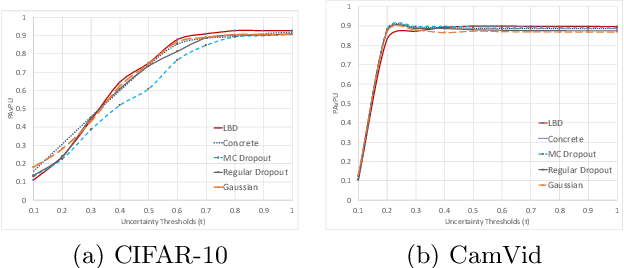
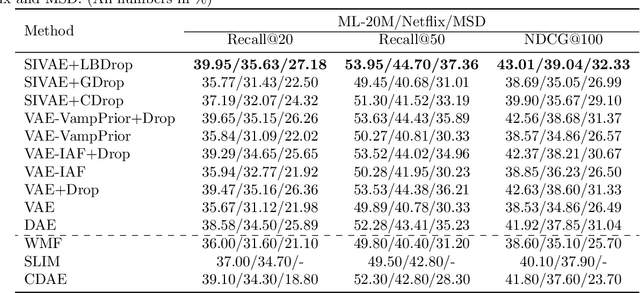
In this work, we propose learnable Bernoulli dropout (LBD), a new model-agnostic dropout scheme that considers the dropout rates as parameters jointly optimized with other model parameters. By probabilistic modeling of Bernoulli dropout, our method enables more robust prediction and uncertainty quantification in deep models. Especially, when combined with variational auto-encoders (VAEs), LBD enables flexible semi-implicit posterior representations, leading to new semi-implicit VAE~(SIVAE) models. We solve the optimization for training with respect to the dropout parameters using Augment-REINFORCE-Merge (ARM), an unbiased and low-variance gradient estimator. Our experiments on a range of tasks show the superior performance of our approach compared with other commonly used dropout schemes. Overall, LBD leads to improved accuracy and uncertainty estimates in image classification and semantic segmentation. Moreover, using SIVAE, we can achieve state-of-the-art performance on collaborative filtering for implicit feedback on several public datasets.
Adaptive Activity Monitoring with Uncertainty Quantification in Switching Gaussian Process Models
Jan 08, 2019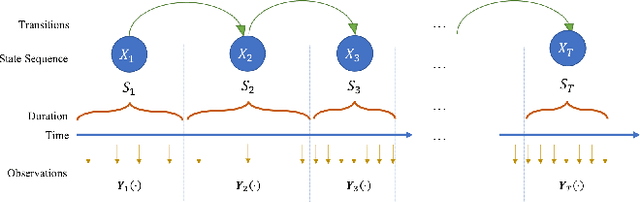

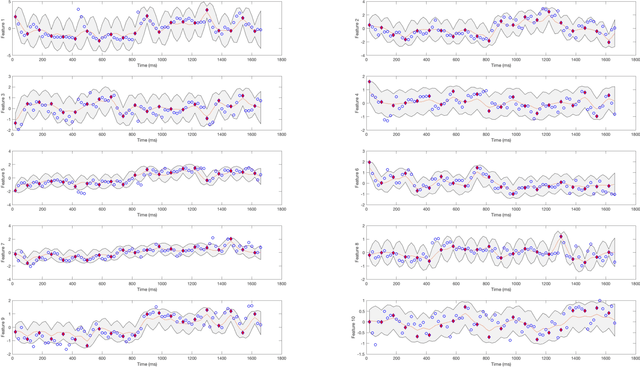
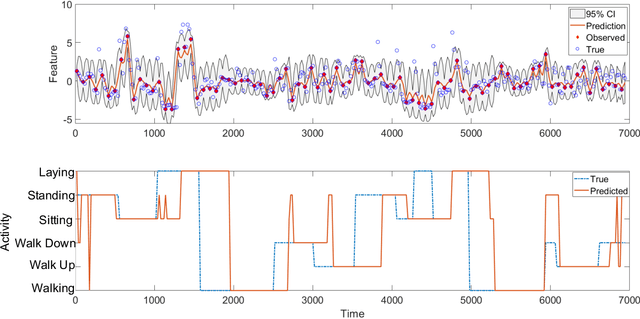
Emerging wearable sensors have enabled the unprecedented ability to continuously monitor human activities for healthcare purposes. However, with so many ambient sensors collecting different measurements, it becomes important not only to maintain good monitoring accuracy, but also low power consumption to ensure sustainable monitoring. This power-efficient sensing scheme can be achieved by deciding which group of sensors to use at a given time, requiring an accurate characterization of the trade-off between sensor energy usage and the uncertainty in ignoring certain sensor signals while monitoring. To address this challenge in the context of activity monitoring, we have designed an adaptive activity monitoring framework. We first propose a switching Gaussian process to model the observed sensor signals emitting from the underlying activity states. To efficiently compute the Gaussian process model likelihood and quantify the context prediction uncertainty, we propose a block circulant embedding technique and use Fast Fourier Transforms (FFT) for inference. By computing the Bayesian loss function tailored to switching Gaussian processes, an adaptive monitoring procedure is developed to select features from available sensors that optimize the trade-off between sensor power consumption and the prediction performance quantified by state prediction entropy. We demonstrate the effectiveness of our framework on the popular benchmark of UCI Human Activity Recognition using Smartphones.