 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCENT: Robust Spatiotemporal Learning for Continuous Scientific Data via Scalable Conditioned Neural Fields
Apr 16, 2025Spatiotemporal learning is challenging due to the intricate interplay between spatial and temporal dependencies, the high dimensionality of the data, and scalability constraints. These challenges are further amplified in scientific domains, where data is often irregularly distributed (e.g., missing values from sensor failures) and high-volume (e.g., high-fidelity simulations), posing additional computational and modeling difficulties. In this paper, we present SCENT, a novel framework for scalable and continuity-informed spatiotemporal representation learning. SCENT unifies interpolation, reconstruction, and forecasting within a single architecture. Built on a transformer-based encoder-processor-decoder backbone, SCENT introduces learnable queries to enhance generalization and a query-wise cross-attention mechanism to effectively capture multi-scale dependencies. To ensure scalability in both data size and model complexity, we incorporate a sparse attention mechanism, enabling flexible output representations and efficient evaluation at arbitrary resolutions. We validate SCENT through extensive simulations and real-world experiments, demonstrating state-of-the-art performance across multiple challenging tasks while achieving superior scalability.
Rankitect: Ranking Architecture Search Battling World-class Engineers at Meta Scale
Nov 14, 2023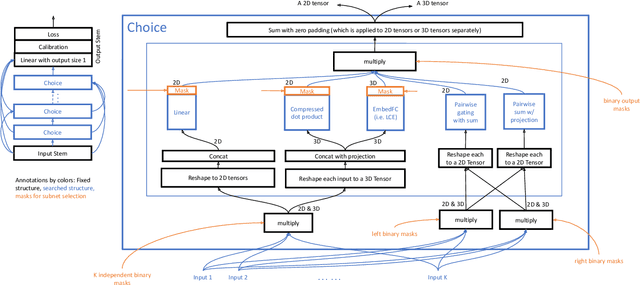
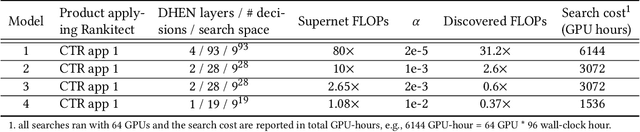
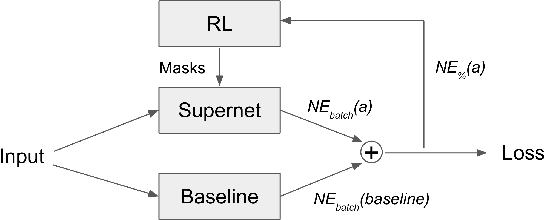
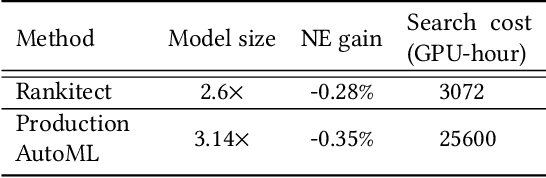
Neural Architecture Search (NAS) has demonstrated its efficacy in computer vision and potential for ranking systems. However, prior work focused on academic problems, which are evaluated at small scale under well-controlled fixed baselines. In industry system, such as ranking system in Meta, it is unclear whether NAS algorithms from the literature can outperform production baselines because of: (1) scale - Meta ranking systems serve billions of users, (2) strong baselines - the baselines are production models optimized by hundreds to thousands of world-class engineers for years since the rise of deep learning, (3) dynamic baselines - engineers may have established new and stronger baselines during NAS search, and (4) efficiency - the search pipeline must yield results quickly in alignment with the productionization life cycle. In this paper, we present Rankitect, a NAS software framework for ranking systems at Meta. Rankitect seeks to build brand new architectures by composing low level building blocks from scratch. Rankitect implements and improves state-of-the-art (SOTA) NAS methods for comprehensive and fair comparison under the same search space, including sampling-based NAS, one-shot NAS, and Differentiable NAS (DNAS). We evaluate Rankitect by comparing to multiple production ranking models at Meta. We find that Rankitect can discover new models from scratch achieving competitive tradeoff between Normalized Entropy loss and FLOPs. When utilizing search space designed by engineers, Rankitect can generate better models than engineers, achieving positive offline evaluation and online A/B test at Meta scale.
