 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTACI: Spatio-Temporal Aleatoric Conformal Inference
May 27, 2025Fitting Gaussian Processes (GPs) provides interpretable aleatoric uncertainty quantification for estimation of spatio-temporal fields. Spatio-temporal deep learning models, while scalable, typically assume a simplistic independent covariance matrix for the response, failing to capture the underlying correlation structure. However, spatio-temporal GPs suffer from issues of scalability and various forms of approximation bias resulting from restrictive assumptions of the covariance kernel function. We propose STACI, a novel framework consisting of a variational Bayesian neural network approximation of non-stationary spatio-temporal GP along with a novel spatio-temporal conformal inference algorithm. STACI is highly scalable, taking advantage of GPU training capabilities for neural network models, and provides statistically valid prediction intervals for uncertainty quantification. STACI outperforms competing GPs and deep methods in accurately approximating spatio-temporal processes and we show it easily scales to datasets with millions of observations.
SCENT: Robust Spatiotemporal Learning for Continuous Scientific Data via Scalable Conditioned Neural Fields
Apr 16, 2025Spatiotemporal learning is challenging due to the intricate interplay between spatial and temporal dependencies, the high dimensionality of the data, and scalability constraints. These challenges are further amplified in scientific domains, where data is often irregularly distributed (e.g., missing values from sensor failures) and high-volume (e.g., high-fidelity simulations), posing additional computational and modeling difficulties. In this paper, we present SCENT, a novel framework for scalable and continuity-informed spatiotemporal representation learning. SCENT unifies interpolation, reconstruction, and forecasting within a single architecture. Built on a transformer-based encoder-processor-decoder backbone, SCENT introduces learnable queries to enhance generalization and a query-wise cross-attention mechanism to effectively capture multi-scale dependencies. To ensure scalability in both data size and model complexity, we incorporate a sparse attention mechanism, enabling flexible output representations and efficient evaluation at arbitrary resolutions. We validate SCENT through extensive simulations and real-world experiments, demonstrating state-of-the-art performance across multiple challenging tasks while achieving superior scalability.
Explorable INR: An Implicit Neural Representation for Ensemble Simulation Enabling Efficient Spatial and Parameter Exploration
Apr 01, 2025With the growing computational power available for high-resolution ensemble simulations in scientific fields such as cosmology and oceanology, storage and computational demands present significant challenges. Current surrogate models fall short in the flexibility of point- or region-based predictions as the entire field reconstruction is required for each parameter setting, hence hindering the efficiency of parameter space exploration. Limitations exist in capturing physical attribute distributions and pinpointing optimal parameter configurations. In this work, we propose Explorable INR, a novel implicit neural representation-based surrogate model, designed to facilitate exploration and allow point-based spatial queries without computing full-scale field data. In addition, to further address computational bottlenecks of spatial exploration, we utilize probabilistic affine forms (PAFs) for uncertainty propagation through Explorable INR to obtain statistical summaries, facilitating various ensemble analysis and visualization tasks that are expensive with existing models. Furthermore, we reformulate the parameter exploration problem as optimization tasks using gradient descent and KL divergence minimization that ensures scalability. We demonstrate that the Explorable INR with the proposed approach for spatial and parameter exploration can significantly reduce computation and memory costs while providing effective ensemble analysis.
GST-UNet: Spatiotemporal Causal Inference with Time-Varying Confounders
Feb 07, 2025Estimating causal effects from spatiotemporal data is a key challenge in fields such as public health, social policy, and environmental science, where controlled experiments are often infeasible. However, existing causal inference methods relying on observational data face significant limitations: they depend on strong structural assumptions to address spatiotemporal challenges $\unicode{x2013}$ such as interference, spatial confounding, and temporal carryover effects $\unicode{x2013}$ or fail to account for $\textit{time-varying confounders}$. These confounders, influenced by past treatments and outcomes, can themselves shape future treatments and outcomes, creating feedback loops that complicate traditional adjustment strategies. To address these challenges, we introduce the $\textbf{GST-UNet}$ ($\textbf{G}$-computation $\textbf{S}$patio-$\textbf{T}$emporal $\textbf{UNet}$), a novel end-to-end neural network framework designed to estimate treatment effects in complex spatial and temporal settings. The GST-UNet leverages regression-based iterative G-computation to explicitly adjust for time-varying confounders, providing valid estimates of potential outcomes and treatment effects. To the best of our knowledge, the GST-UNet is the first neural model to account for complex, non-linear dynamics and time-varying confounders in spatiotemporal interventions. We demonstrate the effectiveness of the GST-UNet through extensive simulation studies and showcase its practical utility with a real-world analysis of the impact of wildfire smoke on respiratory hospitalizations during the 2018 California Camp Fire. Our results highlight the potential of GST-UNet to advance spatiotemporal causal inference across a wide range of policy-driven and scientific applications.