Adaptive Activity Monitoring with Uncertainty Quantification in Switching Gaussian Process Models
Jan 08, 2019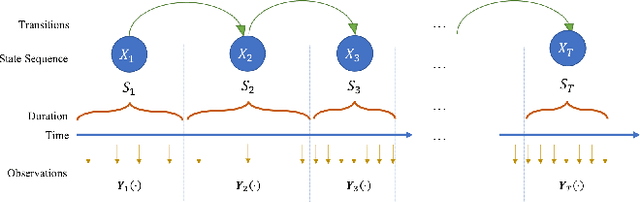

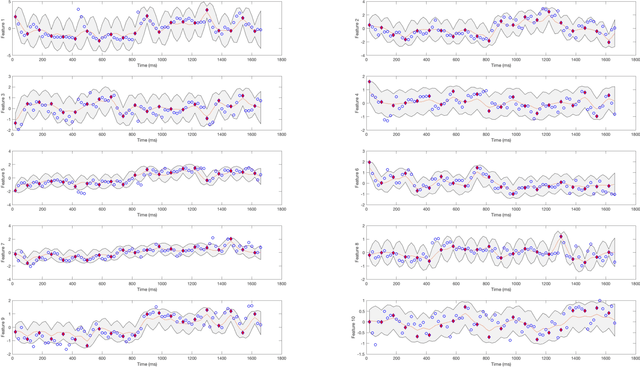
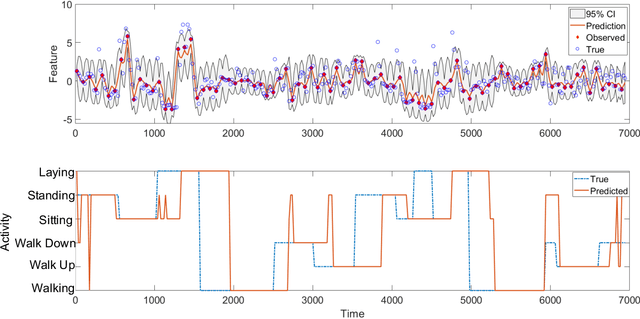
Emerging wearable sensors have enabled the unprecedented ability to continuously monitor human activities for healthcare purposes. However, with so many ambient sensors collecting different measurements, it becomes important not only to maintain good monitoring accuracy, but also low power consumption to ensure sustainable monitoring. This power-efficient sensing scheme can be achieved by deciding which group of sensors to use at a given time, requiring an accurate characterization of the trade-off between sensor energy usage and the uncertainty in ignoring certain sensor signals while monitoring. To address this challenge in the context of activity monitoring, we have designed an adaptive activity monitoring framework. We first propose a switching Gaussian process to model the observed sensor signals emitting from the underlying activity states. To efficiently compute the Gaussian process model likelihood and quantify the context prediction uncertainty, we propose a block circulant embedding technique and use Fast Fourier Transforms (FFT) for inference. By computing the Bayesian loss function tailored to switching Gaussian processes, an adaptive monitoring procedure is developed to select features from available sensors that optimize the trade-off between sensor power consumption and the prediction performance quantified by state prediction entropy. We demonstrate the effectiveness of our framework on the popular benchmark of UCI Human Activity Recognition using Smartphones.