Evidential Deep Learning for Probabilistic Modelling of Extreme Storm Events
Dec 18, 2024



Uncertainty quantification (UQ) methods play an important role in reducing errors in weather forecasting. Conventional approaches in UQ for weather forecasting rely on generating an ensemble of forecasts from physics-based simulations to estimate the uncertainty. However, it is computationally expensive to generate many forecasts to predict real-time extreme weather events. Evidential Deep Learning (EDL) is an uncertainty-aware deep learning approach designed to provide confidence about its predictions using only one forecast. It treats learning as an evidence acquisition process where more evidence is interpreted as increased predictive confidence. We apply EDL to storm forecasting using real-world weather datasets and compare its performance with traditional methods. Our findings indicate that EDL not only reduces computational overhead but also enhances predictive uncertainty. This method opens up novel opportunities in research areas such as climate risk assessment, where quantifying the uncertainty about future climate is crucial.
Efficient Compression of Sparse Accelerator Data Using Implicit Neural Representations and Importance Sampling
Dec 02, 2024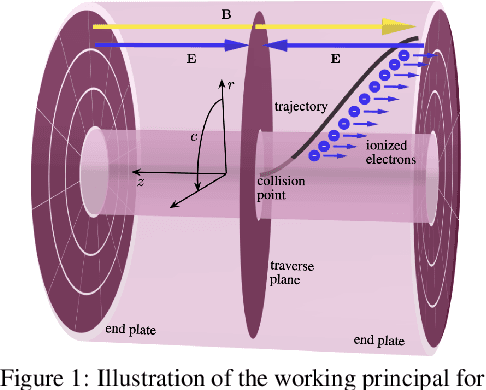
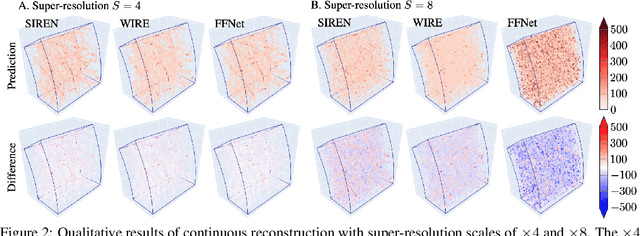
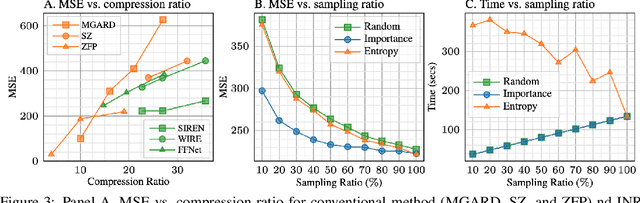
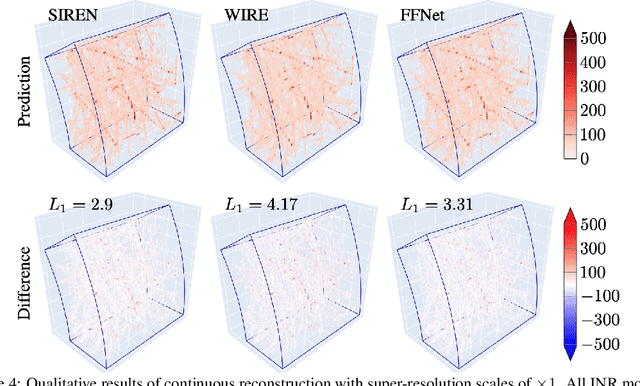
High-energy, large-scale particle colliders in nuclear and high-energy physics generate data at extraordinary rates, reaching up to $1$ terabyte and several petabytes per second, respectively. The development of real-time, high-throughput data compression algorithms capable of reducing this data to manageable sizes for permanent storage is of paramount importance. A unique characteristic of the tracking detector data is the extreme sparsity of particle trajectories in space, with an occupancy rate ranging from approximately $10^{-6}$ to $10\%$. Furthermore, for downstream tasks, a continuous representation of this data is often more useful than a voxel-based, discrete representation due to the inherently continuous nature of the signals involved. To address these challenges, we propose a novel approach using implicit neural representations for data learning and compression. We also introduce an importance sampling technique to accelerate the network training process. Our method is competitive with traditional compression algorithms, such as MGARD, SZ, and ZFP, while offering significant speed-ups and maintaining negligible accuracy loss through our importance sampling strategy.
Variable Rate Neural Compression for Sparse Detector Data
Nov 18, 2024High-energy large-scale particle colliders generate data at extraordinary rates. Developing real-time high-throughput data compression algorithms to reduce data volume and meet the bandwidth requirement for storage has become increasingly critical. Deep learning is a promising technology that can address this challenging topic. At the newly constructed sPHENIX experiment at the Relativistic Heavy Ion Collider, a Time Projection Chamber (TPC) serves as the main tracking detector, which records three-dimensional particle trajectories in a volume of a gas-filled cylinder. In terms of occupancy, the resulting data flow can be very sparse reaching $10^{-3}$ for proton-proton collisions. Such sparsity presents a challenge to conventional learning-free lossy compression algorithms, such as SZ, ZFP, and MGARD. In contrast, emerging deep learning-based models, particularly those utilizing convolutional neural networks for compression, have outperformed these conventional methods in terms of compression ratios and reconstruction accuracy. However, research on the efficacy of these deep learning models in handling sparse datasets, like those produced in particle colliders, remains limited. Furthermore, most deep learning models do not adapt their processing speeds to data sparsity, which affects efficiency. To address this issue, we propose a novel approach for TPC data compression via key-point identification facilitated by sparse convolution. Our proposed algorithm, BCAE-VS, achieves a $75\%$ improvement in reconstruction accuracy with a $10\%$ increase in compression ratio over the previous state-of-the-art model. Additionally, BCAE-VS manages to achieve these results with a model size over two orders of magnitude smaller. Lastly, we have experimentally verified that as sparsity increases, so does the model's throughput.
Hierarchical Neural Operator Transformer with Learnable Frequency-aware Loss Prior for Arbitrary-scale Super-resolution
May 20, 2024



In this work, we present an arbitrary-scale super-resolution (SR) method to enhance the resolution of scientific data, which often involves complex challenges such as continuity, multi-scale physics, and the intricacies of high-frequency signals. Grounded in operator learning, the proposed method is resolution-invariant. The core of our model is a hierarchical neural operator that leverages a Galerkin-type self-attention mechanism, enabling efficient learning of mappings between function spaces. Sinc filters are used to facilitate the information transfer across different levels in the hierarchy, thereby ensuring representation equivalence in the proposed neural operator. Additionally, we introduce a learnable prior structure that is derived from the spectral resizing of the input data. This loss prior is model-agnostic and is designed to dynamically adjust the weighting of pixel contributions, thereby balancing gradients effectively across the model. We conduct extensive experiments on diverse datasets from different domains and demonstrate consistent improvements compared to strong baselines, which consist of various state-of-the-art SR methods.
Studying the Impact of Latent Representations in Implicit Neural Networks for Scientific Continuous Field Reconstruction
Apr 09, 2024



Learning a continuous and reliable representation of physical fields from sparse sampling is challenging and it affects diverse scientific disciplines. In a recent work, we present a novel model called MMGN (Multiplicative and Modulated Gabor Network) with implicit neural networks. In this work, we design additional studies leveraging explainability methods to complement the previous experiments and further enhance the understanding of latent representations generated by the model. The adopted methods are general enough to be leveraged for any latent space inspection. Preliminary results demonstrate the contextual information incorporated in the latent representations and their impact on the model performance. As a work in progress, we will continue to verify our findings and develop novel explainability approaches.
Multi-modal Representation Learning for Cross-modal Prediction of Continuous Weather Patterns from Discrete Low-Dimensional Data
Jan 30, 2024World is looking for clean and renewable energy sources that do not pollute the environment, in an attempt to reduce greenhouse gas emissions that contribute to global warming. Wind energy has significant potential to not only reduce greenhouse emission, but also meet the ever increasing demand for energy. To enable the effective utilization of wind energy, addressing the following three challenges in wind data analysis is crucial. Firstly, improving data resolution in various climate conditions to ensure an ample supply of information for assessing potential energy resources. Secondly, implementing dimensionality reduction techniques for data collected from sensors/simulations to efficiently manage and store large datasets. Thirdly, extrapolating wind data from one spatial specification to another, particularly in cases where data acquisition may be impractical or costly. We propose a deep learning based approach to achieve multi-modal continuous resolution wind data prediction from discontinuous wind data, along with data dimensionality reduction.