Fast Exact Computation of Expected HyperVolume Improvement
Dec 18, 2018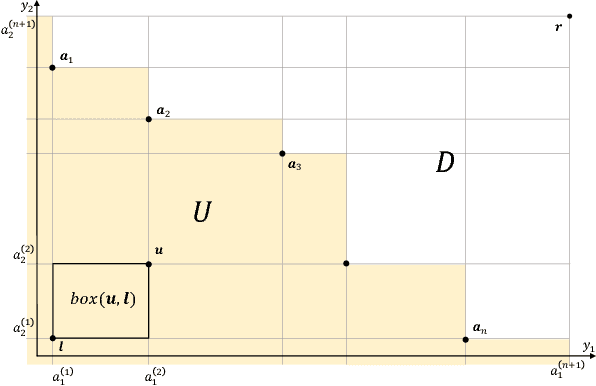
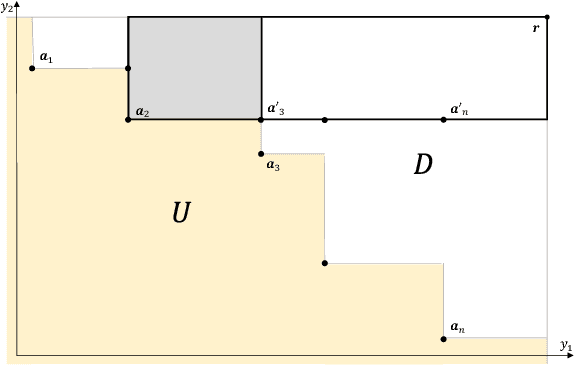
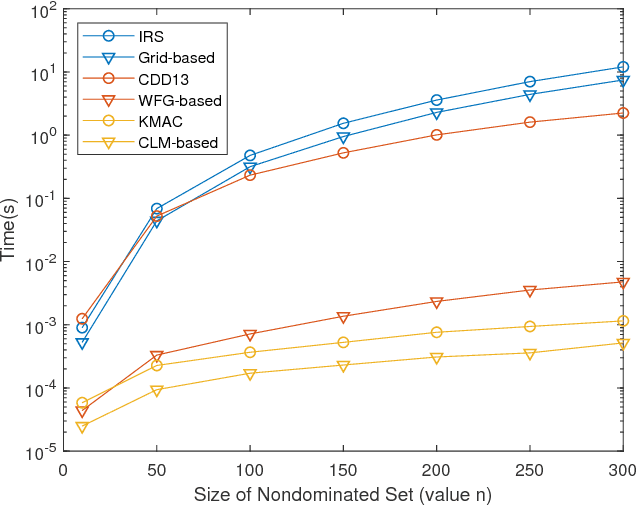
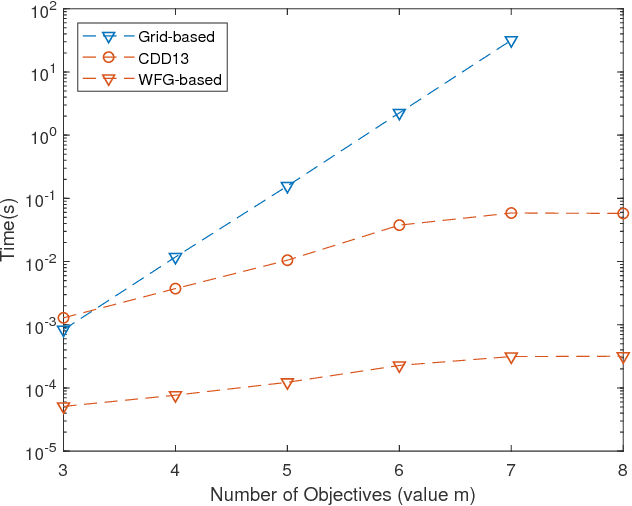
In multi-objective Bayesian optimization and surrogate-based evolutionary algorithms, Expected HyperVolume Improvement (EHVI) is widely used as the acquisition function to guide the search approaching the Pareto front. This paper focuses on the exact calculation of EHVI given a nondominated set, for which the existing exact algorithms are complex and can be inefficient for problems with more than three objectives. Integrating with different decomposition algorithms, we propose a new method for calculating the integral in each decomposed high-dimensional box in constant time. We develop three new exact EHVI calculation algorithms based on three region decomposition methods. The first grid-based algorithm has a complexity of $O(m\cdot n^m)$ with $n$ denoting the size of the nondominated set and $m$ the number of objectives. The Walking Fish Group (WFG)-based algorithm has a worst-case complexity of $O(m\cdot 2^n)$ but has a better average performance. These two can be applied for problems with any $m$. The third CLM-based algorithm is only for $m=3$ and asymptotically optimal with complexity $\Theta(n\log{n})$. Performance comparison results show that all our three algorithms are at least twice faster than the state-of-the-art algorithms with the same decomposition methods. When $m>3$, our WFG-based algorithm can be over $10^2$ faster than the corresponding existing algorithms. Our algorithm is demonstrated in an example involving efficient multi-objective material design with Bayesian optimization.